







 该文介绍了如何加载腾讯AILab的预训练中文词向量到gensim,并将其转换为.bin文件以加快加载速度。接着,文章展示了如何构建词与向量的映射关系,并将它们保存,以便后续使用。最后,演示了如何将预训练的词向量集成到PyTorch的Embedding层,并给出一个寻找最相似词的例子。
该文介绍了如何加载腾讯AILab的预训练中文词向量到gensim,并将其转换为.bin文件以加快加载速度。接着,文章展示了如何构建词与向量的映射关系,并将它们保存,以便后续使用。最后,演示了如何将预训练的词向量集成到PyTorch的Embedding层,并给出一个寻找最相似词的例子。
本文主要介绍如何使用预训练好的词向量,本文以腾讯AI Lab预训练中文词向量为例,本文使用到的python包为gensim
1. 将词向量载入gensim模块
# tencent 预训练的词向量文件路径
vec_path = "/share_v3/fangcheng/data/Tencent_AILab_ChineseEmbedding.txt"
# 加载词向量文件
wv_from_text = gensim.models.KeyedVectors.load_word2vec_format(vec_path, binary=False)
上面vec_path: 词向量文档所在的地址,比如上述腾讯词向量下载后的本地地址
binary: 如果为真,表示数据是否为二进制word2vec格式。默认为False。
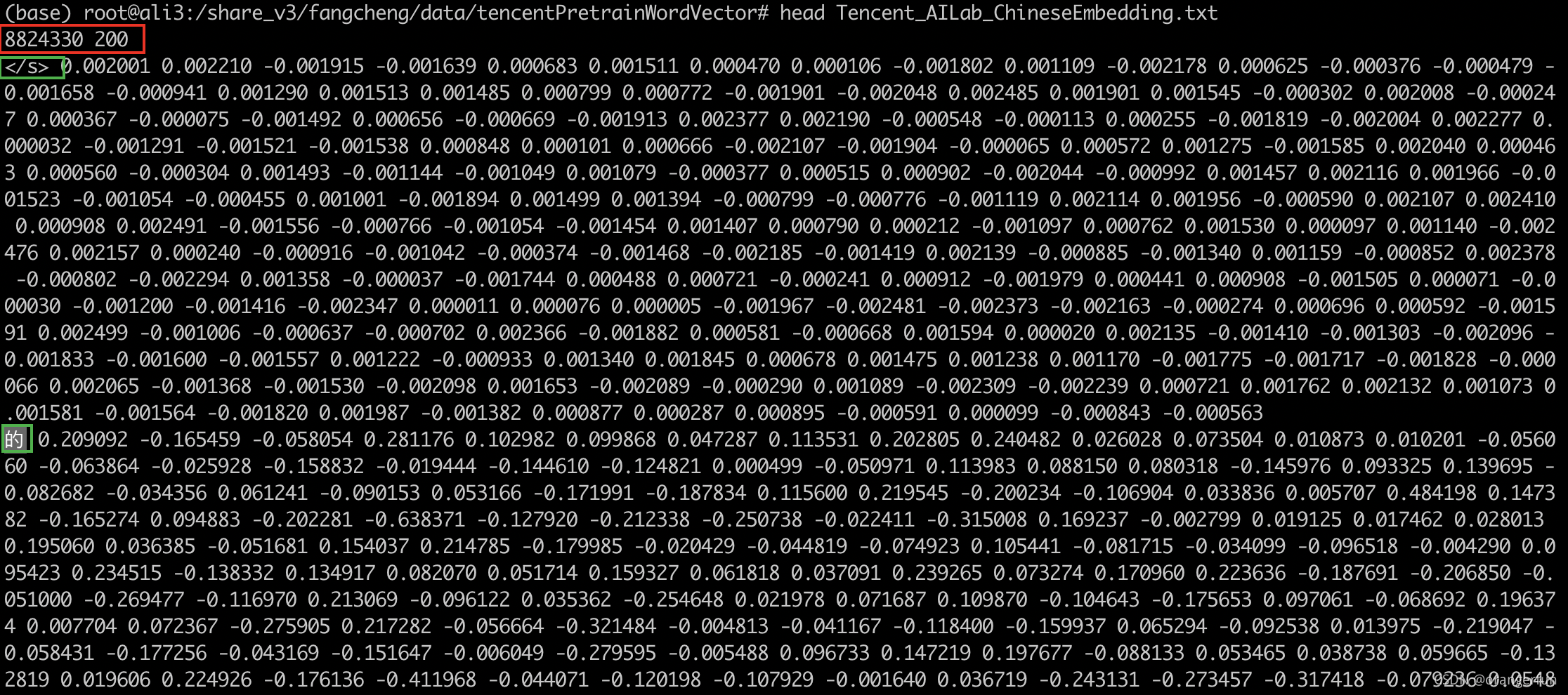
使用下载好的预训练词向量或自己本地的预训练词向量载入gensim模块。需要保证文本的最开头一行保存整个词表的大小和维度,比如Tencent AI Lab预训练词向量,如下图所示共有8824330个词,每个词是一个200维向量,都是用空格分割
上面的方法加载词向量文件速度很慢,在第一次加载时,可以将模型以.bin文件保存,方便后续的多次加载,可以提高加载速度
# 加载词向量文件
wv_from_text = gensim.models.KeyedVectors.load_word2vec_format(vec_path, binary=False)
# 如果每次都用上面的方法加载,速度非常慢,可以将词向量文件保存成bin文件,以后就加载bin文件,速度会变快
wv_from_text.init_sims(replace=True)
wv_from_text.save(vec_path.replace(".txt", ".bin"))
# 之后可以用下面的方式加载词向量
# wv_from_text = gensim.models.KeyedVectors.load(embed_path, mmap='r')
2. 获取所有词、向量并构建idx2word和word2idx
# 获取所有词
vocab = wv_from_text.vocab
# 获取所有向量
word_embedding = wv_from_text.vectors
# 将向量和词保存下来
word_embed_save_path = "/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/emebed.ckpt"
word_save_path = "/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/word.ckpt"
np.save(word_embed_save_path, word_embedding)
pd.to_pickle(vocab, word_save_path)
# 加载保存的向量和词
weight_numpy = np.load(file="/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/emebed.ckpt.npy")
vocab = pd.read_pickle(word_save_path)
word2idx = {word: idx for idx, word in enumerate(vocab)}
idx2word = {idx: word for idx, word in enumerate(vocab)}
pd.to_pickle(word2idx, "/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/word2idx.ckpt")
pd.to_pickle(idx2word, "/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/idx2word.ckpt")
3. 加载向量用于模型
# 加载
embedding =torch.nn.Embedding.from_pretrained(torch.FloatTensor(weight_numpy))
4. 完整程序
import gensim
import numpy as np
import pandas as pd
import torch
# tencent 预训练的词向量文件路径
# vec_path = "/share_v3/fangcheng/data/Tencent_AILab_ChineseEmbedding.txt"
# 加载词向量文件
# wv_from_text = gensim.models.KeyedVectors.load_word2vec_format(vec_path, binary=False)
# 如果每次都用上面的方法加载,速度非常慢,可以将词向量文件保存成bin文件,以后就加载bin文件,速度会变快
# wv_from_text.init_sims(replace=True)
# wv_from_text.save(vec_path.replace(".txt", ".bin"))
# embed_path = "/share_v3/fangcheng/data/tencentPretrainWordVector/Tencent_AILab_ChineseEmbedding.bin"
# wv_from_text = gensim.models.KeyedVectors.load(embed_path, mmap='r')
# 获取所有词
# vocab = wv_from_text.vocab
# 获取所有向量
# word_embedding = wv_from_text.vectors
# 将向量和词保存下来
# word_embed_save_path = "/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/emebed.ckpt"
# word_save_path = "/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/word.ckpt"
# np.save(word_embed_save_path, word_embedding)
# pd.to_pickle(vocab, word_save_path)
# 加载保存的向量和词
# weight_numpy = np.load(file="/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/emebed.ckpt.npy")
# vocab = pd.read_pickle(word_save_path)
# word2idx = {word: idx for idx, word in enumerate(vocab)}
# idx2word = {idx: word for idx, word in enumerate(vocab)}
# pd.to_pickle(word2idx, "/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/word2idx.ckpt")
# pd.to_pickle(idx2word, "/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/idx2word.ckpt")
# 加载
# embedding =torch.nn.Embedding.from_pretrained(torch.FloatTensor(weight_numpy))
# print("\n")
# 由于上方文件都保存了,因此使用时直接加载即可
embed_path = "/share_v3/fangcheng/data/tencentPretrainWordVector/Tencent_AILab_ChineseEmbedding.bin"
wv_from_text = gensim.models.KeyedVectors.load(embed_path, mmap='r')
weight_numpy = np.load(file="/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/emebed.ckpt.npy")
embedding =torch.nn.Embedding.from_pretrained(torch.FloatTensor(weight_numpy))
word2idx = pd.read_pickle("/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/word2idx.ckpt")
idx2word = pd.read_pickle("/share_v3/fangcheng/dev/instruction_intent_parse/intent_classify/intent_functional/data/idx2word.ckpt")
sentences = ["我","爱", "北京","天安门"]
ids = torch.LongTensor([word2idx[item] for item in sentences])
wordvector = embedding(ids)
print(wordvector.shape)
# 使用gensim找最相近的词
most_similar = wv_from_text.most_similar(["关灯", "爱"], topn=10)
print(most_similar)
output
torch.Size([4, 200])
[('所以爱', 0.7189082503318787), ('关了灯', 0.7077323794364929), ('就是爱', 0.706206202507019), ('不爱', 0.7062050104141235), ('但爱', 0.6981735825538635), ('是爱', 0.6953357458114624), ('因为爱', 0.6937851905822754), ('爱的', 0.6930142045021057), ('我们爱', 0.6921308636665344), ('开灯', 0.686741054058075)]


















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









