









目录
4.判断一个值为/不为null(is null,is not null)
一.正则表达式(同shell脚本的正则表达式)
- MysQL正则表达式通常是在检索数据库记录的时候,根据指定的匹配模式匹配记录中符合要求的特殊字符串。
- MysQL的正则表达式使用REGEXP这个关键字来指定正则表达式的匹配模式
| 匹配模式 | 描述 |
|---|---|
| ^ | 匹配文本的开始字符 |
| $ | 匹配文本的结束字符 |
| . | 匹配任何单个字符 |
| * | 匹配零个或多个在它前面的字符 |
| + | 匹配前面的字符 1 次或多次 |
| ? | 匹配前面的字符 0或1 次 |
| 字符串 | 匹配包含指定的字符串 |
| p1Ip2 | 匹配 p1 或 p2 |
| […] | 匹配字符集合中的任意一个字符 |
| [^…] | 匹配不在括号中的任何字符 |
| {n} | 匹配前面的字符串 n 次 |
| {n,m} | 匹配前面的字符串至少 n 次,至多m 次 |
1.^以什么开头
(root@localhost) [oyyy]> select id,name from oyyy where name regexp '^a';

2.$以什么结尾
(root@localhost) [oyyy]> select id,name from oyyy where name regexp 'a$';

3."."代替任意一个字符
(root@localhost) [oyyy]> select id,name from oyyy where name regexp 'a.c';

4. 匹配前面字符多次
(root@localhost) [oyyy]> select id,name from oyyy where name regexp 'a*';

5. 匹配前面字符至少一次
(root@localhost) [oyyy]> select id,name from oyyy where name regexp 'a+';

6.匹配字符串
(root@localhost) [oyyy]> select id,name from oyyy where name regexp 'aa';

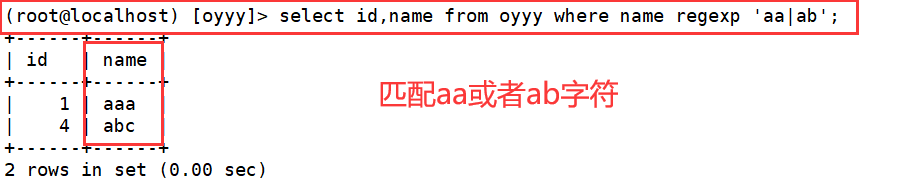
7. 匹配包含或者关系的记录
(root@localhost) [oyyy]> select id,name from oyyy where name regexp 'aa|ab';
8.匹配指定字符集中的任意一个
(root@localhost) [oyyy]> select id,name from oyyy where name regexp '[a,b]';

二.运算符
MysQL的运算符共有四种,分别是:算术运算符、比较运算符、逻辑运算符和位运算符。
1.算数运算
- 在除法运算中,除数不能为0,若除数是0,则返回的结果为 null 。
- 如果有多个运算符,按照先乘除后加减的优先级进行运算,相同优先级的运算,没有先后顺序
| 运算符 | 描述 |
|---|---|
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| / | 除法 |
| % | 取余 |
 2.比较运算符
2.比较运算符
字符串的比较默认不区分大小写,可使用 binary 来区分
| 常用比较运算符 | 说明 |
|---|---|
| = | 等于 |
| !=或<> | 不等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| is null | 判断是否为null |
| is not null | 判断是否不为null |
| between and | 两者之间 |
| greatest | 两个或多个参数时返回最大值 |
| least | 两个或多个参数时返回最小值 |
| in | 在集合中 |
1.等于
- 等号(=)用来判断数字、字符串和表达式是否相等的,如果相等则返回1,如果不相等则返回0。
- 如果比较的两者有一个值是NULL,则比较的结果就是NULL。
- 其中字符的比较是根据ASCII码来判断的,如果ASCIl码相等,则表示两个字符相同;如果ASCII码不相等,则表示两个字符不相同。例如字符串(字母)比较: (‘a’ > ‘b’)其实比较的是底层ASCll码需要关注的ASCII码有:a、A、0

- 如果两者都是整数,则按照整数值进行比较。
- 如果一个整数一个字符串,则会自动将字符串转换为数字,再进行比较。
- 如果两者都是字符串,则按照字符串进行比较。
- 如果两者中至少有一个值是NULL,则比较的结果是NULL
2.不等于(!=或<>)
- 用于针对数字、字符串和表达式不相等的比较,如果不相等则返回1,如果相等则返回0
- 不等于(!=,<>)无法用于判断是否为null

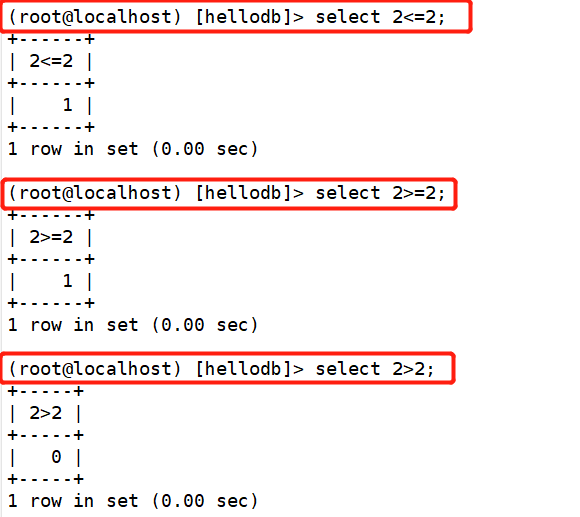
3. 大于、大于等于、小于、小于等于
- 大于(>)运算符用来判断左侧的操作数是否大于右侧的操作数,若大于返回1,否则返回0,同样不能用于判断NULL
- 小于(<)运算符用来判断左侧的操作数是否小于右侧的操作数,若小于返回1,否则返回0,同样不能用于判断NULL
- 大于等于(>=)判断左侧的操作数是否大于等于右侧的操作数,若大于等于返回1,否则返回0,不能用于判断NULL
- 小于等于(<=)判断左侧的操作数是否小于等于右侧的操作数,若小于等于返回1,否则返回0,不能用于判断NULL
4.判断一个值为/不为null(is null,is not null)
- IS NULL判断一个值是否为NULL,如果为NULL返回1,否则返回0
- IS NOT NULL判断一个值是否不为NULL,如果不为NULL返回1,否则返回0

3.逻辑运算符
- 逻辑运算符又被称为布尔运算符,通常用来判断表达式的真假,如果为真返回1,否则返回0,真和假也可以用TRUE和FALSE表示。
- MySQL中支持使用的逻辑运算符有四种
not 或 ! :逻辑非
and 或 && :逻辑与
or :逻辑或
xor :逻辑异或
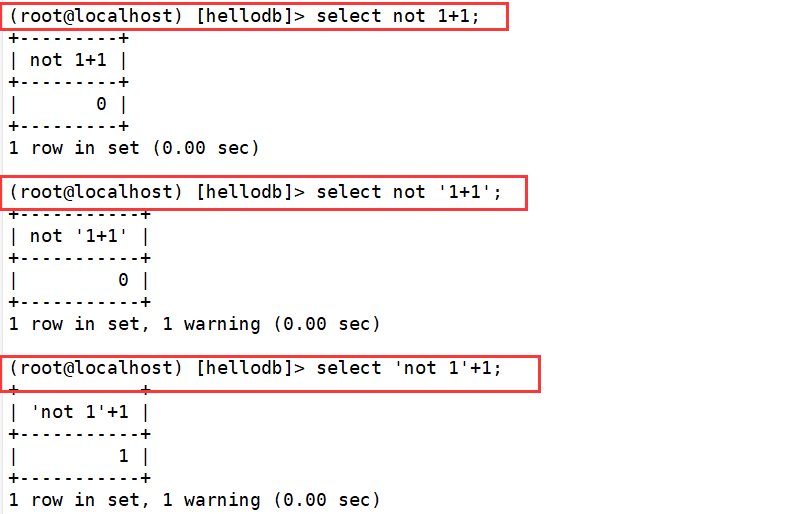
1.逻辑非
- 逻辑非将跟在他后面的值取反,如果NOT后面的操作数为0时,所得值为1
- 如果操作数为非0时,所得值为0
- 如果操作数为NULL时,所得值为NULL

2.逻辑与(and)
- 当所有操作数都为非零值并且不为NULL时,返回值为1
- 当一个或多个操作数为0时,返回值为0
- 操作数中有任何一个为NULT时,返回值为NULL
3.逻辑或(or)
- 当两个操作数都为非NULL值时,如果有任意一个操作数为非零值,则返回值为1,否则结果为0
- 当有一个操作数为NULL时,如果另一个操作数为非零值,则返回值为1,否则结果为NULL
- 假如两个操作数均为NULL时,则返回值为NULL。

4. 逻辑异或(xor)
- 当任意一个操作数为NULL时,返回值为NULL
- 对于非NULL的操作数,如果两个操作数都是非0值或者都是0值,则返回值为0
- 如果一个为0值,另一个为非0值,返回值为1
4.位运算符
- 位运算符是在二进制数上进行计算的运算符
- 位运算会先将操作数变成二进制数,进行位运算
- 然后再将计算结果从二进制数变回十进制数
| 位运算符 | 描述 |
|---|---|
| & | 按位与 |
| I | 按位或 |
| ^ | 按位异或 |
| ! | 取反 |
| << | 左移 |
| >> | 右移 |
- 按位与:对应的二进制位都为1,则运算结果为1,否则为0
- 按位或:对应的二进制位有一个为1则为1,否则为0
- 按位异或:对应的二进制位不同时,运算结果为1,否则为0
- 取反:对应的二进制数逐位反转,0取反为1,1取反为0
三.日期时间函数
| 字符串函数 | 描述 |
|---|---|
| curdate() | 返回当前时间的年月日 |
| curtime() | 返回当前时间的时分秒 |
| now() | 返回当前时间的日期和时间 |
| month(x) | 返回日期 x 中的月份值 |
| week(x) | 返回日期 x 是年度第几个星期 |
| hour(x) | 返回 x 中的小时值 |
| minute(x) | 返回 x 中的分钟值 |
| second(x) | 返回 x 中的秒钟值 |
| dayofweek(x) | 返回 x 是星期几,1 星期日,2 星期一 |
| dayofmonth(x) | 计算日期 x 是本月的第几天 |
| dayofyear(x) | 计算日期 x 是本年的第几天 |
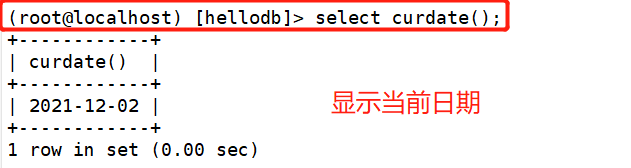
1.curdate()
2. curtime()

3. now()

4. month()
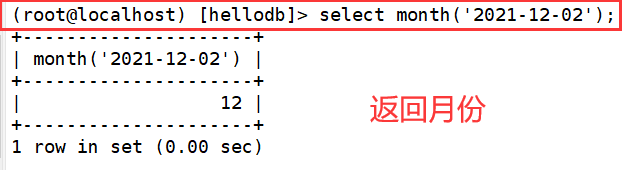
5.week( )

6.hour( )

7. minute( )
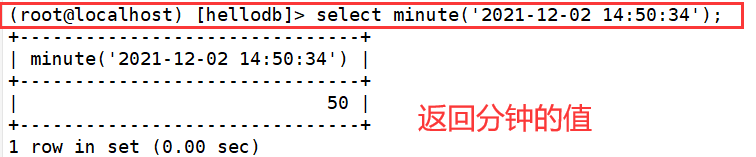
8.second( )

9. dayofweek( )

10.dayofmonth( )
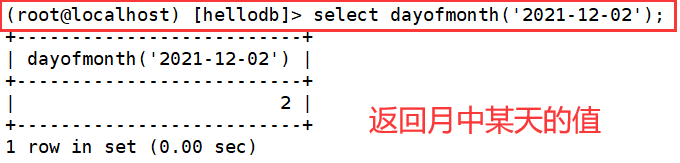
11.dayofyear( )

四.存储过程
存储过程是组为了完成特定功能的SQL语句集合。
存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用–个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统SQL速度更快、执行效率更高。
1.存储过程的优势
1.封装性
通常完成一个逻辑功能需要多条 SQL 语句,而且各个语句之间很可能传递参数,所以,编写逻辑功能相对来说稍微复杂些,而存储过程可以把这些 SQL 语句包含到一个独立的单元中,使外界看不到复杂的 SQL 语句,只需要简单调用即可达到目的。并且数据库专业人员可以随时对存储过程进行修改,而不会影响到调用它的应用程序源代码
2.可增强 SQL 语句的功能和灵活性
存储过程可以用流程控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
3.可减少网络流量
由于存储过程是在服务器端运行的,且执行速度快,因此当客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而可降低网络负载。
4.提高性能
当存储过程被成功编译后,就存储在数据库服务器里了,以后客户端可以直接调用,这样所有的 SQL 语句将从服务器执行,从而提高性能。但需要说明的是,存储过程不是越多越好,过多的使用存储过程反而影响系统性能
5.提高数据库的安全性和数据的完整性
存储过程提高安全性的一个方案就是把它作为中间组件,存储过程里可以对某些表做相关操作,然后存储过程作为接口提供给外部程序。这样,外部程序无法直接操作数据库表,只能通过存储过程来操作对应的表,因此在一定程度上,安全性是可以得到提高的。
6.使数据独立
数据的独立可以达到解耦的效果,也就是说,程序可以调用存储过程,来替代执行多条的 SQL 语句。这种情况下,存储过程把数据同用户隔离开来,优点就是当数据表的结构改变时,调用表不用修改程序,只需要数据库管理者重新编写存储过程即可。
2.创建调用和查看存储的过程
1.创建存储过程
DELIMITER @@ #将语句的结束符号从分号;临时改为两个@@ (可以是自定义)
CREATE PROCEDURE yibo() #创建存储过程,过程名为yibo, 不带参数
-> BEGIN #过程体以关键字BEGIN开始
-> SELECT * FROM oyyy; #过程体语句(自己根据需求进行编写)
-> END @@ #过程体以关键字END结束
DELIMITER ; #将语句的结束符号恢复为分号

2.调用存储过程
call yibo;

3.查看存储过程
(root@localhost) [oyyy]> show create procedure oyyy.yibo\G;
(root@localhost) [oyyy]> show create procedure yibo\G; 省略库名

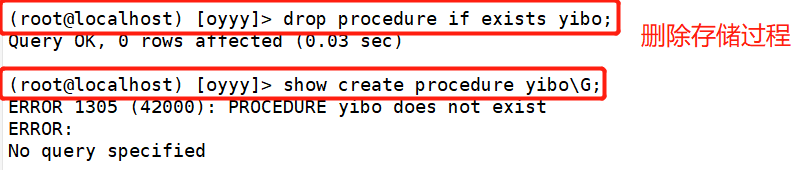
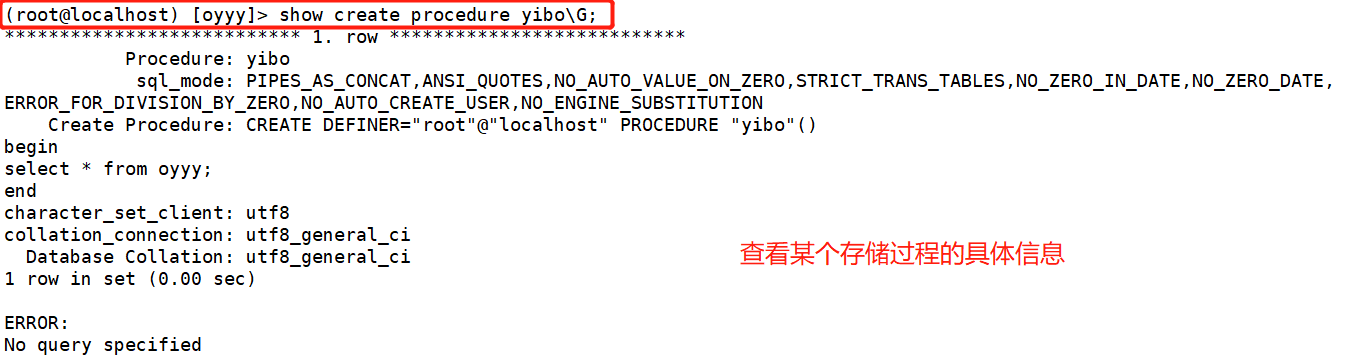 4.删除存储过程
4.删除存储过程
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。
(root@localhost) [oyyy]> drop procedure if exists yibo;
3.存储过程的参数
- IN输入参数: 表示调用者向过程传入值(传入值可以是字面量或变量)
- OUT输出参数: 表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
- INOUT输入输出参数: 既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
(root@localhost) [oyyy]> delimiter @@
(root@localhost) [oyyy]> create procedure yibo1(in yibo_name varchar(40))
-> begin
-> select * from oyyy where name=yibo_name;
-> end @@(root@localhost) [oyyy]> delimiter ;
(root@localhost) [oyyy]> call yibo1('aa');

 4.存储过程的控制语句
4.存储过程的控制语句
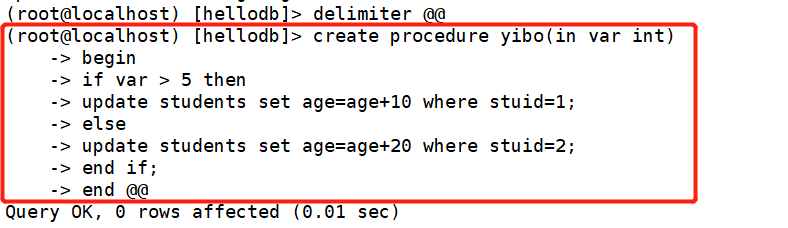
if then else ..... end if
原表

(root@localhost) [hellodb]> delimiter @@
(root@localhost) [hellodb]> create procedure yibo(in var int)
-> begin
-> if var > 5 then
-> update students set age=age+10 where stuid=1;
-> else
-> update students set age=age+20 where stuid=2;
-> end if;
-> end @@
(root@localhost) [hellodb]> call yibo(7);
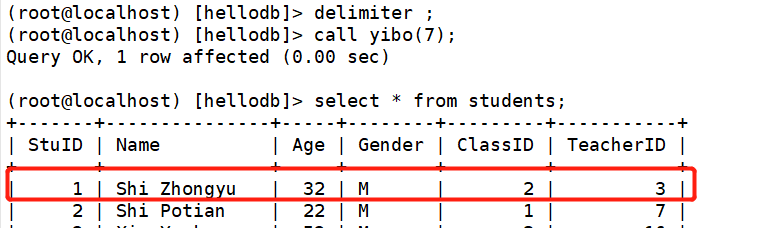
(root@localhost) [hellodb]> call yibo(3);

5.存储过程的循环语句
while do....end while


![]()
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









