







1. RNNs (Recurrent Neural Networks)
参考:https://blog.csdn.net/Jerr__y/article/details/58598296
https://www.yunaitong.cn/understanding-lstm-networks.html
以上两篇均是翻译:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
另外,参考了《Tensorflow实战google深度学习框架》这本书
以下是自己简要的学习笔记和理解。
1.1 RNNs的结构
- 起源:传统的神经网络不能够基于前面的信息来推断接下来的信息。
- RNNs的网络结构:
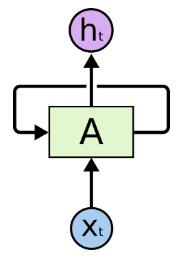
网络中的循环结构使得某个时刻的状态能够传到下一个时刻,即可以实现信息的持久化。因此,循环神经网络的主要用途是处理和预测序列数据。
把 RNNs 在时间步上进行展开,可以得到下图:
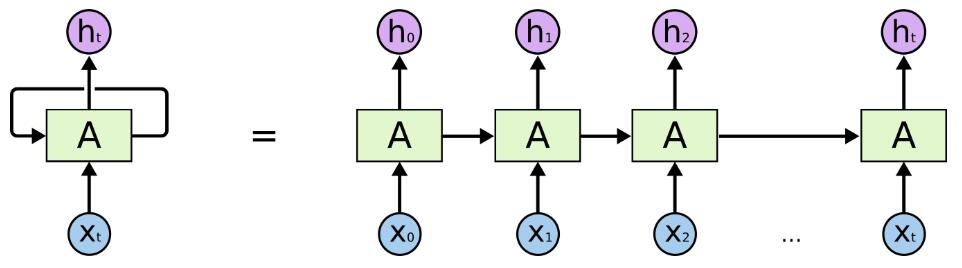
- RNN网络要点
- 循环神经网络是在不同时间位置共享参数,从而能够使用有限的参数处理任意长度的序列。
- 循环神经网络要求每个时刻都有一个输入,但是不一定每个时刻都需要有输出。
- 循环神经网络的总损失为所有时刻(或者部分时刻)的损失函数总和。
1.2 缺点
RNNs能够把以前的信息联系到现在,从而解决现在的问题。但是,随着预测信息和相关信息间的间隔增大, RNNs 很难去把它们关联起来了。从理论上来讲,通过选择合适的参数,RNNs 确实是可以把这种长时期的依赖关系 (“long-term dependencies”) 联系起来,并解决这类问题的。但遗憾的是在实际中, RNNs 无法解决这个问题。如果序列过长,一方面会出现梯度消散或梯度爆炸的问题,另一方面,展开后的前馈神经网络会占用过大的内存。因此,实际中一般会规定一个最大长度,当序列长度超过规定长度后进行截断。幸运的是,LSTMs能够比较好的解决长期依赖问题。
2. LSTMs (Long Short Term Memory networks)
2.1 LSTM的网络结构
- 长短期记忆网络(LSTMs)是 RNN 中一个特殊的类型。由Hochreiter & Schmidhuber于1997年提出。
- 它的本质就是能够记住很长时期内的信息。
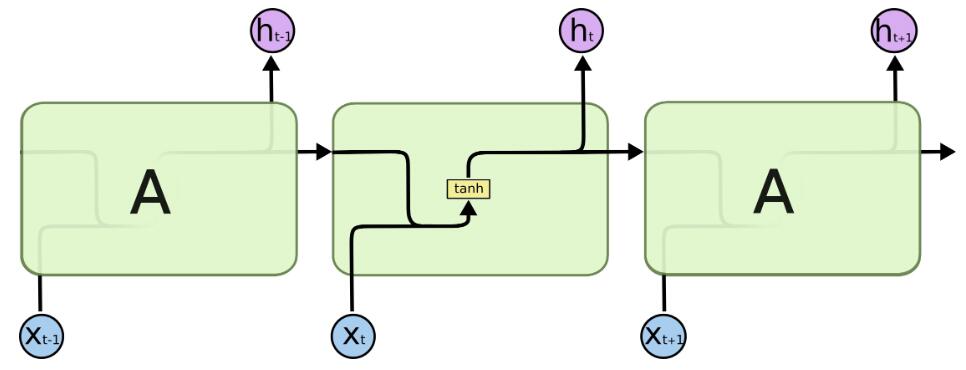
- LSTMs的每一个模块中有4个神经网络层。
- 图中元素说明:

a. 黄色方框表示神经网络的层。b. 粉红圆表示向量的元素级操作,比如相加或者相乘。c. 每条线表示向量的传递,从一个结点的输出传递到另外结点的输入。d. 线条合并表示向量的连接。e. 线条分叉表示向量的复制。
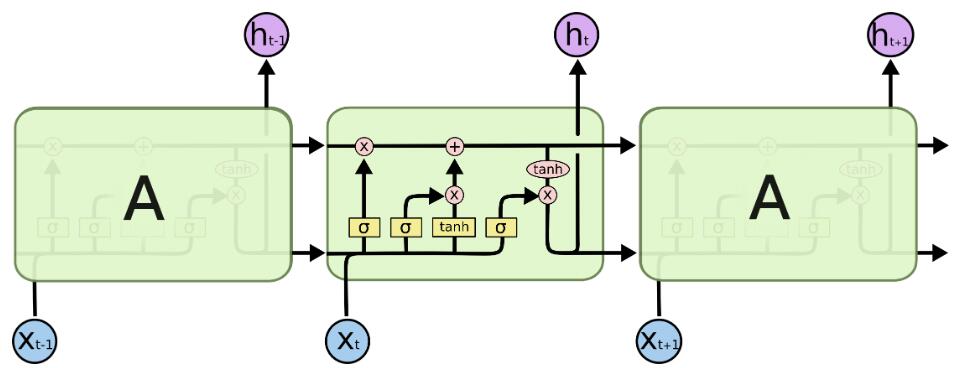
2.2 LSTM核心思想
LSTMs的核心是元胞状态 (Cell State),下图中横穿整个元胞顶部的水平线表示元胞状态的流动。LSTMs通过一种叫门的结构控制元胞状态信息的添加或者删除。每个门中包含一个sigmoid神经网络层,控制信息通过的比例。
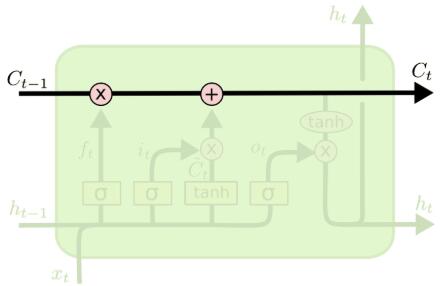
2.3 LSTM分布解析
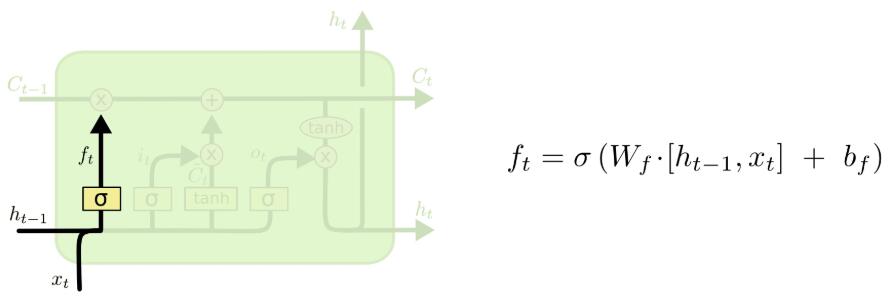
- (1) 遗忘门
表示让对应信息通过的权重,决定让哪些信息通过这个Cell。
- (2) 输入门
决定让多少新的信息加入到cell状态中来。 i t i_t it 决定哪些信息更新, C ~ t \widetilde{C}_t C t表示备选的用来更新的内容。
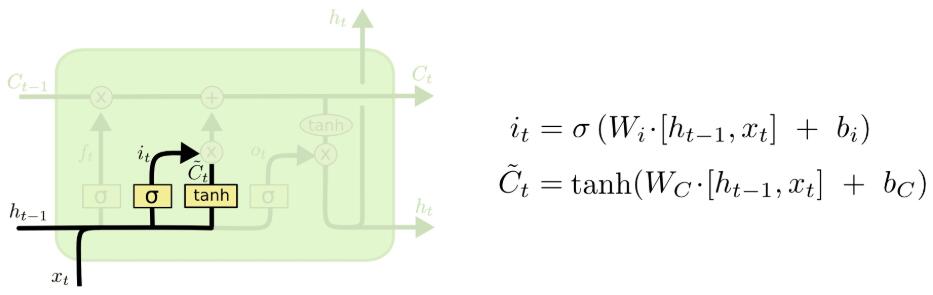
此时,元胞状态的更新为: C t = C t − 1 ∗ f t + i t ∗ C ~ t C_t=C_{t-1}*f_t+i_t*\widetilde{C}_t Ct=Ct−1∗ft+it∗C t.
- (3) 输出门
决定输出什么值。
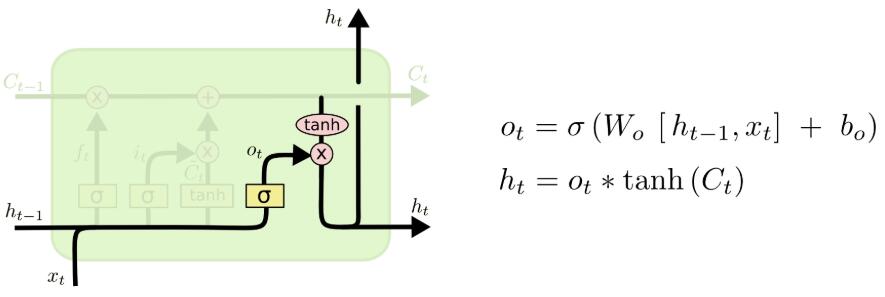
3. GRU (Gated Recurrent Unit)
- 2014年提出。
3.1 GRU的结构及工作原理
- GRU的网络结构
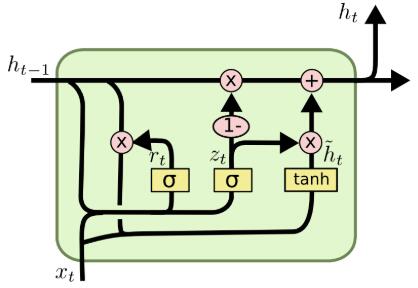
- 重置门 (reset gate)
GRU的重置门合并了LSTMs中的遗忘门和传入门,同时合并了元胞状态和隐藏状态。
r t = σ ( W r ⋅ [ h t − 1 , x t ] ) r_t=\sigma(W_r\cdot[h_{t-1},x_t]) rt=σ(Wr⋅[ht−1,xt])
隐藏状态: h ~ t = t a n h ( W ⋅ [ r t ∗ h t − 1 , x t ] ) \widetilde{h}_t=tanh(W\cdot[r_t*h_{t-1},x_t]) h t=tanh(W⋅[rt∗ht−1,xt]) - 更新门 (update gate)
z t = σ ( W z ⋅ [ h t − 1 , x t ] ) z_t=\sigma(W_z\cdot[h_{t-1},x_t]) zt=σ(Wz⋅[ht−1,xt])
h t = ( 1 − z t ) ∗ h t − 1 + z t ∗ h ~ t h_t=(1-z_t)*h_{t-1}+z_t*\widetilde{h}_t ht=(1−zt)∗ht−1+zt∗h t
4. 双向循环神经网络
以上介绍的循环神经网络考虑了前文的信息,但很多时候,当前时刻的输出不仅和前文有关也和后文有关。
https://blog.csdn.net/SunJW_2017/article/details/82837072
《TensorFlow实战google深度学习框架》
4.1 双向RNN
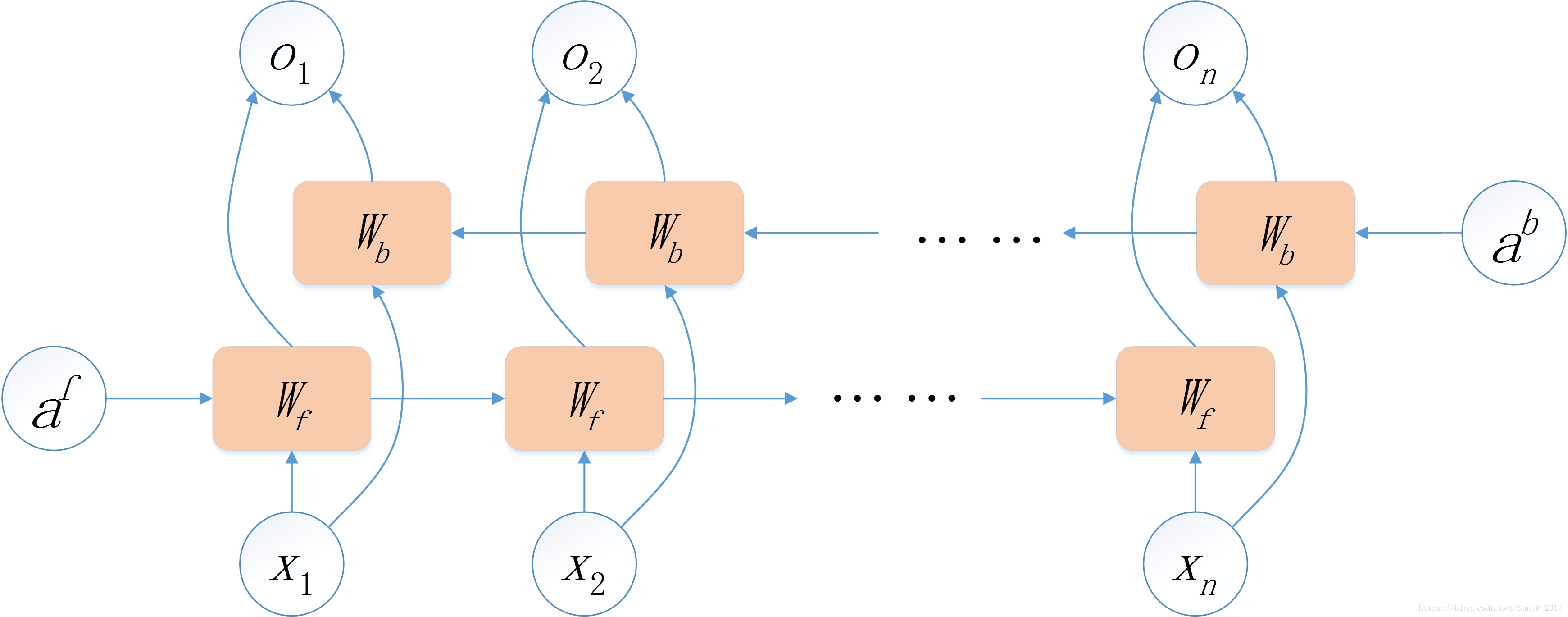
- BiRNN (双向RNN):Bi-directional RNN.
- 网络结构:双向RNN的主体结构就是两个单向RNN的结合,一个RNN接收序列的顺序输入,一个RNN接收序列的逆序输入,最终输出是这两个单向RNN输出的简单拼接。其网络结构如下图所示:
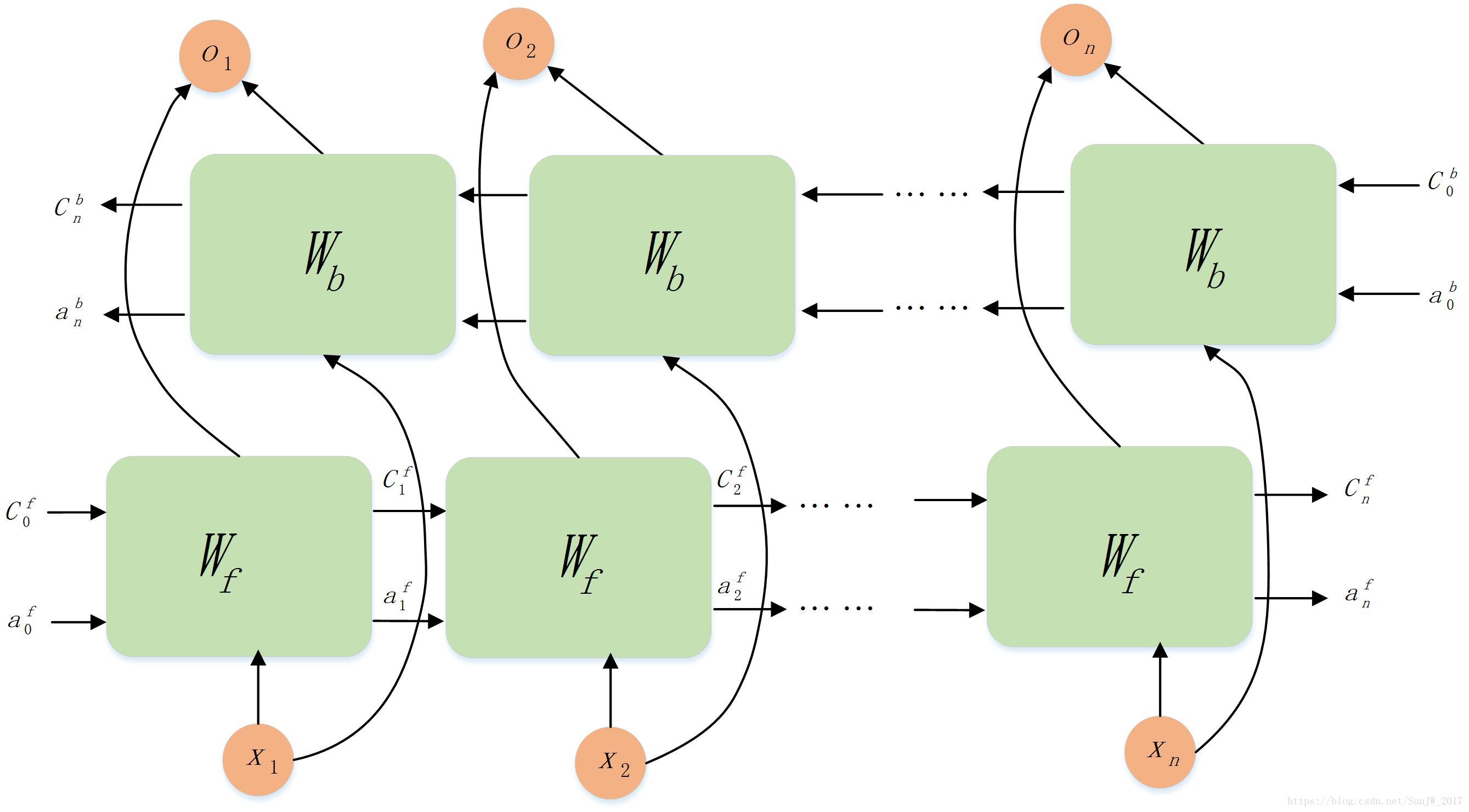
4.2 双向LSTM
- 原理与BiRNN类似,其网络结构如下所示:
5. 循环神经网络用于文本分类
5.1 textRNN
- 优点:适合处理序列信息。
- 缺点:串行运行,速度慢。
- 论文:Recurrent Neural Network for Text Classification with Multi-Task Learning
- 网络结构:一般的网络结构如下图所示,
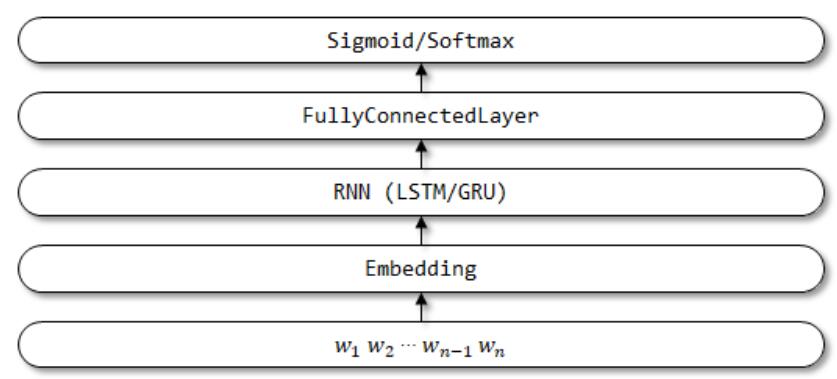
- 从RNN获取文本特征的策略:
(1) 直接使用RNN结构最后一个单元的输出向量作为文本的特征。
(2) 将所有RNN单元的输出向量的均值pooling或者max-pooling作为文本特征。
(3) 使用BiRNN两个方向的输出向量的连接 (concatenate) 或均值作为文本特征。
(4) 层次RNN+Attention (Hierarchical Attention Networks)。 - 模型函数调用:lstm=LSTM(128)(embedding),128为隐向量的维度。
5.2 textBiRNN
- 模型函数调用:biLstm=Bidirectional(LSTM(128))(embedding),128为隐向量的维度。
- 网络结构:与textRNN类似,将RNN换成Bidirectional RNN即可。















 8846
8846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









