






b站视频:https://www.bilibili.com/video/BV1xS411F7x8/?vd_source=4abbaefcba03a8f8ab575d07cd59a36d
如有不懂之处请查看此视频
研究背景
1.1 FL为什么要激励机制
假设所有客户都是无私的,愿意贡献他们的数据是不现实和不合理的。参与FL还会带来计算、能量、通信带宽以及可能的数据隐私暴露等各种开销。因此,在FL中建立一个激励机制,使客户主动参与到FL中来,以达到较高的模型精度是至关重要的。同时为了保护联邦学习共享参数的隐私,使用了差分隐私进行保护。
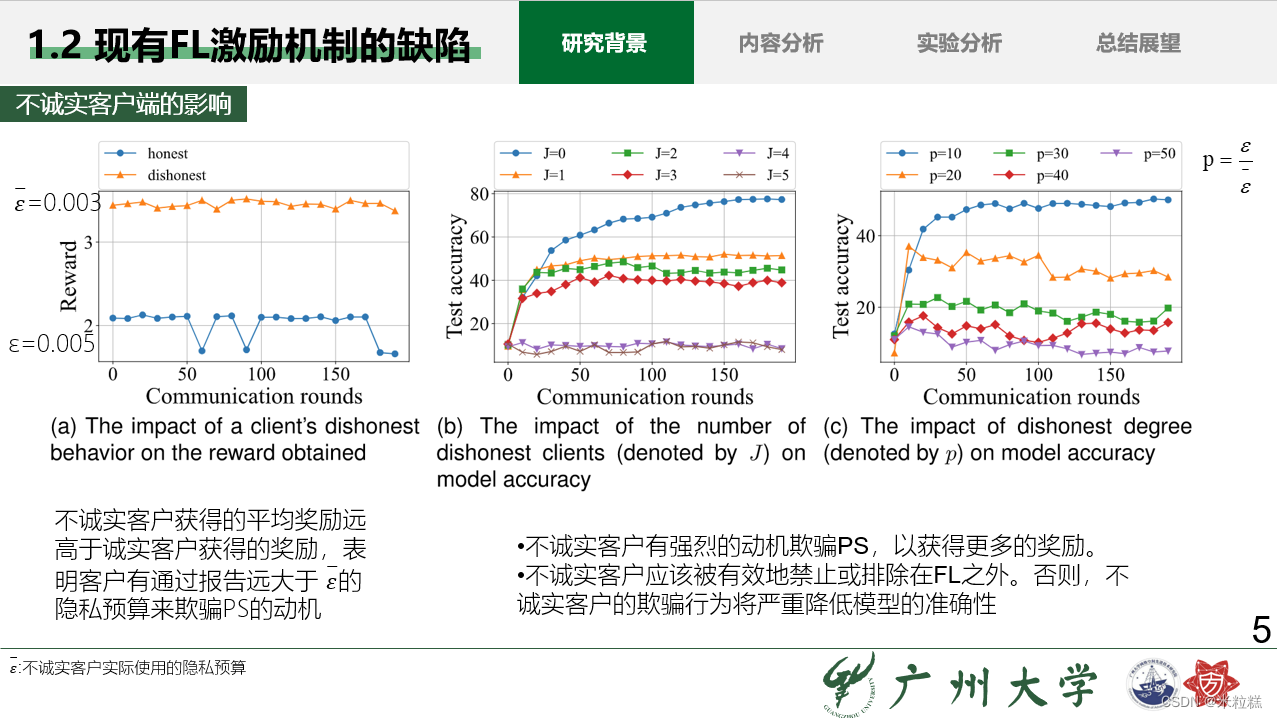
1.2 现有FL激励机制的缺陷
这种缺陷主要是由"不诚实的客户端" 所造成的,“不诚实的客户端” 指的是在联邦学习过程中采取了不当行为或者欺骗性行为的客户端。这些行为可能包括但不限于:
提供虚假的隐私预算或报告不准确的隐私预算。
提交错误的模型更新或者修改模型更新以便获取更多的奖励而不是按照协议提交合法的更新。
故意干扰或破坏联邦学习过程,例如发送有害的模型更新或者拒绝参与协作。
1.3 作者的解决方法

内容分析
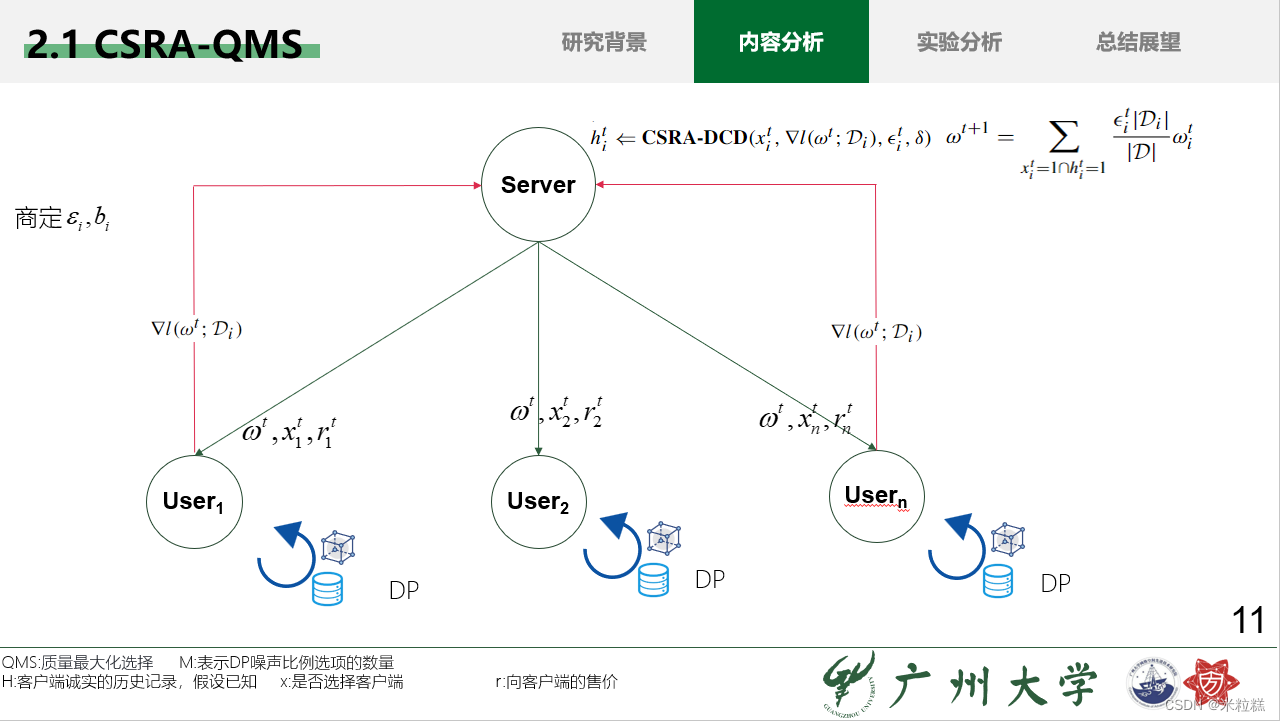
2.1 CSRA-QMS

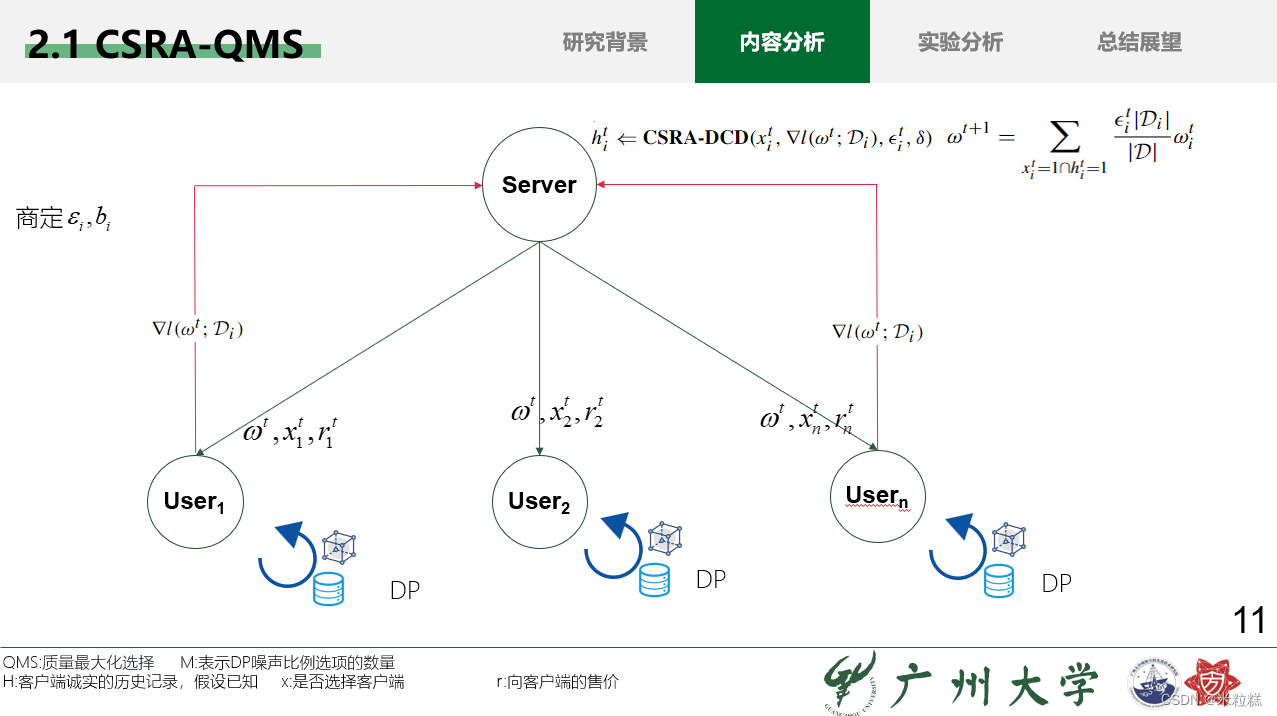
2.2 CSRA-DCD
总结
1.为了激发客户端参与联邦学习的积极性,作者使用了激励机制。
2.为了保护联邦学习,作者使用了差分隐私来保护。
3.现有FL激励机制存在缺陷,主要是由不诚实的客户端造成的,所以论文的目的就是要剔除不诚实的客户端,提出了逆向拍卖客户选择(CSRA),使用QMS(质量最大化选择)来选择前k个客户端进行联邦学习,使用DCD(不诚实客户端检测)检测不诚实的客户端,分两步走,粗粒度检测:初步判断有哪些不诚实的客户端;
细粒度检测:最终判断有哪些不诚实的客户端。最后,服务器剔除不诚实的客户端进行全局模型更新,直到全局模型收敛为止。
Yang Y, Hu M, Zhou Y, et al. CSRA: Robust Incentive Mechanism Design for Differentially Private Federated Learning[J]. IEEE Transactions on Information Forensics and Security, 2023.















 1601
1601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









