







 这篇博客介绍了如何使用Keras构建Attention Model进行Aspect level的情感分析。通过Attention机制,模型能更好地捕捉与特定aspect相关的重要上下文信息,从而提升情感分析的准确性。实验结果显示,加入Attention层的模型相比仅使用CNN、LSTM或fasttext有更好的表现。
这篇博客介绍了如何使用Keras构建Attention Model进行Aspect level的情感分析。通过Attention机制,模型能更好地捕捉与特定aspect相关的重要上下文信息,从而提升情感分析的准确性。实验结果显示,加入Attention层的模型相比仅使用CNN、LSTM或fasttext有更好的表现。
1、关于aspect level的情感分析
给定一个句子和句子中出现的某个aspect,aspect-level 情感分析的目标是分析出这个句子在给定aspect上的情感倾向。
例如:great food but the service was dreadful! 在aspect “food”上,情感倾向为正,在aspect “service”上情感倾向为负。Aspect level的情感分析相对于document level来说粒度更细。
2、关于attention model
使用传统的神经网络模型能够捕捉背景信息,但是不能明确的区分对某个aspect更重要的上下文信息。为了解决这个问题,引入attention捕获对于判断不同aspect的情感倾向较重要的信息。
3、模型的示意图
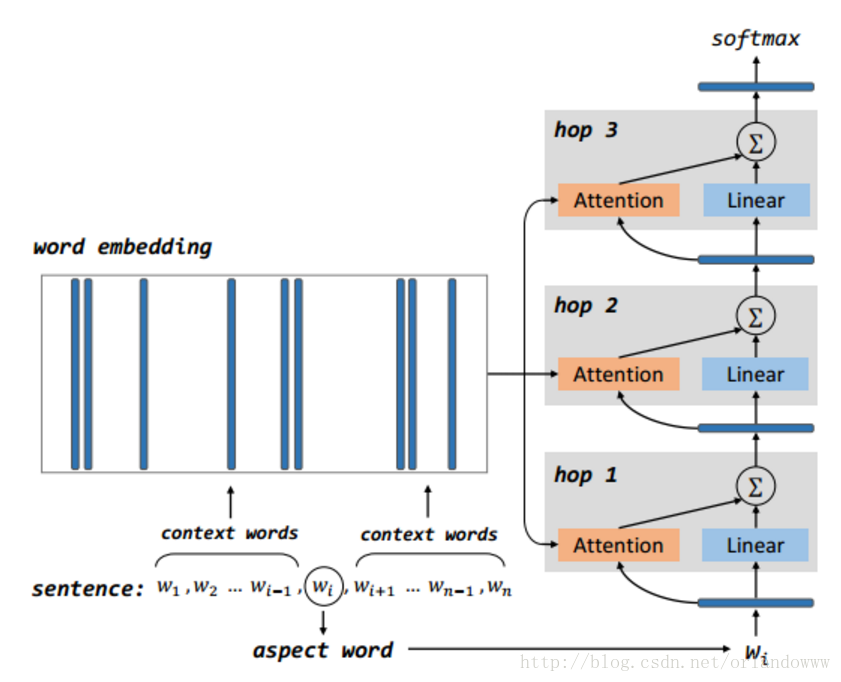
- 模型包括多个computational layers,每个computational layer包括一个attention layer和一个linear layer。
- 第一个computational layer,attention layer的输入是aspect vector,输出memory中的比较重要的部分,linear layer的输入是aspect vector。第一个computational layer的attention layer和linear layer的输出结果求和作为下一个computational layer的输入。
- 其它computational layer执行同样的操作,上一层的输出作为输入,通过attention机制获取memory中较重要的信息,与线性层得到的结果求和作为下一层的输入。
- 最后一层的输出作为结合aspect信息的sentence representation,作为aspect-level情感分类的特征,送到softmax。
4、深度学习框架Keras
Keras是一个高层神经网络库,Keras由纯Python编写而成并基Tensorflow或Theano。Keras 为支持快速实验而生,能够把idea迅速转换为结果。
具体可查看官方的中文文档写的很详细。
5、大概流程
读取数据集 –> 分词 –> 将所有词排序并标号 –> 词嵌入 –> Attention Model –> 编译 –> 训练+测试
6、参数设置
- 句子最大长度:80
- 词向量维度:300
- 梯度下降batch:32
- 总迭代次数: 5
实验代码:
# -*- coding: utf-8 -*-
import csv
import jieba
jieba.load_userdict('wordDict.txt')
import pandas as pd
from keras.preprocessing import sequence
from keras.utils import np_utils
from keras.models import *
from keras.optimizers import *
from keras.layers.core import *
from keras.layers import Input,merge, TimeDistributed
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.embeddings import 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









