







AdaBoost 算法介绍
AdaBoost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),
然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
AdaBoost算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,
以及上次的总体分类的准确率,来修改每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,
最后将每次得到的分类器最后融合起来,作为最后的决策分类器。
Adaboost 算法步骤
输入:(X1,Y1),(X2,Y2),…(Xn,Yn) Xi∈X (样本),Yi∈Y(分类)={+1,-1},
弱学习算法,M为训练的最大循环次数;
初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权重:1/N。
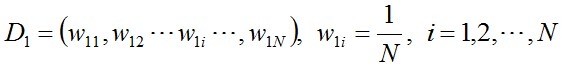
使用具有权值分布Dm的训练数据集学习,确定阈值,得到基本分类器
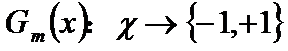
计算Gm(x)在训练数据集上的分类误差率
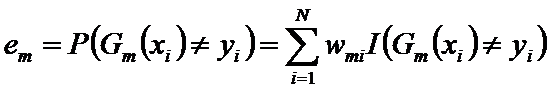
计算Gm(x)的系数

更新训练数据集的权值分布

这里,Zm是规范化因子
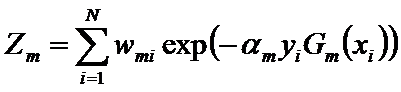
它使Dm+1成为一个概率分布
构建基本分类器的线性组合
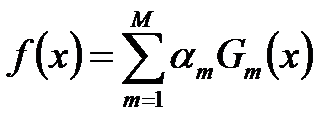
经过M次循环后得到得到最终分类器
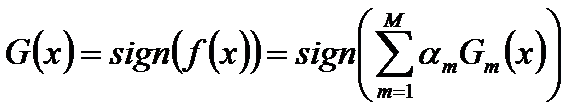

















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









