







 本文介绍了如何利用平均感知机算法进行词性标注。通过训练数据,使用平均感知机模型进行词性预测,涉及特征提取、权值更新和预处理步骤。在实验部分,对比了模型在不同语料上的准确率。
本文介绍了如何利用平均感知机算法进行词性标注。通过训练数据,使用平均感知机模型进行词性预测,涉及特征提取、权值更新和预处理步骤。在实验部分,对比了模型在不同语料上的准确率。
平均感知机算法(Averaged Perceptron)
感知机算法是非常好的二分类算法,该算法求取一个分离超平面,超平面由w参数化并用来预测,对于一个样本x,感知机算法通过计算y = [w,x]预测样本的标签,最终的预测标签通过计算sign(y)来实现。算法仅在预测错误时修正权值w。
平均感知机和感知机算法的训练方法一样,不同的是每次训练样本xi后,保留先前训练的权值,训练结束后平均所有权值。最终用平均权值作为最终判别准则的权值。参数平均化可以克服由于学习速率过大所引起的训练过程中出现的震荡现象。
词性标注
词性标注是一个监督学习。先读入训练预料,利用平均感知机算法训练得到tagging模型,并存储在硬盘上。当需要进行词性预测时,首先从硬盘上加载tagging模型,再读入测试语料,进行自动标注。
过程说明
1、为了存储权值weights,建立了一个双层的字典,保存了特征->词性类别->权重,结构如图:
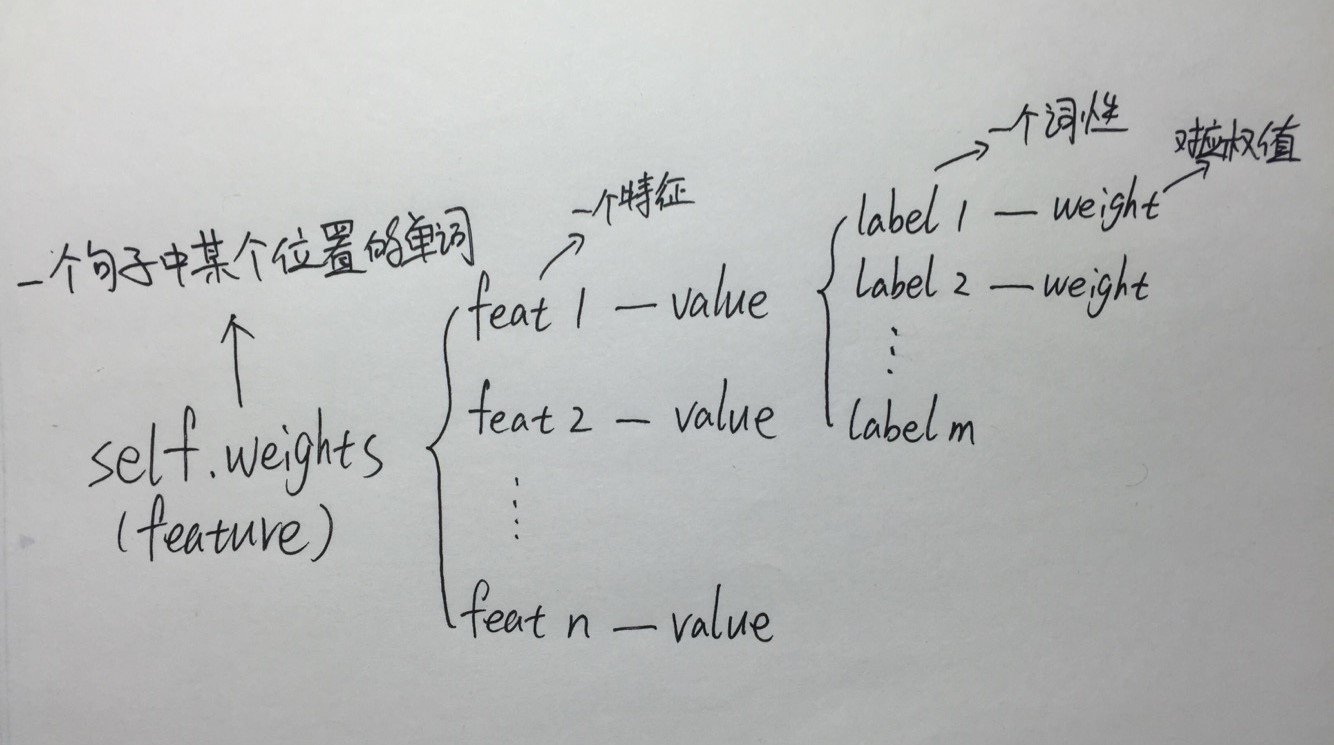
2、从语料库中读取单词,当读取到”.”时,代表是一个句子的结尾,将前面的若干单词组成为一句话,形成一个sentence,存储在二元组中:例如([‘good’,’man’],[‘adj’,’n’])第一个列表是句子中的单词,第二个列表是单词对应的词性。语料库中的所有句子存储在列表training_data中(sentences),形如[ ([ ],[ ]), ([ ],[ ]), ([ ],[ ]) 。。。]
3、模型训练过程中,权值的更新是通过将(特征,正确词性)对应的特征权值+1,并且将(特征,错误词性)对应的特征权值-1。不仅增加正确词性对应的权值,还要惩罚错误词性对应的权值。
4、为了训练一个更通用的模型,在特征提取之前对数据进行预处理:
- 所有英文词语都转小写
- 四位数字并且在1800-2100之间的数字被转义为!YEAR
- 其他数字被转义为!DIGITS
- 当然还可以写一个专门识别日期、电话号码、邮箱等的模块,但目前先不拓展这部分
5、对第i个单词进行特征提取:
- 单词的首字母
- 单词的后缀
- 第i-1个单词的词性
- 第i-1个单词的后缀
- 第i-2个单词的词性
- 第i-2个单词的后缀
- 第i+1个单词的词性,等等
实验
代码1:
AP_algorithm.py
# -*- coding:utf-8 -*-
# 平均感知机算法Averaged Perceptron:训练结束后平均所有权值,使用平均权值作为最终的权值
from collections import defaultdict
import pickle
class AveragedPerceptron(object):
def __init__(self):
# 每个'位置'拥有一个权值向量
self.weights = {}
self.classes = set()
# 累加的权值,用于计算平均权值
self._totals = defaultdict(int) # 生成了一个默认为0的带key的数据字典
self._tstamps = defaultdict(int) # 上次更新权值时的i
self.i = 0 # 记录实例的数量
def predict(self, features): # 特征向量乘以权值向量,返回词性标签
scores = defaultdict(float)
for feat, value in features.items():
if feat not in self.weights or value == 0:
continue
weights = self.weights[feat]
for label, weight in weights.items():
scores[label] += value * weight
# 返回得分最高的词性
return max(self.classes, key=lambda label: (scores[label], label)) # 返回得分最高的词性标签,如果得分相同取字母大的
def update(self, truth, guess, features): # 更新权值
def upd_feat(c, f, w, v): # c:正确的(或预测的)词性; f:feat某个特征; w:对应c的权值; v:1(或-1)
param = (f, c)
self._totals[param] += (self.i - self._tstamps[param]) * w # 累加:(此时的i - 上次更新该权值时的i)*权值
self._tstamps[param] = self.i # 记录更新此权值时的i
self.weights[f][c] = w + v # 更新权值
self.i += 1
if truth == guess: # 如果预测正确,不做更新
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









