






Dataset
对于PyTorch而言data load的核心类是torch.utils.data.Dataloader,而对于创建一个新的Dataloder对象,最重要的参数就是dataset,一个torch.utils.data.Dataset对象。
PyTorch提供了两种风格的datasets,分别是map-style和iterable-style:
-
map-style datasets通过用户自行实现
__getitem__()方法,可以做到随机读取。 -
iterable-style datasets通过实现
__iter__()方法,可以以迭代的形式对数据进行读取。
这里需要考虑实验所使用的数据集形式。OpenFWI数据集的FlatVel-A类共有60个npy文件,每个npy文件包含500条数据。
这里,如果使用map-style datasets会存在无法避免的问题:由于Dataset支持随机读取,则实现__getitem__()时需要反复进行np.load()操作。这会导致读盘时间过长,拖慢训练速度。
因此,考虑使用IterableDataset类来规避这个问题:
class Dataset(torch.utils.data.IterableDataset):
"""
Dataset for InversionNet.
"""
def __init__(self, root_dir, fid_list, num_samples_per_file=500):
"""
Initialize dataset.
Args:
root_dir: root directory.
fid_list: list of npy file id.
num_samples_per_file: number of npy samples, which is 500 for OpenFWI.
"""
super().__init__()
self.data_files = [
os.path.join(root_dir, "data", f"data{fid}.npy") for fid in fid_list
]
self.label_files = [
os.path.join(root_dir, "model", f"model{fid}.npy") for fid in fid_list
]
self.num_samples_per_file = num_samples_per_file
def __len__(self):
return len(self.data_files) * self.num_samples_per_file
def __iter__(self):
worker_info = torch.utils.data.get_worker_info()
if worker_info is not None:
num_workers = worker_info.num_workers
idx = worker_info.id
split_length = math.ceil(len(self.data_files) / num_workers)
data_range = range(
idx * split_length, min((idx + 1) * split_length, len(self.data_files))
)
else:
data_range = range(len(self.data_files))
for i in data_range:
data_file = np.load(self.data_files[i])
label_file = np.load(self.label_files[i])
for j in range(self.num_samples_per_file):
data, label = data_file[j], label_file[j]
yield data, label需要注意的是,当设置num_workers为非零常数(使用multi-process data loading)后,系统会直接将整个dataset复制到每个进程中。因此在实现__iter__()时,需要手动做分片操作。
Model
之前跟Dive into deep learning时已经了解了大概,此处不展开。
class InversionNet(nn.Module):
"""
My InversionNet consisting of convolution block and deconvolution block.
"""
def __init__(self, dim1=32, dim2=64, dim3=128, dim4=256, dim5=512, **kwargs):
"""
Args:
dim1: Number of channels in the 1st layer
dim2: Number of channels in the 2nd layer
dim3: Number of channels in the 3rd layer
dim4: Number of channels in the 4th layer
dim5: Number of channels in the 5th layer
"""
super().__init__()
// Init code
def forward(self, x):
// Forward codeTrain
训练脚本主要由几个部分构成。
Parser
用于处理传入的命令参数,调用argparse库即可。
def parse():
"""
Create a new parser.
"""
parser = argparse.ArgumentParser(
prog="Trainer", description="InversionNet Pytorch Trainer"
)
parser.add_argument(
"--batch-size",
type=int,
default=64,
metavar="N",
help="input batch size for training (default: 64)",
)
parser.add_argument(
"--train-size",
type=float,
default=0.8,
metavar="LR",
help="proportion for training dataset (default: 0.8)",
)
parser.add_argument(
"--epochs",
type=int,
default=1000,
metavar="N",
help="number of epochs to train (default: 1000)",
)
parser.add_argument(
"--lr",
type=float,
default=1e-2,
metavar="LR",
help="learning rate (default: 1e-2)",
)
parser.add_argument(
"--log-interval",
type=int,
default=1,
metavar="N",
help="how many batches to wait before logging training status",
)
parser.add_argument(
"--no-save-model",
action="store_true",
default=False,
help="do not save the current Model",
)
parser.add_argument(
"--seed", type=int, default=42, metavar="S", help="random seed (default: 42)"
)
parser.add_argument(
"--num-workers",
type=int,
default=0,
metavar="N",
help="number of processes if using multi-process data loading",
)
parser.add_argument(
"--no-cuda", action="store_true", default=False, help="disables CUDA training"
)
parser.add_argument(
"--no-mps",
action="store_true",
default=False,
help="disables macOS GPU training",
)
return parser环境设置
设置训练所需的各种环境。
torch.manual_seed(args.seed)
use_cuda = not args.no_cuda and torch.cuda.is_available()
use_mps = not args.no_mps and torch.backends.mps.is_available()
if use_mps:
assert (
use_mps and args.num_workers == 0
), "No support for multiprocess dataload using mps"
kwargs = {
"batch_size": args.batch_size,
"num_workers": args.num_workers,
"pin_memory": True,
}
if use_cuda:
device = torch.device("cuda")
elif use_mps:
device = torch.device("mps")
else:
device = torch.device("cpu")Dataloader
在主程序中创建对应的train_loader和test_loader,为了随机,对文件列表做了打乱处理。
r = random.Random(args.seed)
num_file = len(
[file for file in os.listdir("./data/data") if file.endswith(".npy")]
)
file_idx_list = [i for i in range(1, num_file + 1)]
r.shuffle(file_idx_list)
# Load dataset
train_loader = torch.utils.data.DataLoader(
dataset=Dataset("./data", file_idx_list[: num_file * args.train_size]),
**kwargs,
)
test_loader = torch.utils.data.DataLoader(
dataset=Dataset("./data", file_idx_list[num_file * args.train_size :]),
**kwargs,
)训练
工作站上搭载了两块显卡,因此创建DataParallel对象,调用两个GPU进行运算。
创建新网络、优化器等对象,开始训练:
if use_cuda:
model = DataParallel(InversionNet())
else:
model = InversionNet()
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), args.lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.6)
loss, test_loss = [], []
epochs = range(1, args.epochs + 1)
for epoch in epochs:
loss.append(train(args, model, device, train_loader, optimizer, epoch))
test_loss.append(test(model, device, test_loader))
scheduler.step()test()比较简单,主要逻辑只包含一个loss计算,重点分析train()函数。函数中包含下述语句:
for batch_idx, (data, target) in enumerate(train_loader):
// Code
return当不设置num_workers时,len(enumerate(train_loader))是准确的,即math.ceil(len(train_loader.dataset) // batch_size)。然而,启用multi-process dataloading后,这个数值不再准确。这是因为len(enumerate(train_loader))仍然由上述的逻辑计算得到,而实际上batch的分配不再如此,具体逻辑如下:
-
根据
num_workers数,和在IterableDataset处自定义的分片逻辑,得到每个进程需要处理的数据数量data_num。 -
对每个进程,分别按照batch_size进行数据获取。这样,每个进程的batch数就变成了
math.ceil(data_num / batch_size)
根据上述原理,我们可以准确的计算出实际的batch数量:
def cal_batch_num(args, dataloader):
if args.num_workers == 0:
batch_num = len(dataloader)
else:
batch_num = 0
for idx in range(args.num_workers):
split_length = math.ceil(len(dataloader.dataset) / args.num_workers)
data_num = min((idx + 1) * split_length, len(dataloader.dataset)) - idx * split_length
batch_num += math.ceil(data_num / args.batch_size)
return batch_num举例:总共有500项数据,设置num_worker=3时,每个进程处理的数据索引如下:
worker 0, start 0, end 167 worker 1, start 167, end 334 worker 2, start 334, end 500
设batch_size=100,那么总的batch数量为6而非5。
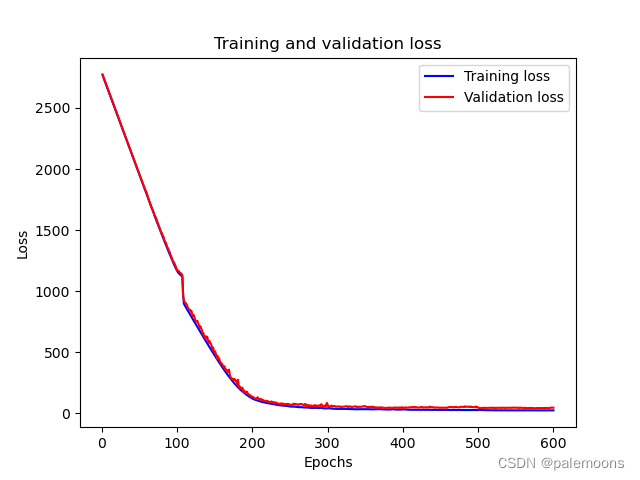
测试结果
Loss图
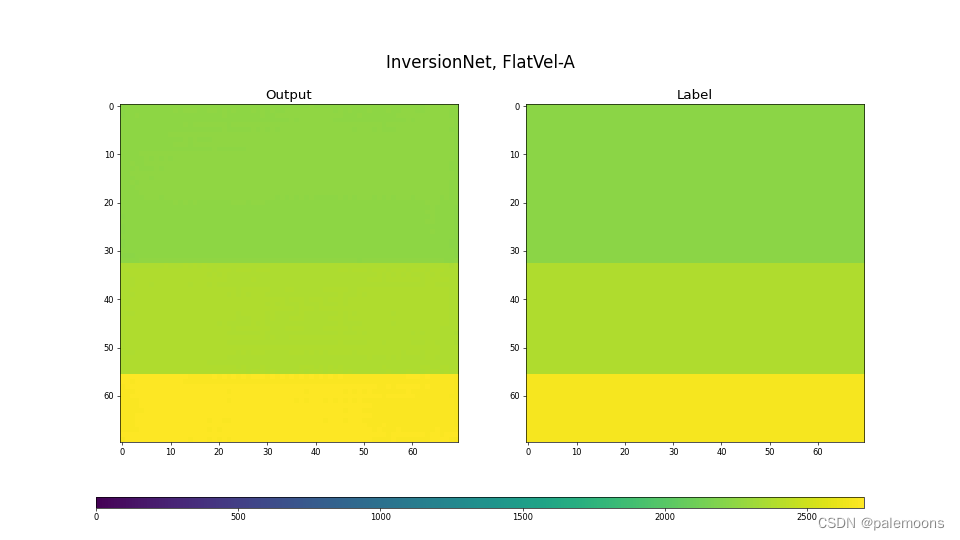
选取样本
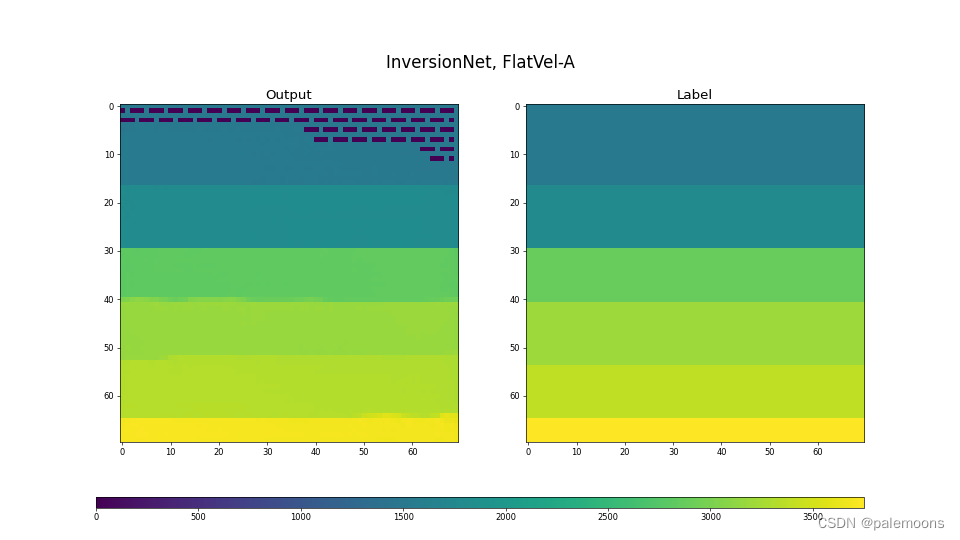















 7834
7834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









