







 本文介绍了 PrefixSpan 算法在序列模式挖掘中的作用,详细解析了序列模式的概念、事务数据库实例、前缀和后缀的概念,以及算法的具体步骤,并通过示例展示了如何运用 PrefixSpan 发现频繁序列模式。
本文介绍了 PrefixSpan 算法在序列模式挖掘中的作用,详细解析了序列模式的概念、事务数据库实例、前缀和后缀的概念,以及算法的具体步骤,并通过示例展示了如何运用 PrefixSpan 发现频繁序列模式。
一、序列模式挖掘简介
序列模式的概念最早是由Agrawal和Srikant 提出的。
动机:大型连锁超市的交易数据有一系列的用户事务数据库,每一条记录包括用户的ID,事务发生的时间和事务涉及的项目。
如果能在其中挖掘涉及事务间关联关系的模式,即用户几次购买行为间的联系,可以采取更有针对性的营销措施。
二、事务数据库实例
例:一个事务数据库,一个事务代表一笔交易,一个单项代表交易的商品,单项属性中的数字记录的是商品ID
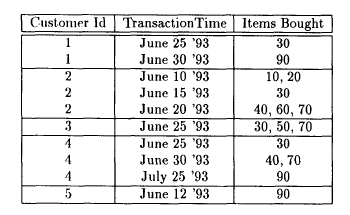
一般为了方便处理,需要把数据库转化为序列数据库。方法是把用户ID相同的记录合并,
有时每个事务的发生时间可以忽略,仅保持事务间的偏序关系。

三、prefixspan
前缀
假设所有的项在一个元素中按照字母表的顺序排列出来。给定一个序列α=<e1e2…en>
(在这里每一个e都和在S中给定的连续的元素相一致)和一个序列β=<e1’e2’…em’>(m≤n).只有如果:
1、ei’=ei(i≤m-1),2、em’∈em ,3、所有在(em—em’)的连续项在em’中都是按照字母表顺序排列的,
那么我们就说β是α的一个前缀。
例如:<a>,<aa>,<a(ab)>和<a(abc)>都是序列s=<a(abc)(ac)d(cf)>的前缀,但是如果每个项都在S中的序列s是连续的,
那么<ab>和<a(bc)>都认为是<a(abc)>的一个前缀。
后缀
序列α关于子序列β = <e1e2… em-1em’>的投影为α’ = <e1e2… en> (n >= m),则序列α关于子序列β的后缀为<em”em+1… en>,
其中em” = (em - em’)。
例如:对于序列s=<a(abc)(ac)d(cf)>,<(abc)(ac)d(cf)>就被认识为是关于前缀<a>的后缀,
<(-bc)(ac)d(cf)>就被认为是关于前缀<aa>的后缀,<(-c)(ac)d(cf)>就被被认为是关于前缀<a(ab)>的后缀。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7052
7052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









