






雄哥写过不少本地部署教程,包括llama2、chatglm2等等!
傻瓜式!一键部署llama2+chatglm2,集成所有环境和微调功能,本地化界面操作!
【llama2】真正喂饭到嘴部署教程!中文版0基础手把手,懂技术的别看
【妈妈级】清华ChatGLM2-6B本地部署搭建及测试运行,0基础小白也学得会
最近!Qwen-14B和7B开源发布,雄哥团队第一时间部署测试,分数的确比chatglm2-6B更好!qwen毕竟多了3个月做训练,达到这个效果也是情理之中!
群里很多小伙伴问怎么部署,雄哥决定再写一个0基础的本地部署教程,主打的就是喂饭到嘴!
我们“0基础微调大模型+知识库,部署到微信”的项目也在稳步推进中!
※部署过程非常的简单!2步搞掂!
一、环境安装配置:①创建环境;②安装依赖;③下载权重;
二、权重部署量化:①修改配置文件;②量化版本;③启动模型;
本教程所有用到的文件,已经打包喂到嘴了!
公号后台回复“qwen”下载;
第一部分:环境配置
1.1 创建环境
这里我们要用到Miniconda,昨天雄哥已经发了详细的安装配置教程啦:
第四天!0基础微调大模型+知识库,部署在微信!手把手安装AI必备环境!4/45
这里,我们要创建一个新的环境,我们打开Miniconda的命令窗口
conda create -n model310 python=3.10很多0基础的伙伴,雄哥说说代码干了啥!环境名称“model310”,指定Python版本“3.10”
用下面代码激活环境,之后所有操作仅在这个环境内!
conda activate model310改一下环境变量,更改环境的默认下载路径,根据自己需求来
SET TRANSFORMERS_CACHE=%ROOT%\models跟着雄哥上面第四天的教程,安装好环境,雄哥的环境是:
1.python版本3.10
2.CUDA版本12.2
3.pytorch版本2.0.1

1.2 安装依赖
首先让他所有的下载都放在D盘根目录,输入以下指令回车!
D:这里下载qwen官方仓库,如果你下载失败或不能访问GitHub,这时你在公号后台回复“qwen”就能百度网盘下载了,解压到D盘根目录即可;
git clone https://github.com/QwenLM/Qwen.git然后安装modelscope基础库
pip install modelscope
然后安装量化依赖
pip install auto-gptq optimum
然后安装量化包
pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui
安装其他依赖,这里不解释了,跟着下载安装即可
pip install transformers_stream_generatorpip install tiktokenpip install deepspeed安装flash-attention库,这个库可以节省显存花销!
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention下载完之后,进入目录进行安装!
cd flash-attentionpip install .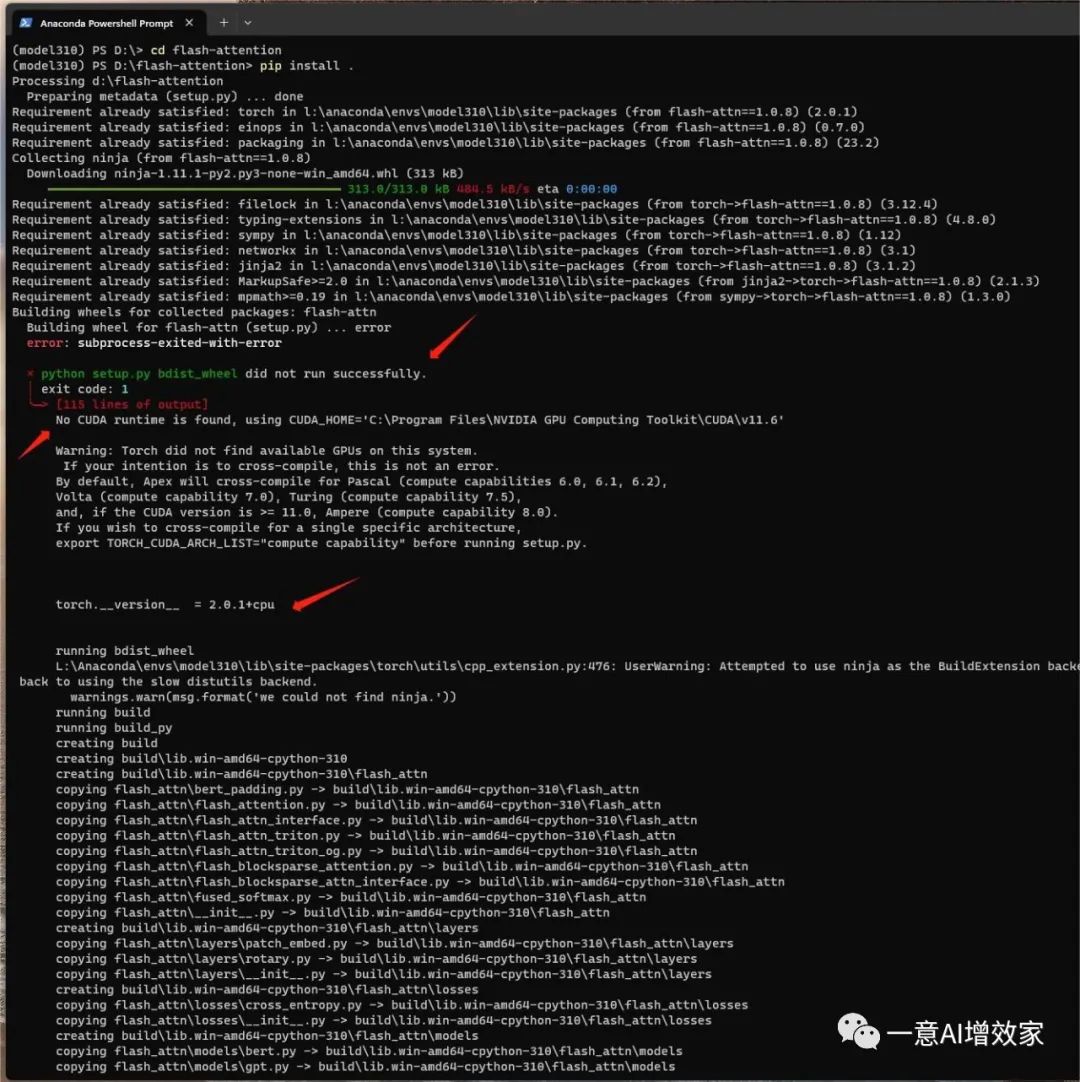
如果上面安装报错了!那应该是pytorch版本不对!
这时要用conda安装pytorch 2.0的CUDA版本!
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
安装完之后,你可以验证装没装成功
pythonimport torch#pytorch的版本torch.__version__#是否支持CUDAtorch.cuda.is_available()#CUDA的版本print(torch.version.cuda)#cuDNN的版本print(torch.backends.cudnn.version())#GPU内存torch.cuda.get_device_capability(device=0)

然后重新安装一下
pip install .最终,你在雄哥网盘下载的文件,应该是这样的!
检查一下!我们准备启动了!

第二部分:改配置文件+启动
到了这一步,如果你直接启动,大概率是失败的!因为可能每个人的基座路径不一样,这里雄哥贴出cli_demo.py的代码,根据自己的需求修改即可;
# Copyright (c) Alibaba Cloud.## This source code is licensed under the license found in the# LICENSE file in the root directory of this source tree."""A simple command-line interactive chat demo."""import argparseimport osimport platformimport shutilfrom copy import deepcopyfrom transformers import AutoModelForCausalLM, AutoTokenizerfrom transformers.generation import GenerationConfigfrom transformers.trainer_utils import set_seedDEFAULT_CKPT_PATH = './Qwen/Qwen-7B-Chat-Int4'_WELCOME_MSG = '''\Welcome to use Qwen-Chat model, type text to start chat, type :h to show command help.(欢迎使用 Qwen-Chat 模型,输入内容即可进行对话,:h 显示命令帮助。)Note: This demo is governed by the original license of Qwen.We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, including hate speech, violence, pornography, deception, etc.(注:本演示受Qwen的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。)'''_HELP_MSG = '''\Commands::help / :h Show this help message 显示帮助信息:exit / :quit / :q Exit the demo 退出Demo:clear / :cl Clear screen 清屏:clear-his / :clh Clear history 清除对话历史:history / :his Show history 显示对话历史:seed Show current random seed 显示当前随机种子:seed <N> Set random seed to <N> 设置随机种子:conf Show current generation config 显示生成配置:conf <key>=<value> Change generation config 修改生成配置:reset-conf Reset generation config 重置生成配置'''def _load_model_tokenizer(args):tokenizer = AutoTokenizer.from_pretrained(args.checkpoint_path, trust_remote_code=True, resume_download=True,)if args.cpu_only:device_map = "cpu"else:device_map = "auto"model = AutoModelForCausalLM.from_pretrained(args.checkpoint_path,device_map=device_map,trust_remote_code=True,resume_download=True,).eval()config = GenerationConfig.from_pretrained(args.checkpoint_path, trust_remote_code=True, resume_download=True,)return model, tokenizer, configdef _clear_screen():if platform.system() == "Windows":os.system("cls")else:os.system("clear")def _print_history(history):terminal_width = shutil.get_terminal_size()[0]print(f'History ({len(history)})'.center(terminal_width, '='))for index, (query, response) in enumerate(history):print(f'User[{index}]: {query}')print(f'QWen[{index}]: {response}')print('=' * terminal_width)def _get_input() -> str:while True:try:message = input('User> ').strip()except UnicodeDecodeError:print('[ERROR] Encoding error in input')continueexcept KeyboardInterrupt:exit(1)if message:return messageprint('[ERROR] Query is empty')def main():parser = argparse.ArgumentParser(description='QWen-Chat command-line interactive chat demo.')parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,help="Checkpoint name or path, default to %(default)r")parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")args = parser.parse_args()history, response = [], ''model, tokenizer, config = _load_model_tokenizer(args)orig_gen_config = deepcopy(model.generation_config)#_clear_screen()print(_WELCOME_MSG)seed = args.seedwhile True:query = _get_input()# Process commands.if query.startswith(':'):command_words = query[1:].strip().split()if not command_words:command = ''else:command = command_words[0]if command in ['exit', 'quit', 'q']:breakelif command in ['clear', 'cl']:_clear_screen()print(_WELCOME_MSG)continueelif command in ['clear-history', 'clh']:print(f'[INFO] All {len(history)} history cleared')history.clear()continueelif command in ['help', 'h']:print(_HELP_MSG)continueelif command in ['history', 'his']:_print_history(history)continueelif command in ['seed']:if len(command_words) == 1:print(f'[INFO] Current random seed: {seed}')continueelse:new_seed_s = command_words[1]try:new_seed = int(new_seed_s)except ValueError:print(f'[WARNING] Fail to change random seed: {new_seed_s!r} is not a valid number')else:print(f'[INFO] Random seed changed to {new_seed}')seed = new_seedcontinueelif command in ['conf']:if len(command_words) == 1:print(model.generation_config)else:for key_value_pairs_str in command_words[1:]:eq_idx = key_value_pairs_str.find('=')if eq_idx == -1:print('[WARNING] format: <key>=<value>')continueconf_key, conf_value_str = key_value_pairs_str[:eq_idx], key_value_pairs_str[eq_idx + 1:]try:conf_value = eval(conf_value_str)except Exception as e:print(e)continueelse:print(f'[INFO] Change config: model.generation_config.{conf_key} = {conf_value}')setattr(model.generation_config, conf_key, conf_value)continueelif command in ['reset-conf']:print('[INFO] Reset generation config')model.generation_config = deepcopy(orig_gen_config)print(model.generation_config)continueelse:# As normal query.pass# Run chat.set_seed(seed)try:for response in model.chat_stream(tokenizer, query, history=history, generation_config=config):pass# _clear_screen()# print(f"\nUser: {query}")print(f"\nQwen-Chat: {response}")except KeyboardInterrupt:print('[WARNING] Generation interrupted')continuehistory.append((query, response))if __name__ == "__main__":main()
雄哥的网盘中有14B和7B的基座
你想启动哪个,直接覆盖基座文件,修改代码!
这是启动14B的!
DEFAULT_CKPT_PATH = 'Qwen/Qwen-14B-Chat-Int4'这是启动7B的!
DEFAULT_CKPT_PATH = 'Qwen/Qwen-7B-Chat-Int4'没问题了!这时,我们直接启动!
python cli_demo.py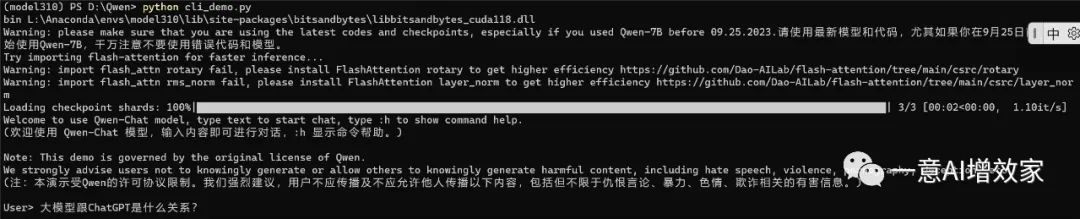
这时就可以正常推理了!
如果你需要用网页版的,可以直接用这个指令,安装gradio
pip install gradio mdtex2html安装后启动也很简单
python web_demo.py
出现任何报错,请到群反馈!

专注人工智能行业应用,AI学习搭档、专家模型训练微调、企业知识库搭建、AI产品认证与备案;
行业初期,希望更多人加入,推进行业发展!一意公众号四大功能!
#1 高质量数据集
我搭建了一个训练数据共享平台,目前已收录法律、金融、医疗、教育、诗词等超1T的人工标注数据集,还可以通过群内共享。
#2 报错或问题解决
你可能像我们NLP学习群中的同学一样,遇到各种报错或问题,我每天挑选5条比较有代表性的问题及解决方法贴出来,供大家避坑;每天更新,欢迎来蹲!
#3 运算加速
还有同学是几年前的老爷机/笔记本,显卡不好,我们应用了动态运输技术框架,直接提升超40%运算效率,无显卡2g内存就能跑,直接焕发第二春;
#4 微调训练教程
如果你还不知道该怎么微调训练模型,在这里还可以学训练和微调,跟着一步步做,你也能把大模型的知识真正应用到实处,产生价值。

















 3490
3490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











