






 本次技术公开课介绍了百度PaddlePaddle在NLP领域的应用,包括基于PaddlePaddle的轻量级中文分词引擎PaddleTokenizer,以及丰富的NLP官方模型库,如LAC、DAM和MM-DNN,展示了PaddlePaddle在中文NLP任务中的高效和全面性。
本次技术公开课介绍了百度PaddlePaddle在NLP领域的应用,包括基于PaddlePaddle的轻量级中文分词引擎PaddleTokenizer,以及丰富的NLP官方模型库,如LAC、DAM和MM-DNN,展示了PaddlePaddle在中文NLP任务中的高效和全面性。
NLP (Natural Language Processing)自然语言处理是人工智能的一个子领域,它是能够让人类与智能机器进行沟通交流的重要技术手段,同时也是人工智能中最为困难的问题之一。因此,NLP的研究处处充满魅力和挑战,也因此被称为人工智能“皇冠上的明珠”。
目前各家主流深度学习框架,都开放了相应的 NLP 算法模型。其中,百度 PaddlePaddle 基于自身技术优势,在中文NLP领域提供丰富官方模型,全方位满足各种NLP任务需求。
1 月 20 日下午 ,第二期百度深度学习开发者·技术公开课在百度大脑创新体验中心开课。百度资深研发工程师为现场的开发者们介绍了 PaddlePaddle 在 NLP 方向开源模型及技术实践,Google 机器学习开发者专家和高级算法专家孔晓泉则讲述了基于 PaddlePaddle 的中文分词引擎应用案例。
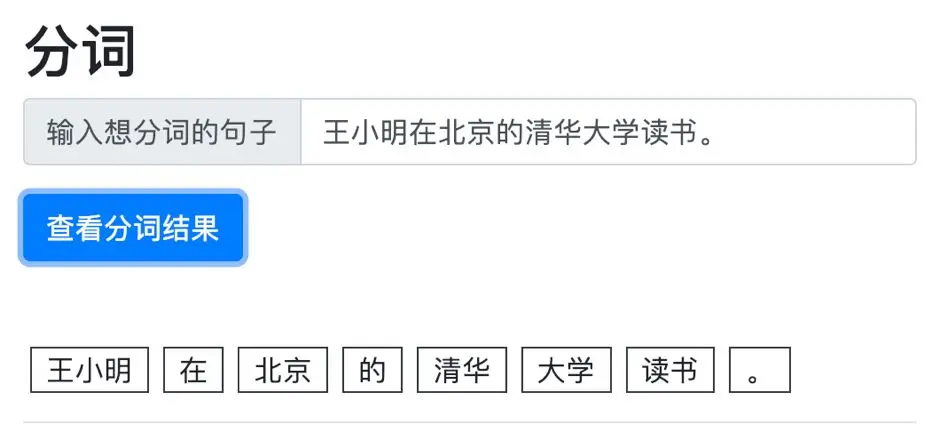
中文分词小试牛刀,100行代码的分词引擎实践
与大部分西方语言不同,书面汉语的词语之间没有明显的空格标记,句子是以字符串的形式出现,因此对中文进行处理的第一步就是进行自动分词,即将字符串转变成词语串,这也是处理中文的语义分析、文本分类、信息检索、机器翻译、机器问答等问题的基础。如果分词效果不好,很有可能会对后续的任务造成严重的影响。
谷歌机器学习开发者专家和高级算法专家孔晓泉,为大家分享了轻量级中文分词引擎——PaddlePaddle Tokenizer。该引擎基于PaddlePaddle Fluid API打造,充分发挥PaddlePaddle代码精简、高效、可读性高的特点,核心代码只有不到100行,带大家快速了解中文分词模型的设计思路。
模型方法:
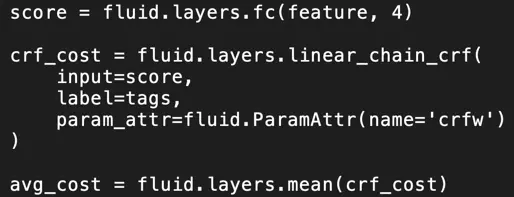
Embedding(字符嵌入) + BiLSTM(双向LSTM) + CRF(随机条件场)
系统设计:
通过将分词信息编码成 BMES (Begin, Middle, Eed, Single) 标签,从而将分词问题转换成 BMES 标签的序列预测问题。利用 Embeding + BiLSTM 提取字符的上下文特征,利用 CRF 同时考虑字符级别和上下文序列的特性,从而预测全局最优 BEMS 序列。为了抑制模型过拟合(Overfitting),在模型中使用了 Dropout 技术。
代码实现:
在代码实现层面,PaddleTokenizer 使用了 PaddlePaddle Fluid API,代码精简、高效、可读性高,核心代码少于100行。同时,PaddleTokenizer 通过提供 HTTP 接口的方式演示了如何使用 PaddlePaddle inferencemodel 对外提供服务。并提供了简洁的 WebUI 作为客户端,方便用户进行实际分词效果的测试。
系统分析与演示:
核心代码片段:
1. 定义输入变量

2. EmbeddingLayer
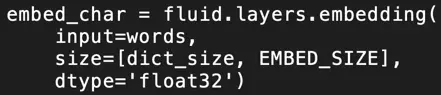
3. BiLSTMLayer
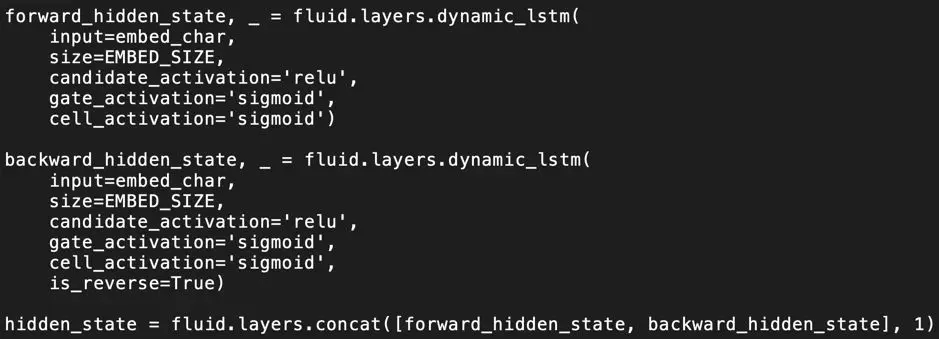
4. DropoutLayer

5. CRFLayer
分词效果展示:

GitHub地址:https://github.com/howl-anderson/PaddleTokenizer
丰富全面的NLP模型合集——PaddlePaddle官方模型库
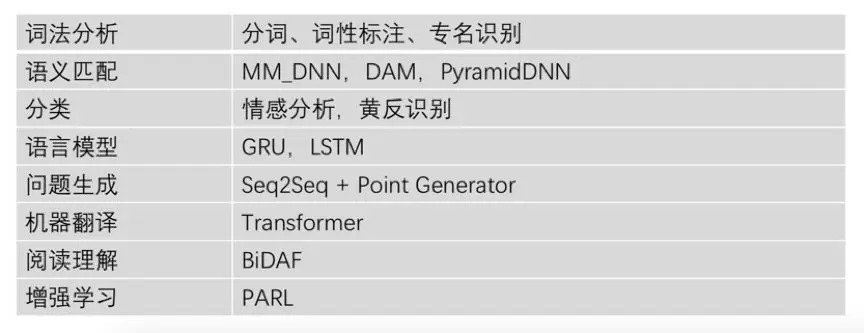
PaddlePaddle Tokenizer向大家展示了PaddlePaddle的高效易用,在PaddlePaddle官方模型库中,PaddlePaddle还提供了丰富的NLP模型,包含词法分析、语义匹配,还有情感分析、黄反识别用到的分类模型等,为开发者打造了功能全面的中文NLP工具库。
在公开课有限的时间里,百度工程师主要讲解了以下三大模型:
中文词法分析(LAC)

相比轻量级的PaddlePaddle Tokenizer,LAC的功能更加丰富,是一个联合的词法分析模型,整体性地完成中文分词、词性标注、专名识别任务。LAC基于一个堆叠的双向GRU结构,最上层建CRF 来预测整体模型,这比传统基于统计的模型在分词的准确性上有明显提升,也是PaddlePaddle 在中文 NLP 领域长期深耕的体现。
DAM
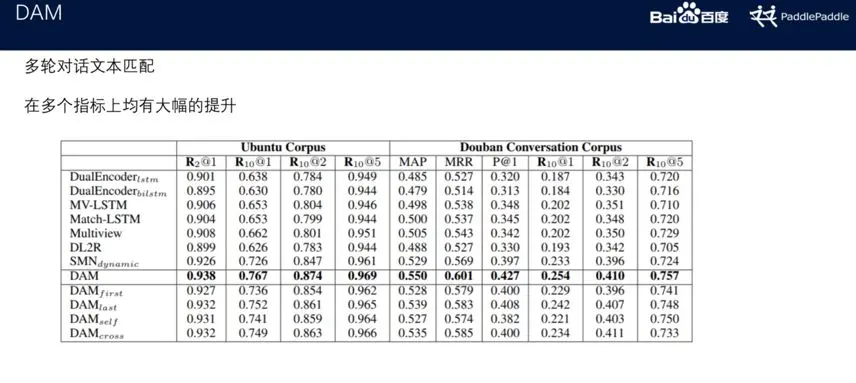
在自然语言处理很多场景中,需要度量两个文本在语义上的相似度,这类任务通常被称为语义匹配。例如在搜索中根据查询与候选文档的相似度对搜索结果进行排序,文本去重中文本与文本相似度的计算,自动问答中候选答案与问题的匹配等。
DAM (Deep Attention Matching Network)为百度自然语言处理部发表于ACL-2018的工作,用于检索式聊天机器人多轮对话中应答的选择。DAM受Transformer的启发,其网络结构完全基于注意力(attention)机制,利用栈式的self-attention结构分别学习不同粒度下应答和语境的语义表示,然后利用cross-attention获取应答与语境之间的相关性,在两个大规模多轮对话数据集上的表现均好于其它模型。
MM-DNN
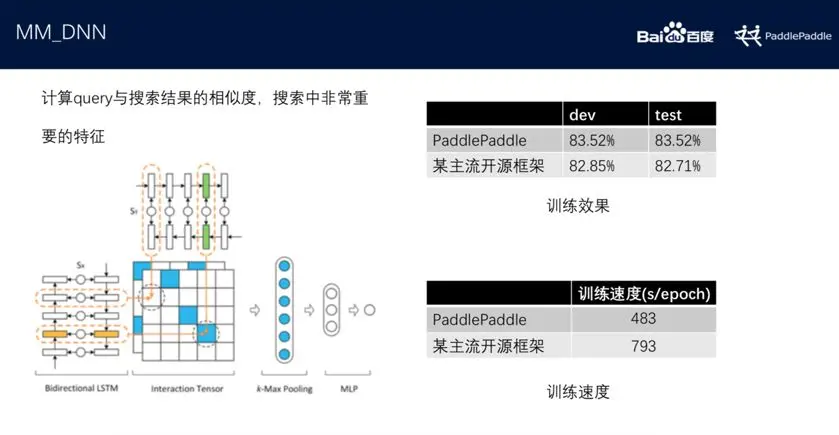
MM-DNN 模型的主要任务是计算 query 、检索结果和推荐内容。计算query 与搜索结果的相似度在整个排序任务中是非常重要的权重。该模型的开源版本无论是在训练效果还是训练速度上都有明显优势。百度搜索业务中也涉及了这一算法模型。















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









