






来源:九大服务架构性能优化方式
目录
最近做了一些服务性能优化,文章池服务平均耗时跟p99耗时都下降80%左右,事件底层页服务平均耗时下降50%多左右,主要优化项目中一些不合理设计,例如服务间使用json传输数据,监控上报处理逻辑在主流程中,重复数据每次都请求下游服务,多个耗时操作串行请求等,这些问题都对服务有着严重的性能影响。
在服务架构设计时通常可以使用一些中间件去提升服务性能,例如使用mysql,redis,kafka等,因为这些中间件有着很好的读写性能。除了使用中间件提升服务性能外,也可以通过探索它们通过什么样的底层设计实现的高性能,将这些设计应用到我们的服务架构中。
常用的性能优化方法可以分为以下几种:
性能优化九大方式:
缓存
性能优化,缓存为王,所以开始先介绍一下缓存。缓存在我们的架构设计中无处不在的,常规请求是浏览器发起请求,请求服务端服务,服务端服务再查询数据库中的数据,每次读取数据都会至少需要两次网络I/O,性能会差一些,我们可以在整个流程中增加缓存来提升性能。首先是浏览器测,可以通过Expires、Cache-Control、Last-Modified、Etag等相关字段来控制浏览器是否使用本地缓存。
其次我们可以在服务端服务使用本地缓存或者一些中间件来缓存数据,例如redis。redis之所以这么快,主要因为数据存储在内存中,不需要读取磁盘,因为内存读取速度通常是磁盘的数百倍甚至更多;
然后在数据库测,通常使用的是mysql,mysql的数据存储到磁盘上,但是mysql为了提升读写性能,会利用bufferpool缓存数据页。mysql读取时会按照页的粒度将数据页读取到bufferpool中,bufferpool中的数据页使用LRU算法淘汰长期没有用到的页面,缓存最近访问的数据页。
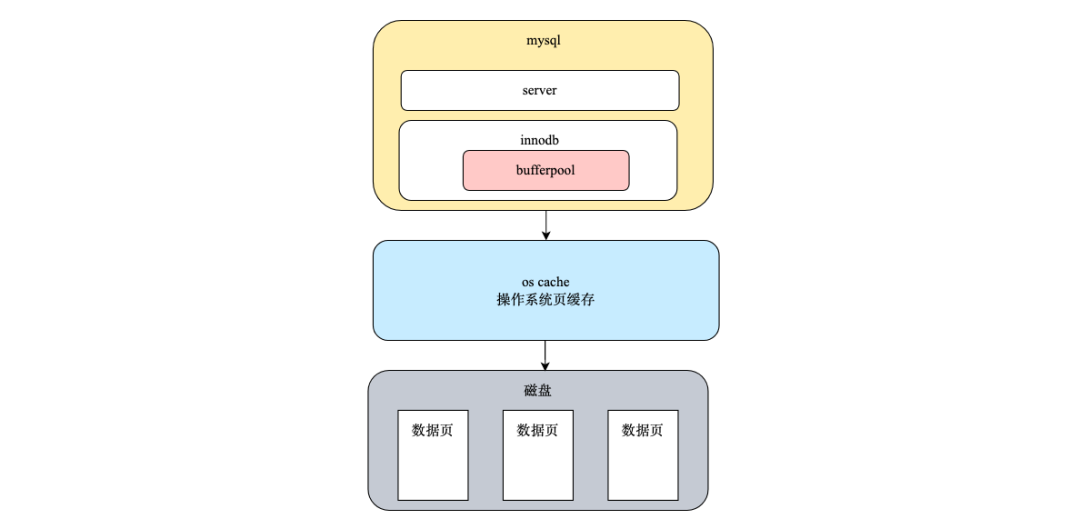
此外小到cpu的l1、l2、l3级cache,大到浏览器缓存都是为了提高性能,缓存也是进行服务性能优化的重要手段,使用缓存时需要考虑以下几点。
使用什么样的缓存
使用缓存时可以使用redis或者机器内存来缓存数据,使用redis的好处可以保证不同机器读取数据的一致性,但是读取redis会增加一次I/O,使用内存缓存数据时可能会出现读取数据不一致,但是读取性能好。例如文章的阅读数数据,如果使用机器内存作为缓存,容易出现不同机器上缓存数据的不一致,用户不同刷次会请求到不同服务端机器,读取的阅读数不一致,可能会出现阅读数变小的情况,用户体验不好。对于阅读数这种经常变更的数据比较适合使用redis来统一缓存。
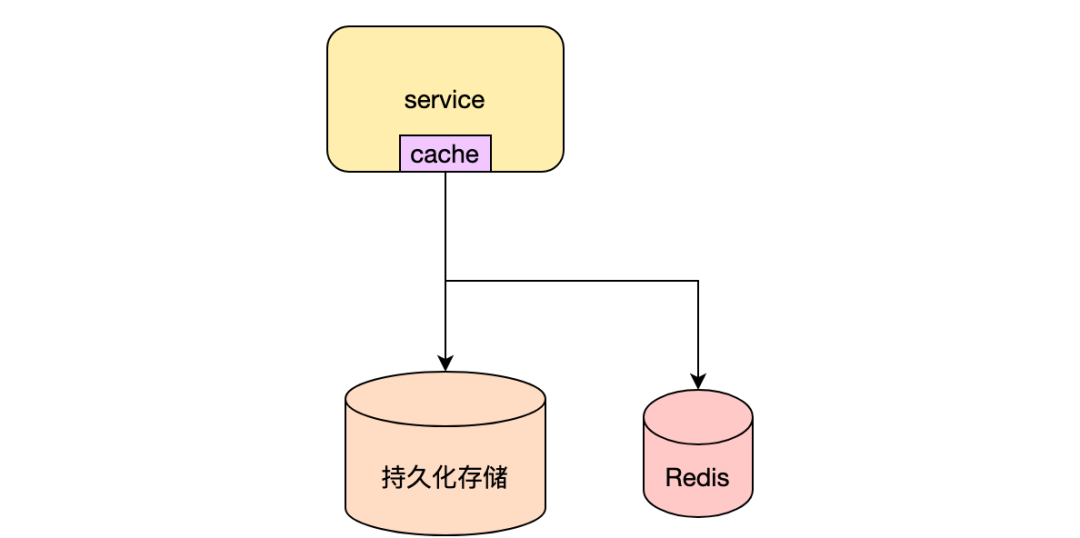
也可以将两者结合提升服务的性能,例如在内容池服务,利用redis跟机器内存缓存热点文章详情,优先读取机器内存中的数据,数据不存在的时候会读取redis中的缓存数据,当redis中的数据也不存在的时候,会读取下游持久化存储中的全量数据。其中内存级缓存过期时间为15s,在数据变更的时候不保证数据一致性,通过数据自然过期来保证最终一致性。redis中缓存数据需要保证与持久化存储中数据一致性,如何保证一致性在后续讲解。可以根据自己的业务场景可以选择合适的缓存方案。
使用缓存时可以使用redis或者机器内存来缓存数据,使用redis的好处可以保证不同机器读取数据的一致性,但是读取redis会增加一次I/O,使用内存缓存数据时可能会出现读取数据不一致,但是读取性能好。例如文章的阅读数数据,如果使用机器内存作为缓存,容易出现不同机器上缓存数据的不一致,用户不同刷次会请求到不同服务端机器,读取的阅读数不一致,可能会出现阅读数变小的情况,用户体验不好。对于阅读数这种经常变更的数据比较适合使用redis来统一缓存。
也可以将两者结合提升服务的性能,例如在内容池服务,利用redis跟机器内存缓存热点文章详情,优先读取机器内存中的数据,数据不存在的时候会读取redis中的缓存数据,当redis中的数据也不存在的时候,会读取下游持久化存储中的全量数据。其中内存级缓存过期时间为15s,在数据变更的时候不保证数据一致性,通过数据自然过期来保证最终一致性。redis中缓存数据需要保证与持久化存储中数据一致性,如何保证一致性在后续讲解。可以根据自己的业务场景可以选择合适的缓存方案。
缓存常见问题
1、缓存雪崩:缓存雪崩是指缓存中的大量数据同时失效或者过期,导致大量的请求直接读取到下游数据库,导致数据库瞬时压力过大,通常的解决方案是将缓存数据设置的过期时间随机化。在事件服务中就是利用固定过期时间+随机值的方式进行文章的淘汰,避免缓存雪崩。
2、 缓存穿透:缓存穿透是指读取下游不存在的数据,导致缓存命中不了,每次都请求下游数据库。这种情况通常会出现在线上异常流量攻击或者下游数据被删除的状况,针对缓存穿透可以使用布隆过滤器对不存在的数据进行过滤,或者在读取下游数据不存在的情况,可以在缓存中设置空值,防止不断的穿透。事件服务可能会出现查询文章被删除的情况,就是利用设置空值的方法防止被删除数据的请求不断穿透到下游。
3、 缓存击穿: 缓存击穿是指某个热点数据在缓存中被删除或者过期,导致大量的热点请求同时请求数据库。解决方案可以对于热点数据设置较长的过期时间或者利用分布式锁避免多个相同请求同时访问下游服务。在新闻业务中,对于热点新闻经常会出现这种情况,事件服务利用golang的singlefilght保证同一篇文章请求在同一时刻只有一个会请求到下游,防止缓存击穿。
4、热点key: 热点key是指缓存中被频繁访问的key,导致缓存该key的分片或者redis访问量过高。可以将可热点key分散存储到多个key上,例如将热点key+序列号的方式存储,不同key存储的值都是相同的,在访问时随机访问一个key,分散原来单key分片的压力;此外还可以将key缓存到机器内存中,避免redis单节点压力过大,在新闻业务中,对于热点文章就是采用这种方式,将热点文章存储到机器内存中,避免存储热点文章redis单分片请求量过大。
key val => key1 val 、 key2 val、 key3 val 、 key4 val
缓存淘汰
缓存的大小是有限的,因为需要对缓存中数据进行淘汰,通常可以采用随机、LRU或者LFU算法等淘汰数据。LRU是一种最常用的置换算法,淘汰最近最久未使用的数据,底层可以利用map+双端队列的数据结构实现。
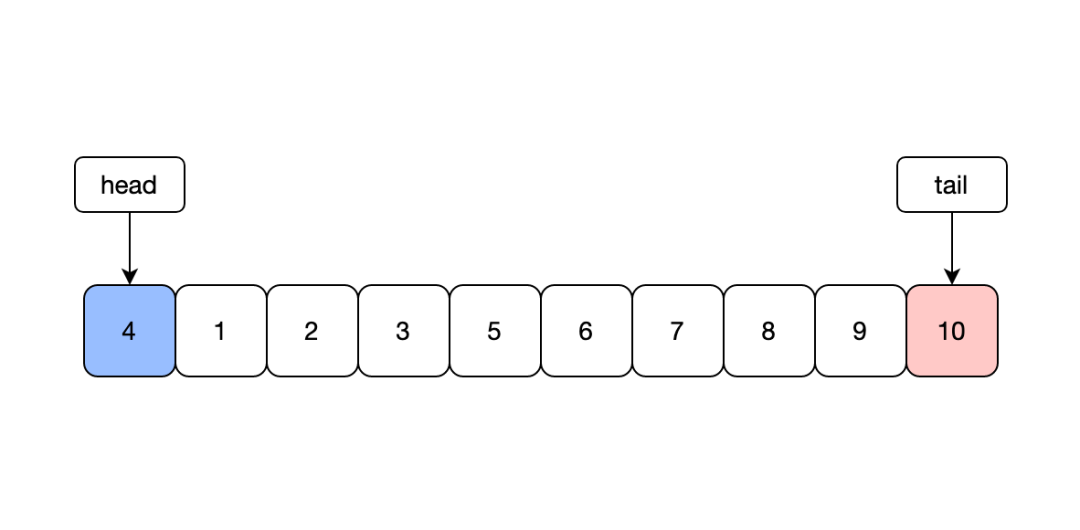
最原生的LRU算法是存在一些问题的,不知道大家在使用过有没有遇到过问题。首先需要注意的是在数据结构中有互斥锁,因为golang对于map的读写会产生panic,导致服务异常。使用互斥锁之后会导致整个缓存性能变差,可以采用分片的思想,将整个LRUCache分为多个,每次读取时读取其中一个cache片,降低锁的粒度来提升性能,常见的本地缓存包通常就利用这种方式实现的。
type LRUCache struct {
sync.Mutex
size int
capacity int
cache map[int]*DLinkNode
head, tail *DLinkNode
}
type DLinkNode struct {
key,value int
pre, next *DLinkNode
}
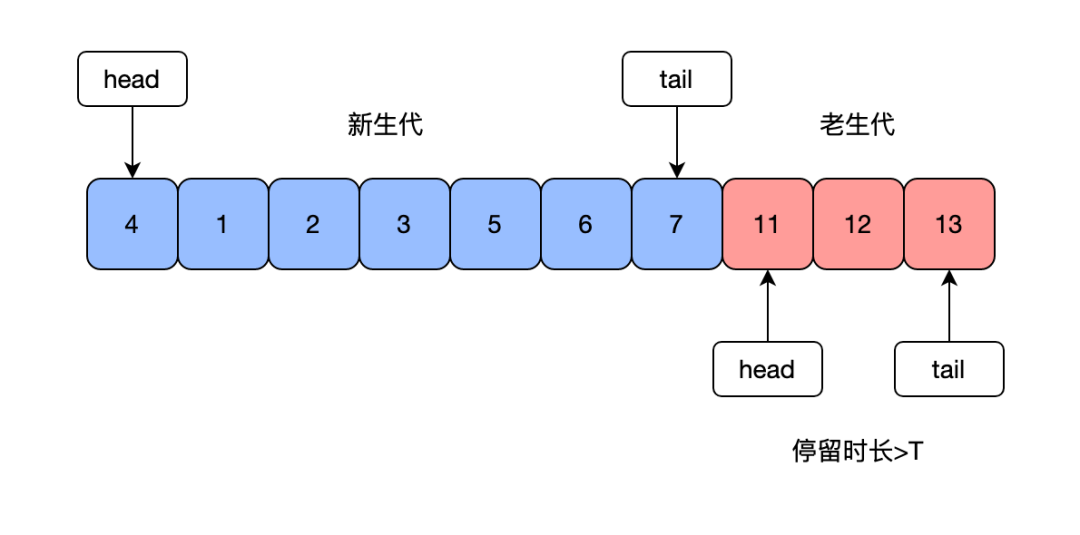
mysql也会利用LRU算法对buffer pool中的数据页进行淘汰。由于mysql存在预读,在读取磁盘时并不是按需读取,而是按照整个数据页的粒度进行读取,一个数据页会存储多条数据,除了读取当前数据页,可能也会将接下来可能用到的相邻数据页提前缓存到bufferpool中,如果下次读取的数据在缓存中,直接读取内存即可,不需要读取磁盘,但是如果预读的数据页一直没有被访问,那就会存在预读失效的情况,淘汰原来使用到的数据页。mysql将buffer pool中的链表分为两部分,一段是新生代,一段是老生代,新老生代的默认比是7:3,数据页被预读的时候会先加到老生代中,当数据页被访问时才会加载到新生代中,这样就可以防止预读的数据页没有被使用反而淘汰热点数据页。此外mysql通常会存在扫描表的请求,会顺序请求大量的数据加载到缓存中,然后将原本缓存中所有热点数据页淘汰,这个问题通常被称为缓冲池污染,mysql中的数据页需要在老生代停留时间超过配置时间才会老生代移动到新生代时来解决缓存池污染。
redis中也会利用LRU进行淘汰过期的数据,如果redis将缓存数据都通过一个大的链表进行管理,在每次读写时将最新访问的数据移动到链表队头,那样会严重影响redis的读写性能,此外会增加额外的存储空间,降低整体存储数量。redis是对缓存中的对象增加一个最后访问时间的字段,在对对象进行淘汰的时候,会采用随机采样的方案,随机取5个值,淘汰最近访问时间最久的一个,这样就可以避免每次都移动节点。但是LRU也会存在缓存污染的情况,一次读取大量数据会淘汰热点数据,因此redis可以选择利用LFU进行淘汰数据,是将原来的访问时间字段变更为最近访问时间+访问次数的一个字段,这里需要注意的是访问次数并不是单纯的次数累加,而是根据最近访问时间跟当前时间的差值进行时间衰减的,简单说也就是访问越久以及访问次数越少计算得到的值也越小,越容易被淘汰。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} obj ;
可以看出不同中间件对于传统的LRU淘汰策略都进行了一定优化来保证服务性能,我们也可以参考不同的优化策略在自己的服务中进行缓存key的淘汰。
缓存数据一致性
当数据库中的数据变更时,如何保证缓存跟数据库中的数据一致,通常有以下几种方案:更新缓存再更新DB,更新DB再更新缓存,先更新DB再删除缓存,删除缓存再更新DB。这几种方案都有可能会出现缓存跟数据库中的数据不一致的情况,最常用的还是更新DB再删除缓存,因为这种方案导致数据不一致的概率最小,但是也依然会存在数据不一致的问题。例如在T1时缓存中无数据,数据库中数据为100,线程B查询缓存没有查询到数据,读取到数据库的数据100然后去更新缓存,但是此时线程A将数据库中的数据更新为99,然后在T4时刻删除缓存中的数据,但是此时缓存中还没有数据,在T5的时候线程B才更新缓存数据为100,这时候就会导致缓存跟数据库中的数据不一致。
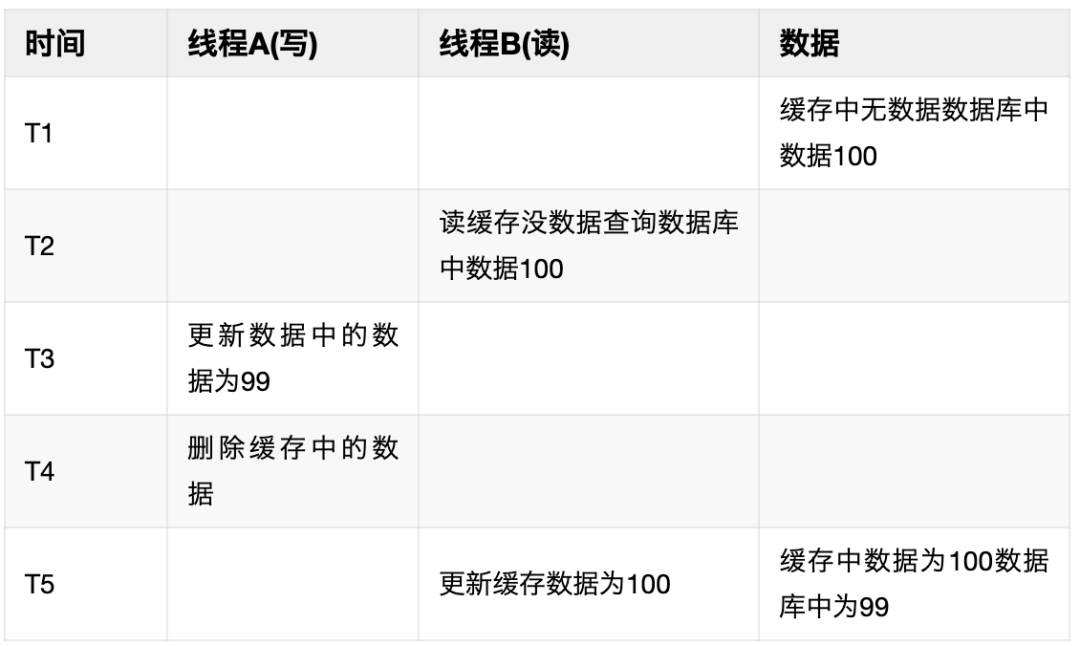
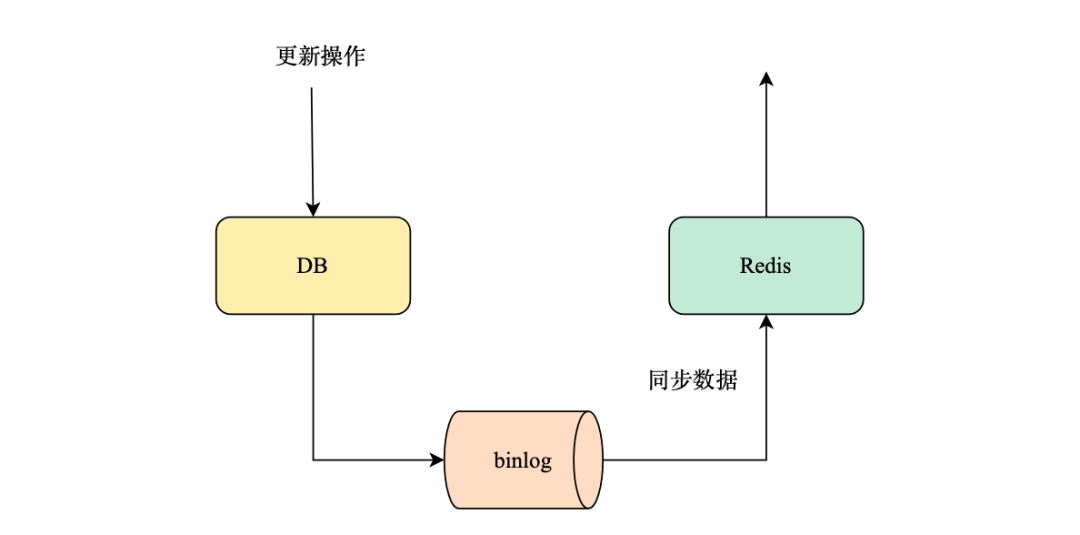
为保证缓存与数据库数据的一致性。常用的解决方案有两种,一种是延时双删,先删除缓存,后续更新数据库,休眠一会再删除缓存。文章池服务中就是利用这种方案保证数据一致性,如何实现延迟删除,是通过go语言中channel实现简单延时队列,没有引入第三方的消息队列,主要为了防止服务的复杂化;另外一种可以订阅DB的变更binlog,数据更新时只更新DB,通过消费DB的binlog日志,解析变更操作进行缓存变更,更新失败时不进行消息的提交,通过消息队列的重试机制实现最终一致性。
并行化处理
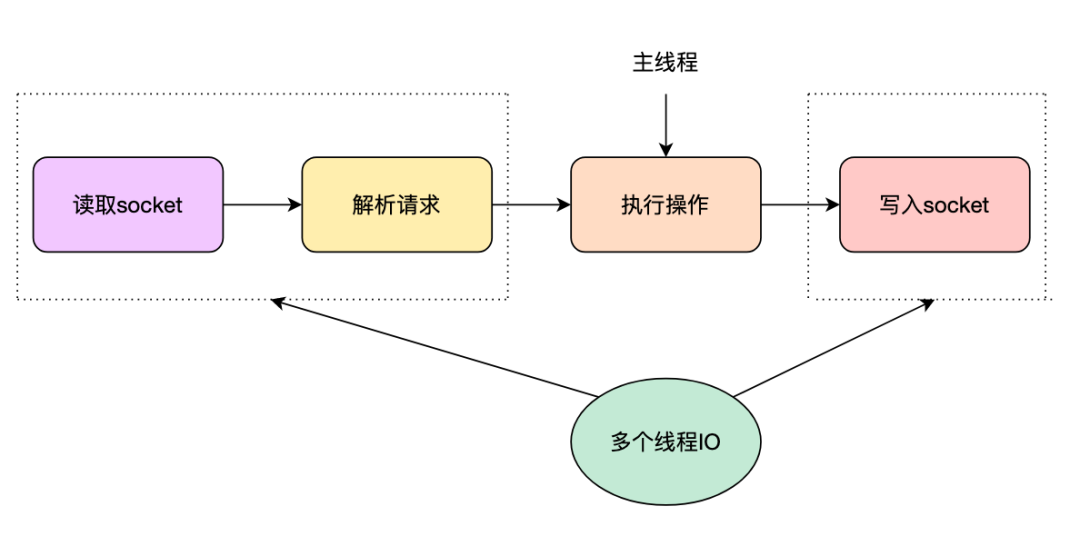
redis在版本6.0之前都是号称单线程模型,主要是利用epllo管理用户海量连接,使用一个线程通过事件循环来处理用户的请求,优点是避免了线程切换和锁的竞争,以及实现简单,但是缺点也比较明显,不能有效的利用cpu的多核资源。随着数据量和并发量的越来越大,I/O成了redis的性能瓶颈点,因此在6.0版本引入了多线程模型。redis的多线程将处理过程最耗时的sockect的读取跟解析写入由多个I/O 并发完成,对于命令的执行过程仍然由单线程完成。
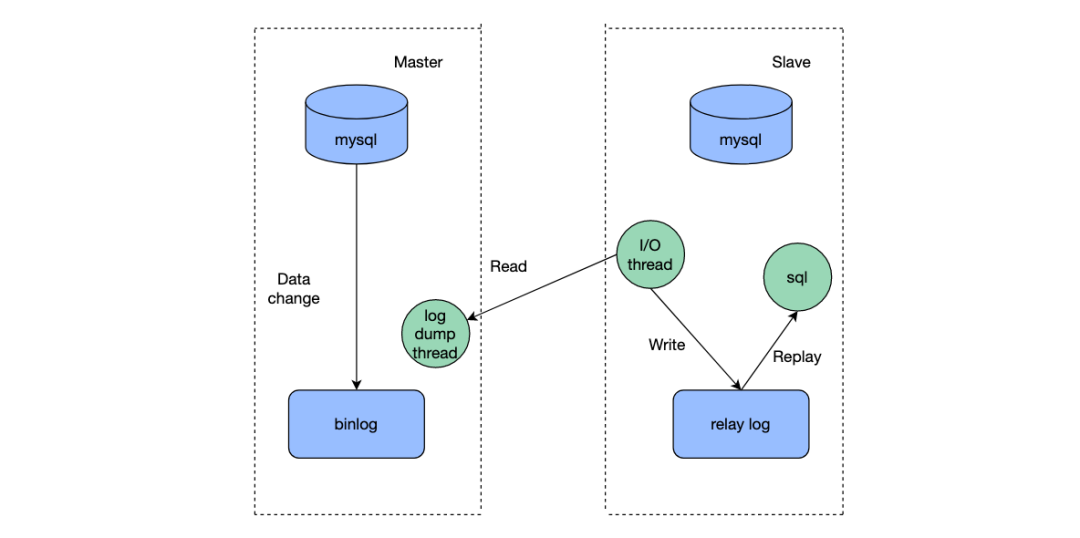
mysql的主从同步过程从数据库通过I/Othread读取住主库的binlog,将日志写入到relay log中,然后由sqlthread执行relaylog进行数据的同步。其中sqlthread就是由多个线程并发执行加快数据的同步,防止主从同步延迟。sqlthread多线程化也经历了多个版本迭代,按表维度分发到同一个线程进行数据同步,再到按行维度分发到同一个线程。
小到线程的并发处理,大到redis的集群,以及kafka的分topic分区都是通过多个client并行处理提高服务的读写性能。在我们的服务设计中可以通过创建多个容器对外服务提高服务的吞吐量,服务内部可以将多个串行的I/O操作改为并行处理,缩短接口的响应时长,提升用户体验。对于I/O存在相互依赖的情况,可以进行多阶段分批并行化处理,另外一种常见的方案就是利用DAG加速执行,但是需要注意的是DAG会存在开发维护成本较高的情况,需要根据自己的业务场景选择合适的方案。并行化也不是只有好处没有坏处的,并行化有可能会导致读扩散严重,以及线程切换频繁存在一定的性能影响。
批量化处理
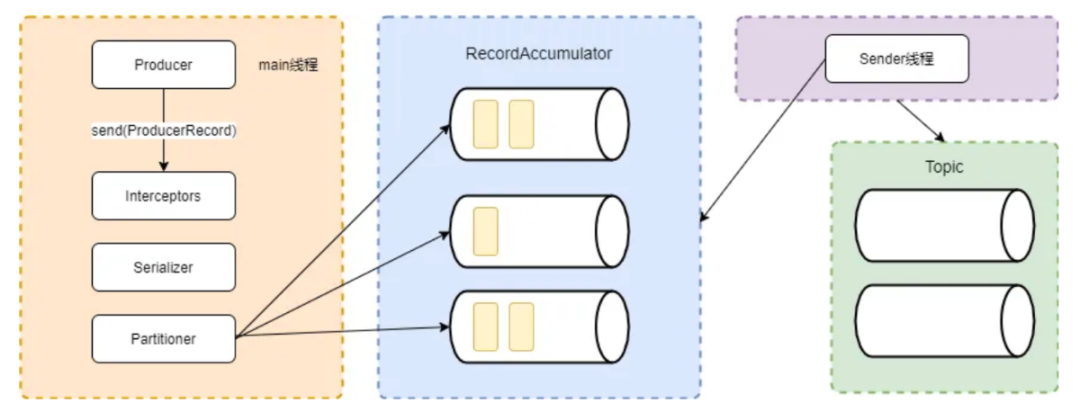
kafka的消息发送并不是直接写入到broker中的,发送过程是将发送到同一个topic同一个分区的消息通过main函数的partitioner组件发送到同一个队列中,由sender线程不断拉取队列中消息批量发送到broker中。利用批量发送消息处理,节省大量的网络开销,提高发送效率。
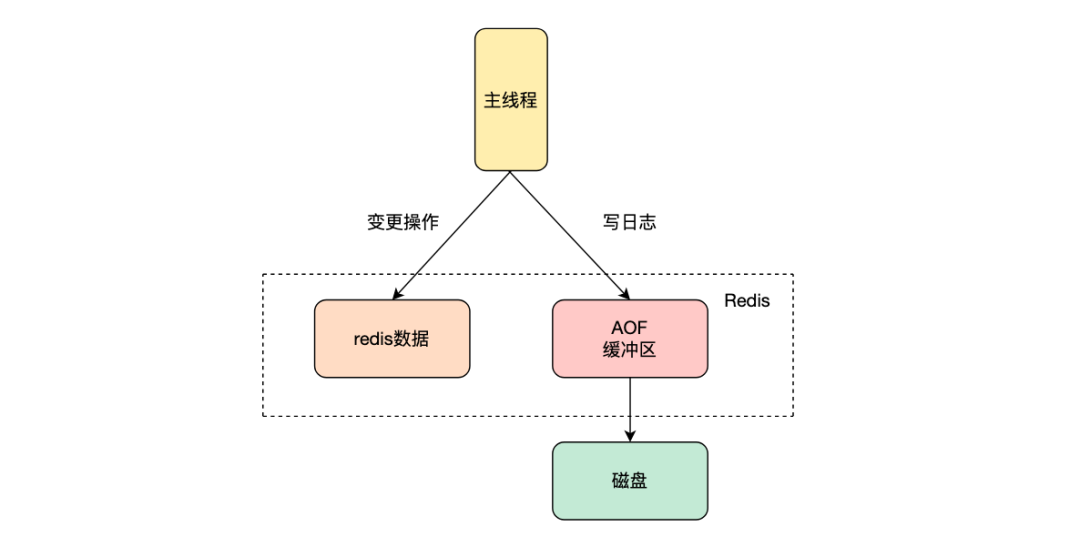
redis的持久化方式有RDB跟AOF两种,其中AOF在执行命令写入内存后,会写入到AOF缓冲区,可以选择合适的时机将AOF缓冲区中的数据写入到磁盘中,刷新到磁盘的时间通过参数appendfsync控制,有三个值always、everysec、no。其中always会在每次命令执行完都会刷新到磁盘来保证数据的可靠性;everysec是每秒批量写入到磁盘,no是不进行同步操作,由操作系统决定刷新到写回磁盘,当redis异常退出时存在丢数据的风险。AOF命令刷新到磁盘的时机会影响redis服务写入性能,通常配置为everysec批量写入到磁盘,来平衡写入性能和数据可靠性。
我们读取下游服务或者数据库的时候,可以一次多查询几条数据,节省网络I/O;读取redis的还可以利用pipeline或者lua脚本处理多条命令,提升读写性能;前端请求js文件或者小图片时,可以将多个js文件或者图片合并到一起返回,减少前端的连接数,提升传输性能。同样需要注意的是批量处理多条数据,有可能会降低吞吐量,以及本身下游就不支持过多的批量数据,此时可以将多条数据分批并发请求。对于事件底层页服务中不同组件下配置的不同文章id,会统一批量请求下游内容服务获取文章详情,对于批量的条数也会做限制,防止单批数据量过大。
数据压缩合并
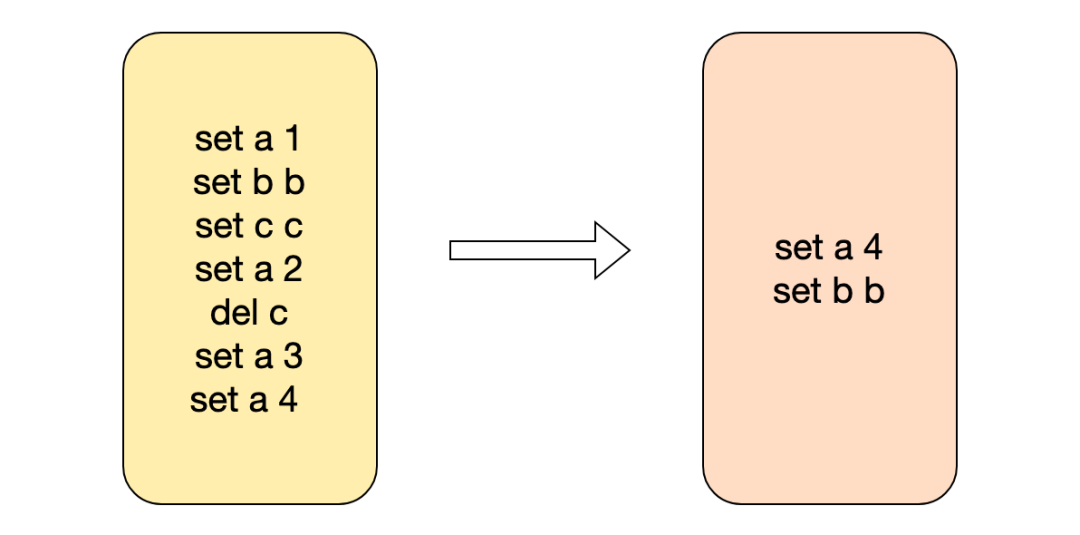
redis的AOF重写是利用bgrewriteaof命令进行AOF文件重写,因为AOF是追加写日志,对于同一个key可能存在多条修改修改命令,导致AOF文件过大,redis重启后加载AOF文件会变得缓慢,导致启动时间过长。可以利用重写命令将对于同一个key的修改只保存一条记录,减小AOF文件体积。
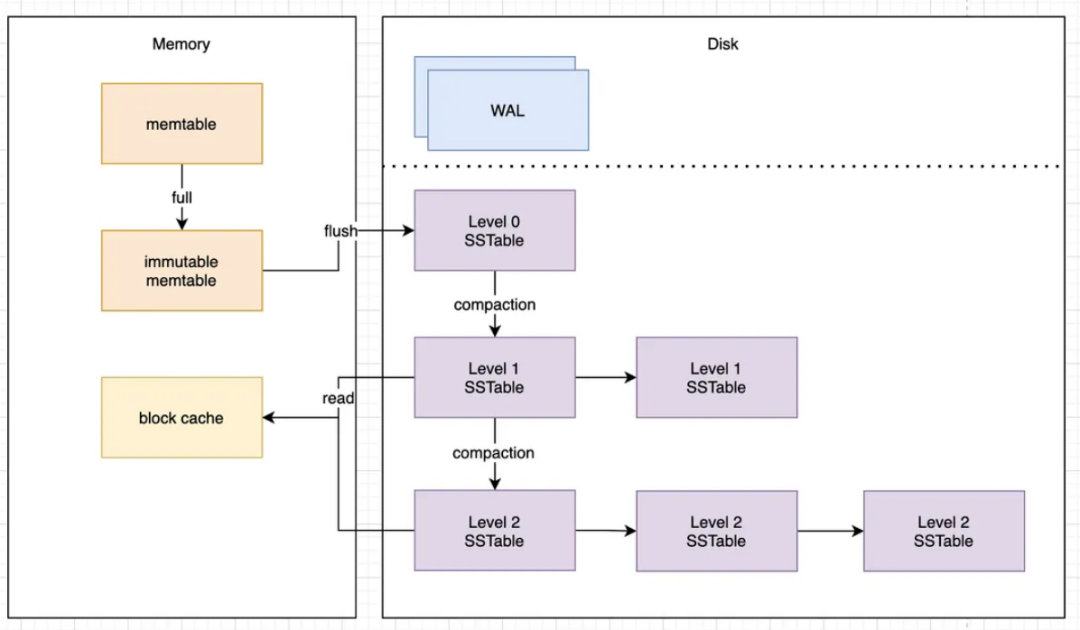
大数据领域的Hbase、cassandra等nosql数据库写入性能都很高,它们的底层存储数据结构就是LSM树(log structured merge tree),这种数据结构的核心思想是追加写,积攒一定的数据后合并成更大的segement,对于数据的删除也只是增加一条删除记录。同样对一个key的修改记录也有多条。这种存储结构的优点是写入性能高,但是缺点也比较明显,数据存在冗余和文件体积大。主要通过线程进行段合并将多个小文件合并成更大的文件来减少存储文件体积,提升查询效率。
对于kafka进行传输数据时,在生产者端和消费者端可以开启数据压缩。生产者端压缩数据后,消费者端收到消息会自动解压,可以有效减小在磁盘的存储空间和网络传输时的带宽消耗,从而降低成本和提升传输效率。需要注意生产者端和消费者端指定相同的压缩算法。
在降本增效的浪潮中,降低redis成本的一种方式,就是对存储到redis中的数据进行压缩,降低存储成本,重构后的内容微服务通过持久化存储全量数据,采用snappy压缩,压缩后只是原来数据的40%-50%;还有一种方式是将服务之间的调用从http的json改为trpc的pb协议,因为pb协议编码后的数据更小,提升传输效率,在服务优化时,将原来请求tab的协议从json转成pb,降低几毫秒的时延,此外内容微服务存储的数据采用flutbuffer编码,相比较于protobuffer有着更高的压缩比跟更快的编解码速度;对于JS/CSS多个文件下发也可以进行混淆和压缩传递;对于存储在es中的数据也可以手动调用api进行段合并,减小存储数据的体积,提高查询速度;在我们工作中还有一个比较常见的问题是接口返回的冗余数据特别多,一个接口服务下发的数据大而全,而不是对于当前场景做定制化下发,不满足接口最小化原则,白白浪费了很多带宽资源和降低传输效率。
无锁化
redis通过单线程避免了锁的竞争,避免了线程之间频繁切换才有这很好的读写性能。
go语言中提供了atomic包,主要用于不同线程之间的数据同步,不需要加锁,本质上就是封装了底层cpu提供的原子操作指令。此外go语言最开始的调度模型时GM模型,所有的内核级线程想要执行goroutine需要加锁从全局队列中获取,所以不同线程之间的竞争很激烈,调度效率很差。
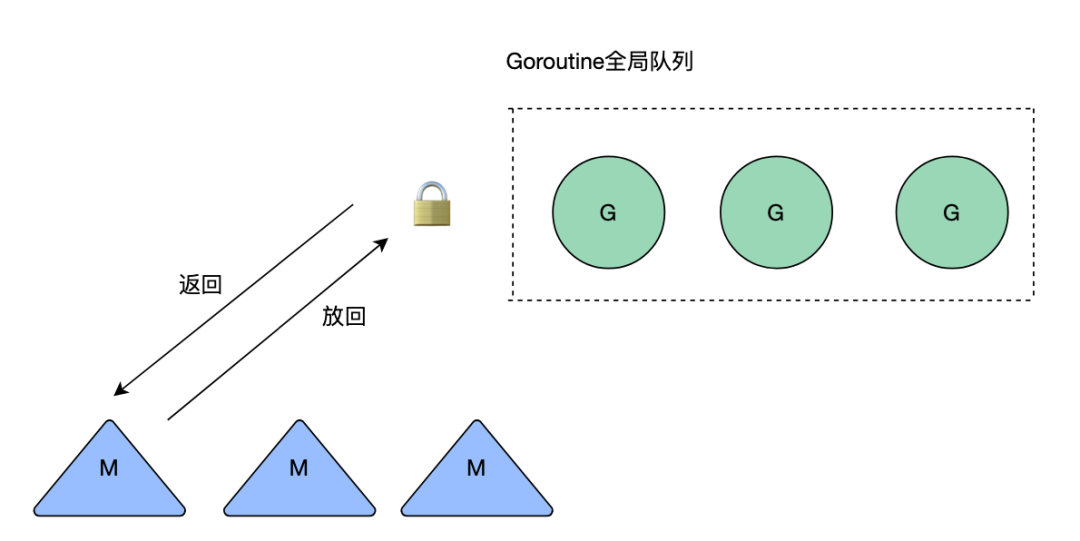
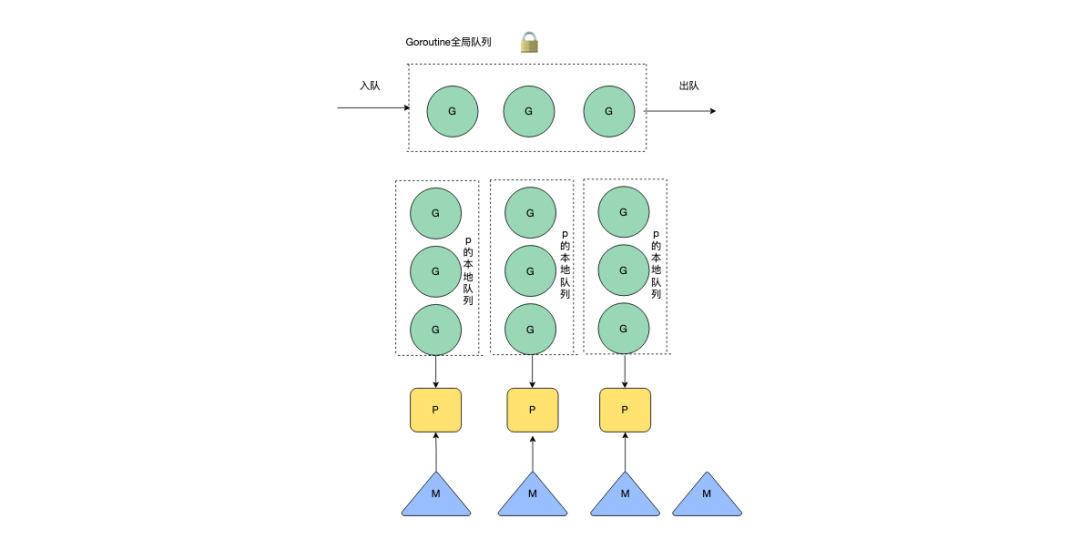
后续引入了P(Processor),每一个M(thread)要执行G(gorontine)的时候需要绑定一个P,其中P中会有一个待执行G的本地队列,只由当前M可以进行读写(少数情况会存在偷其他协程的G),读取P本地队列时不需要进行加锁,通过降低锁的竞争大幅度提升调度G的效率。
mysql利用mvcc实现多个事务进行读写并发时保证数据的一致性和隔离型,也是解决读写并发的一种无锁化设计方案之一。它主要通过对每一行数据的变更记录维护多个版本链来实现的,通过隐藏列rollptr和undolog来实现快照读。在事务对某一行数据进行操作时,会根据当前事务id以及事务隔离级别判断读取那个版本的数据,对于可重复读就是在事务开始的时候生成readview,在后续整个事务期间都使用这个readview。mysql中除了使用mvcc避免互斥锁外,bufferpool还可以设置多个,通过多个bufferpool降低锁的粒度,提升读写性能,也是一种优化方案。
日常工作 在读多写少的场景下可以利用atomic.value存储数据,减少锁的竞争,提升系统性能,例如配置服务中数据就是利用atomic.value存储的;syncmap为了提升读性能,优先使用atomic进行read操作,然后再进行加互斥锁操作进行dirty的操作,在读多写少的情况下也可以使用syncmap。
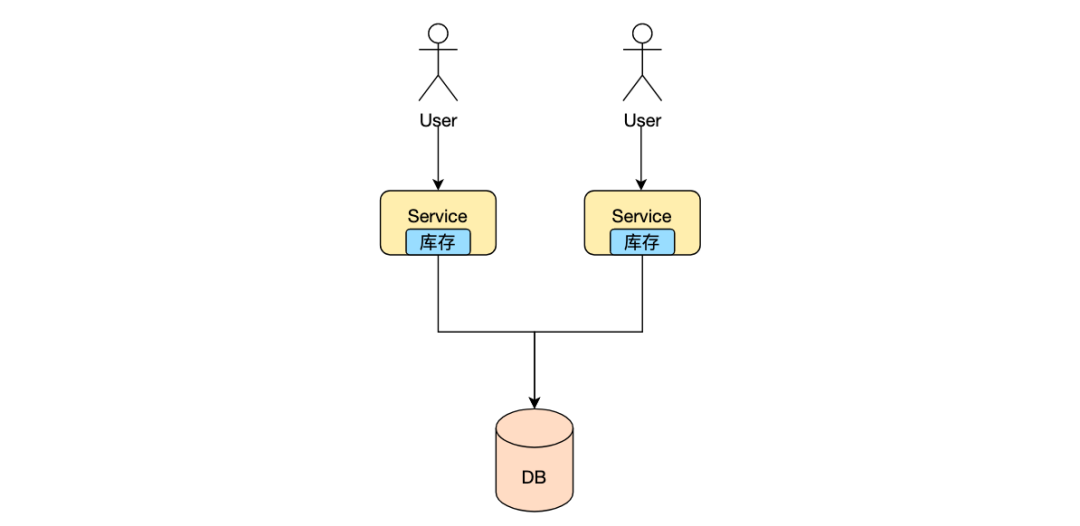
秒杀系统的本质就是在高并发下准确的增减商品库存,不出现超卖少卖的问题。因此所有的用户在抢到商品时需要利用互斥锁进行库存数量的变更。互斥锁的存在必然会成为系统瓶颈,但是秒杀系统又是一个高并发的场景,所以如何进行互斥锁优化是提高秒杀系统性能的一个重要优化手段。
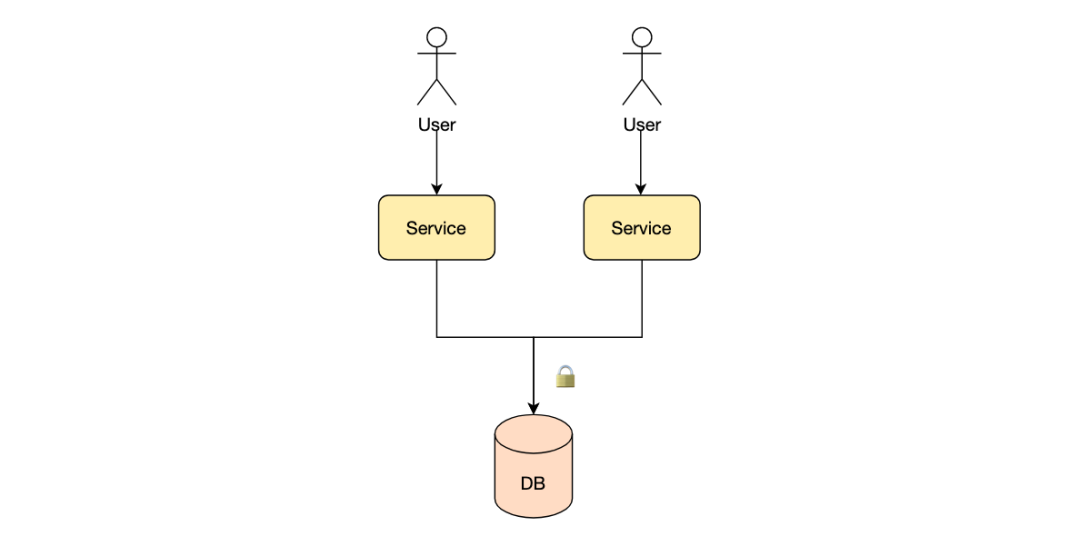
无锁化设计方案之一就是利用消息队列,对于秒杀系统的秒杀操作进行异步处理,将秒杀操作发布一个消息到消息队列中,这样所有用户的秒杀行为就形成了一个先进先出的队列,只有前面先添加到消息队列中的用户才能抢购商品成功。从队列中消费消息进行库存变更的线程是个单线程,因此对于db的操作不会存在冲突,不需要加锁操作。
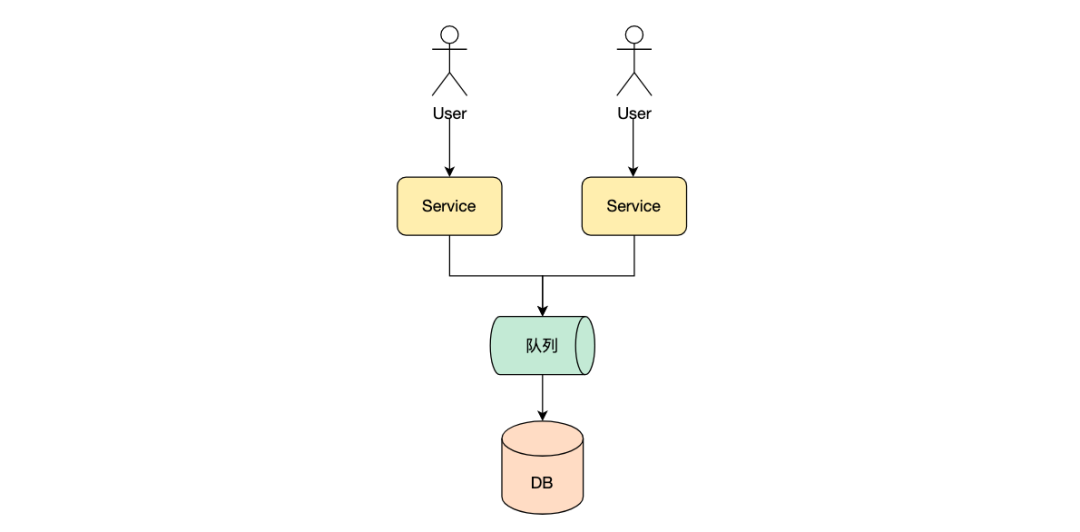
另外一种优化方式可以参考golang的GMP模型,将库存分成多份,分别加载到服务server的本地,这样多机之间在对库存变更的时候就避免了锁的竞争。如果本地server是单进程的,因此也可以形成一种无锁化架构;如果是多进程的,需要对本地库存加锁后在进行变更,但是将库存分散到server本地,降低了锁的粒度,提高整个服务性能。
顺序写
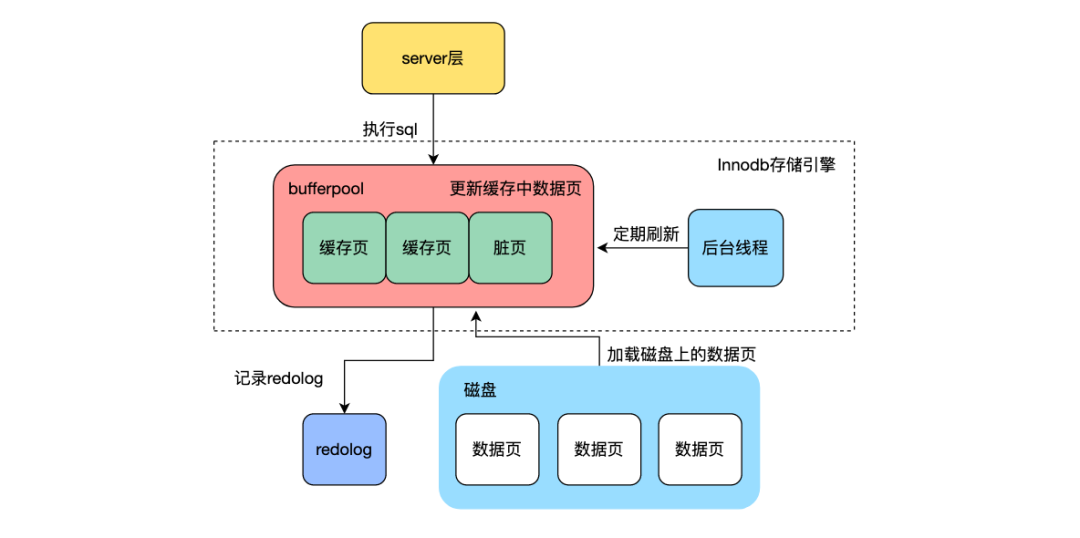
mysql的InnoDB存储引擎在创建主键时通常会建议使用自增主键,而不是使用uuid,最主要的原因是InnoDB底层采用B+树用来存储数据,每个叶子结点是一个数据页,存储多条数据记录,页面内的数据通过链表有序存储,数据页间通过双向链表存储。由于uuid是无序的,有可能会插入到已经空间不足的数据页中间,导致数据页分裂成两个新的数据页以便插入新数据,影响整体写入性能。
此外mysql中的写入过程并不是每次将修改的数据直接写入到磁盘中,而是修改内存中buffer pool内存储的数据页,将数据页的变更记录到undolog和binlog日志中,保证数据变更不丢失,每次记录log都是追加写到日志文件尾部,顺序写入到磁盘。对数据进行变更时通过顺序写log,避免随机写磁盘数据页,提升写入性能,这种将随机写转变为顺序写的思想在很多中间件中都有所体现。
kakfa中的每个分区是一个有序不可变的消息队列,新的消息会不断的添加的partition的尾部,每个partition由多个segment组成,一个segment对应一个物理日志文件,kafka对segment日志文件的写入也是顺序写。顺序写入的好处是避免了磁盘的不断寻道和旋转次数,极大的提高了写入性能。
顺序写主要会应用在存在大量磁盘I/O操作的场景,日常工作中创建mysql表时选择自增主键,或者在进行数据库数据同步时顺序读写数据,避免底层页存储引擎的数据页分裂,也会对写入性能有一定的提升。
分片化
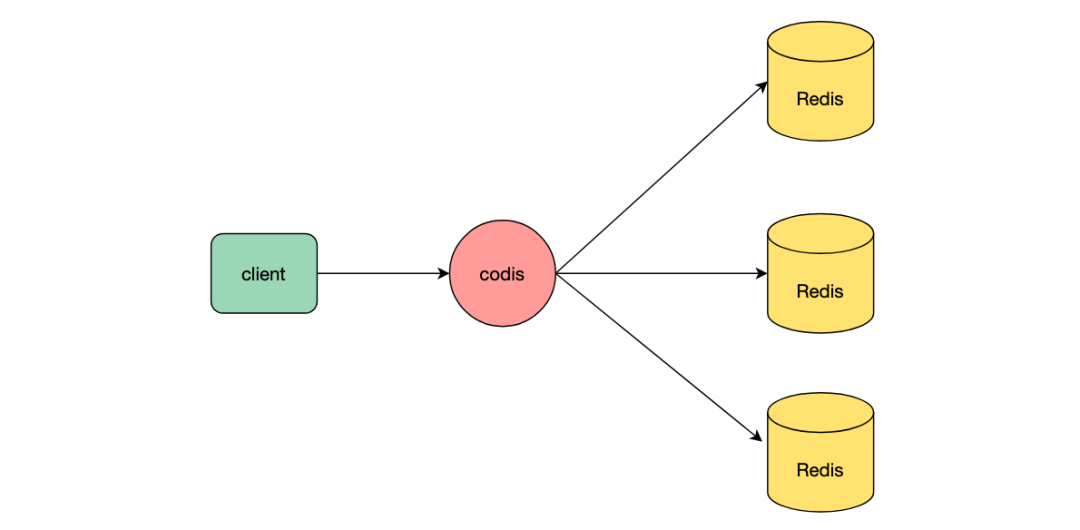
redis对于命令的执行过程是单线程的,单机有着很好的读写性能,但是单机的机器容量跟连接数毕竟有限,因此单机redis必然会存在读写上限跟存储上限。redis集群的出现就是为了解决单机redis的读写性能瓶颈问题,redis集群是将数据自动分片到多个节点上,每个节点负责数据的一部分,每个节点都可以对外提供服务,突破单机redis存储限制跟读写上限,提高整个服务的高并发能力。除了官方推出的集群模式,代理模式codis等也是将数据分片到不同节点,codis将多个完全独立的redis节点组成集群,通过codis转发请求到某一节点,来提高服务存储能力和读写性能。
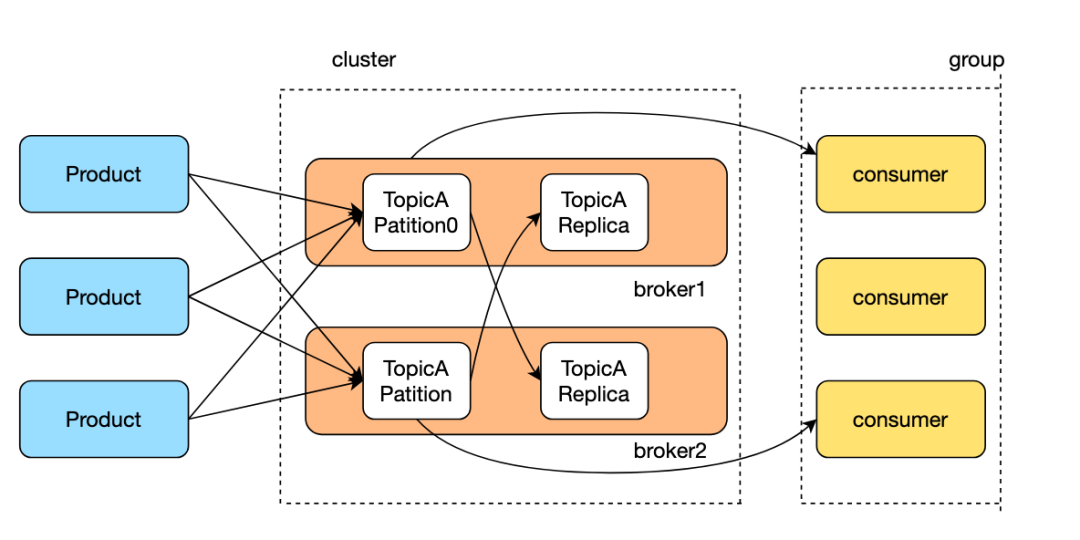
同样的kafka中每个topic也支持多个partition,partition分布到多个broker上,减轻单台机器的读写压力,通过增加partition数量可以增加消费者并行消费消息,提高kafka的水平扩展能力和吞吐量。
新闻每日会生产大量的图文跟视频数据,底层是通过tdsql存储,可以分采分片化的存储思想,将图文跟视频或者其他介质存储到不同的数据库或者数据表中,同一种介质每日的生产量也会很大,这时候就可以对同一种介质拆分成多个数据表,进一步提高数据库的存储量跟吞吐量。另外一种角度去优化存储还可以将冷热数据分离,最新的数据采用性能好的机器存储,之前老数据访问量低,采用性能差的机器存储,节省成本。
在微服务重构过程中,需要进行数据同步,将总库中存储的全量数据通过kafka同步到内容微服务新的存储中,预期同步qps高达15k。由于kafka的每个partition只能通过一个消费者消费,要达到预期qps,因此需要创建750+partition才能够实现,但是kafka的partition过多会导致rebalance很慢,影响服务性能,成本和可维护行都不高。采用分片化的思想,可以将同一个partition中的数据,通过一个消费者在内存中分片到多个channel上,不同的channel对应的独立协程进行消费,多协程并发处理消息提高消费速度,消费成功后写入到对应的成功channel,由统一的offsetMaker线程消费成功消息进行offset提交,保证消息消费的可靠性。
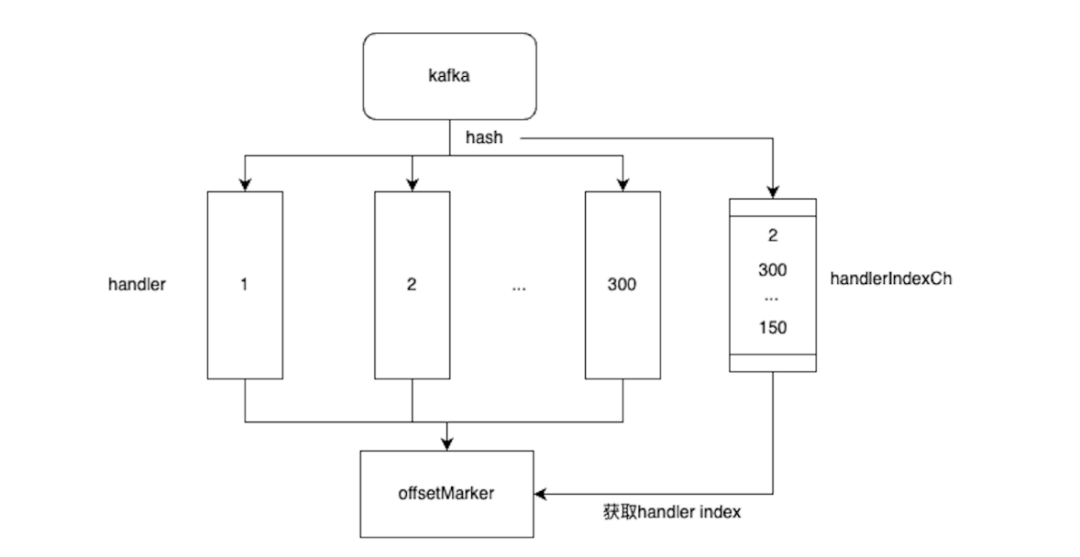
避免请求
为提升写入性能,mysql在写入数据的时候,对于在bufferpool中的数据页,直接修改bufferpool的数据页并写redolog;对于不在内存中的数据页并不会立刻将磁盘中的数据页加载到bufferpool中,而是仅仅将变更记录在缓冲区,等后续读取磁盘上的数据页到bufferpool中时会进行数据合并,需要注意的是对于非唯一索引才会采用这种方式,对于唯一索引写入的时候需要每次都将磁盘上的数据读取到bufferpool才能判断该数据是否已存在,对于已存在的数据会返回插入失败。
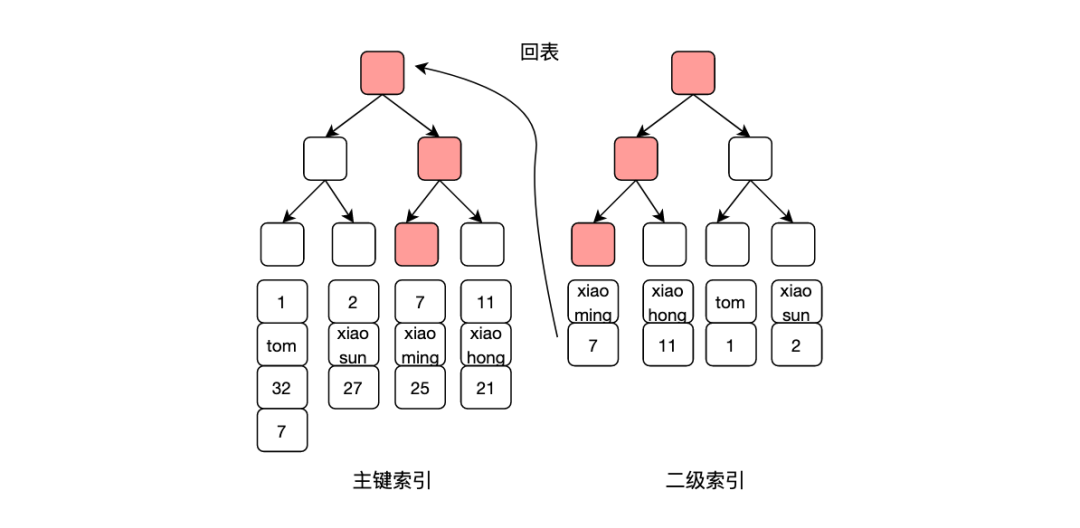
另外mysql查询例如select * from table where name = 'xiaoming' 的查询,如果name字段存在二级索引,由于这个查询是*,表示需要所在行的所有字段,需要进行回表操作,如果仅需要id和name字段,可以将查询语句改为select id , name from tabler where name = 'xiaoming' ,这样只需要在name这个二级索引上就可以查到所需数据,避免回表操作,减少一次I/O,提升查询速度。
web应用中可以使用缓存、合并css和js文件等,避免或者减少http请求,提升页面加载速度跟用户体验。
在日常移动端开发应用中,对于多tab的数据,可以采用懒加载的方式,只有用户切换到新的tab之后才会发起请求,避免很多无用请求。服务端开发随着版本的迭代,有些功能字段端上已经不展示,但是服务端依然会返回数据字段,对于这些不需要的数据字段可以从数据源获取上就做下线处理,避免无用请求。另外在数据获取时可以对请求参数的合法性做准确的校验,例如请求投票信息时,运营配置的投票ID可能是“” 或者“0”这种不合法参数,如果对请求参数不进行校验,可能会存在很多无用I/O请求。另外在函数入口处通常会请求用户的所有实验参数,只有在实验期间才会用到实验参数,在实验下线后并没有下线ab实验平台的请求,可以在非实验期间下线这部分请求,提升接口响应速度。
池化
golang作为现代原生支持高并发的语言,池化技术在它的GMP模型就存在很大的应用。对于goroutine的销毁就不是用完直接销毁,而是放到P的本地空闲队列中,当下次需要创建G的时候会从空闲队列中直接取一个G复用即可;同样的对于M的创建跟销毁也是优先从全局队列中获取或者释放。此外golang中sync.pool可以用来保存被重复使用的对象,避免反复创建和销毁对象带来的消耗以及减轻gc压力。
mysql等数据库也都提供连接池,可以预先创建一定数量的连接用于处理数据库请求。当请求到来时,可以从连接池中选择空闲连接来处理请求,请求结束后将连接归还到连接池中,避免连接创建和销毁带来的开销,提升数据库性能。
在日常工作中可以创建线程池用来处理请求,在请求到来时同样的从链接池中选择空闲的线程来处理请求,处理结束后归还到线程池中,避免线程创建带来的消耗,在web框架等需要高并发的场景下非常常见。
异步处理
异步处理在数据库中同样应用广泛,例如redis的bgsave,bgrewriteof就是分别用来异步保存RDB跟AOF文件的命令,bgsave执行后会立刻返回成功,主线程fork出一个线程用来将内存中数据生成快照保存到磁盘,而主线程继续执行客户端命令;redis删除key的方式有del跟unlink两种,对于del命令是同步删除,直接释放内存,当遇到大key时,删除操作会让redis出现卡顿的问题,而unlink是异步删除的方式,执行后对于key只做不可达的标识,对于内存的回收由异步线程回收,不阻塞主线程。
mysql的主从同步支持异步复制、同步复制跟半同步复制。异步复制是指主库执行完提交的事务后立刻将结果返回给客户端,并不关心从库是否已经同步了数据;同步复制是指主库执行完提交的事务,所有的从库都执行了该事务才将结果返回给客户端;半同步复制指主库执行完后,至少一个从库接收并执行了事务才返回给客户端。有多种主要是因为异步复制客户端写入性能高,但是存在丢数据的风险,在数据一致性要求不高的场景下可以采用,同步方式写入性能差,适合在数据一致性要求高的场景使用。 此外对于kafka的生产者跟消费者都可以采用异步的方式进行发送跟消费消息,但是采用异步的方式有可能会导致出现丢消息的问题。对于异步发送消息可以采用带有回调函数的方式,当发送失败后通过回调函数进行感知,后续进行消息补偿。
在做服务性能优化中,发现之前的一些监控上报,曝光上报等操作都在主流程中,可以将这部分功能做异步处理,降低接口的时延。此外用户发布新闻后,会将新闻写入到个人页索引,对图片进行加工处理,标题进行审核,或者给用户增加活动积分等操作,都可以采用异步处理,这里的异步处理是将发送消息这个动作发送消息到消息队列中,不同的场景消费消息队列中的消息进行各自逻辑的处理,这种设计保证了写入性能,也解耦不同场景业务逻辑,提高系统可维护性。
总结
本文主要总结进行服务性能优化的几种方式,每一种方式在我们常用的中间件中都有所体现,我想这也是我们常说多学习这些中间件的意义,学习它们不仅仅是学会如何去使用它们,也是学习它们底层优秀的设计思想,理解为什么要这样设计,这种设计有什么好处,后续我们在架构选型或者做服务性能优化时都会有一定的帮助。此外性能优化方式也给出了具体的落地实践,
希望通过实际的应用例子加强对这种优化方式的理解。此外要做服务性能优化,还是要从自身服务架构出发,分析服务调用链耗时分布跟cpu消耗,优化有问题的rpc调用和函数。
















 165万+
165万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









