import torch
import torch. nn as nn
import torch. optim as optim
import numpy as np
import os
from time import time
import shutil
import argparse
import configparser
from model. ASTGCN_r import make_model
from lib. utils import load_graphdata_channel1, get_adjacency_matrix, compute_val_loss_mstgcn, predict_and_save_results_mstgcn
from tensorboardX import SummaryWriter
在这里主要讲解训练的主函数以及在主函数中引用的函数 。
device = torch. device( "cuda" if torch. cuda. is_available( ) else "cpu" )
parser = argparse. ArgumentParser( )
parser. add_argument( "--config" , default= 'configurations/PEMS04_astgcn.conf' , type = str ,
help = "configuration file path" )
args = parser. parse_args( )
config = configparser. ConfigParser( )
print ( 'Read configuration file: %s' % ( args. config) )
config. read( args. config)
data_config = config[ 'Data' ]
training_config = config[ 'Training' ]
adj_filename = data_config[ 'adj_filename' ]
graph_signal_matrix_filename = data_config[ 'graph_signal_matrix_filename' ]
if config. has_option( 'Data' , 'id_filename' ) :
id_filename = data_config[ 'id_filename' ]
else :
id_filename = None
num_of_vertices = int ( data_config[ 'num_of_vertices' ] )
points_per_hour = int ( data_config[ 'points_per_hour' ] )
num_for_predict = int ( data_config[ 'num_for_predict' ] )
len_input = int ( data_config[ 'len_input' ] )
dataset_name = data_config[ 'dataset_name' ]
model_name = training_config[ 'model_name' ]
''' ctx = mx.gpu(int(ctx[ctx.index('-') + 0:])) '''
ctx = training_config[ 'ctx' ]
os. environ[ "CUDA_VISIBLE_DEVICES" ] = ctx
USE_CUDA = torch. cuda. is_available( )
DEVICE = torch. device( "cuda" if torch. cuda. is_available( ) else "cpu" )
print ( "CUDA:" , USE_CUDA, DEVICE)
learning_rate = float ( training_config[ 'learning_rate' ] )
epochs = int ( training_config[ 'epochs' ] )
start_epoch = int ( training_config[ 'start_epoch' ] )
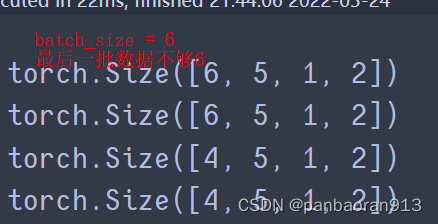
batch_size = int ( training_config[ 'batch_size' ] )
num_of_weeks = int ( training_config[ 'num_of_weeks' ] )
num_of_days = int ( training_config[ 'num_of_days' ] )
num_of_hours = int ( training_config[ 'num_of_hours' ] )
time_strides = num_of_hours
nb_chev_filter = int ( training_config[ 'nb_chev_filter' ] )
nb_time_filter = int ( training_config[ 'nb_time_filter' ] )
in_channels = int ( training_config[ 'in_channels' ] )
nb_block = int ( training_config[ 'nb_block' ] )
K = int ( training_config[ 'K' ] )
loss_function = training_config[ 'loss_function' ]
metric_method = training_config[ 'metric_method' ]
missing_value = float ( training_config[ 'missing_value' ] )
folder_dir = '%s_h%dd%dw%d_channel%d_%e' % ( model_name, num_of_hours, num_of_days, num_of_weeks, in_channels, learning_rate)
print ( 'folder_dir:' , folder_dir)
params_path = os. path. join( 'experiments' , dataset_name, folder_dir)
print ( 'params_path:' , params_path)
train_loader, train_target_tensor, val_loader, val_target_tensor, test_loader, test_target_tensor, _mean, _std \
= load_graphdata_channel1( graph_signal_matrix_filename, num_of_hours, num_of_days, num_of_weeks, device, batch_size)
adj_mx, distance_mx = get_adjacency_matrix( adj_filename, num_of_vertices, id_filename)
if __name__ == "__main__" :
train_main( )
load_graphdata_channel1变量名称 类型 举例 graph_signal_matrix_filename str ./data/PEMS04/PEMS04.npz num_of_weeks int 0 num_of_days int 0 num_of_hours int 1 DEVICE CPU batch_size int 32
1. 文件路径的拼接结果: ./data/PEMS04\PEMS04_r1_d0_w0_astcgn.npz
2. 数据读取为file_data
3. 获得'特征数据'及'标签数据',特征中为F=3,现选择第一个特征[0:1]。
4. shape如下(seq,N,F,T)
* train: [10181, 307, 1, 12] train_target: [10181, 307, 12]
* val: [3394, 307, 1, 12] val_target: [3394, 307, 12]
* test: [3394, 307, 1, 12] test_target: [3394, 307, 12]
5. 获得关于F这一轴的均值和标准差
* PEMS04Mean: (1, 1, 1, 1)
* PEMS04Std: (1, 1, 1, 1)
6. train_loader的数据生成:
生成Tensor:train_x_tensor和train_target_tensor
函数TensorDataset生成相同格式的迭代器:train_dataset,
该迭代器介绍:
for tx,ty in train_dataset:共循环B=10181次
tx.shape=(N,F,T)=(307,1,12)
ty.shape=(N,F,T) =(307,1,12)
7. test_loader的数据生成:
生成Tensor:test_x_tensor和test_target_tensor
函数TensorDataset生成相同格式的迭代器:test_dataset,
该迭代器介绍:
for tx,ty in train_dataset:共循环B=3394次
tx.shape=(N,F,T)=(307,1,12)
ty.shape=(N,F,T) =(307,1,12)
8. val_loader的数据生成
生成Tensor:val_x_tensor和val_target_tensor
函数TensorDataset生成相同格式的迭代器:val_dataset,
该迭代器介绍:
for tx,ty in train_dataset:共循环B=3394次
tx.shape=(N,F,T)=(307,1,12)
ty.shape=(N,F,T) =(307,1,12)
变量名称 类型 shape 用途 train_loader 迭代器 len=319 每个迭代含dx,dy;dx和dy的shape都为(32,307,1,12) train_target_tensor Tensor [10181, 307, 12] 训练部分的标签 val_loader 迭代器 len=107 每个迭代含dx,dy;dx和dy的shape都为(32,307,1,12) val_target_tensor Tensor [3394, 307, 12] 验证部分的标签 test_loader 迭代器 len=107 每个迭代含dx,dy;dx和dy的shape都为(32,307,1,12) test_target_tensor Tensor [3394, 307, 12] 测试部分的标签 mean Tensor [1,1,1,] 整个数据集关于F[0:1]的均值 std Tensor [1,1,1,1] 整个数据集关于F[0:1]的标准差
def load_graphdata_channel1 ( graph_signal_matrix_filename, num_of_hours, num_of_days, num_of_weeks, DEVICE, batch_size, shuffle= True ) :
'''
这个是为PEMS的数据准备的函数
将x,y都处理成归一化到[-1,1]之前的数据;
每个样本同时包含所有监测点的数据,所以本函数构造的数据输入时空序列预测模型;
该函数会把hour, day, week的时间串起来;
注: 从文件读入的数据,x是最大最小归一化的,但是y是真实值
这个函数转为mstgcn,astgcn设计,返回的数据x都是通过减均值除方差进行归一化的,y都是真实值
:return:
three DataLoaders, each dataloader contains:
test_x_tensor: (B, N_nodes, in_feature, T_input)
test_decoder_input_tensor: (B, N_nodes, T_output)
test_target_tensor: (B, N_nodes, T_output)
'''
file = os. path. basename( graph_signal_matrix_filename) . split( '.' ) [ 0 ]
dirpath = os. path. dirname( graph_signal_matrix_filename)
filename = os. path. join( dirpath,
file + '_r' + str ( num_of_hours) + '_d' + str ( num_of_days) + '_w' + str ( num_of_weeks) ) + '_astcgn'
print ( 'load file:' , filename)
file_data = np. load( filename + '.npz' )
train_x = file_data[ 'train_x' ]
train_x = train_x[ : , : , 0 : 1 , : ]
train_target = file_data[ 'train_target' ]
val_x = file_data[ 'val_x' ]
val_x = val_x[ : , : , 0 : 1 , : ]
val_target = file_data[ 'val_target' ]
test_x = file_data[ 'test_x' ]
test_x = test_x[ : , : , 0 : 1 , : ]
test_target = file_data[ 'test_target' ]
mean = file_data[ 'mean' ] [ : , : , 0 : 1 , : ]
std = file_data[ 'std' ] [ : , : , 0 : 1 , : ]
train_x_tensor = torch. from_numpy( train_x) . type ( torch. FloatTensor) . to( DEVICE)
train_target_tensor = torch. from_numpy( train_target) . type ( torch. FloatTensor) . to( DEVICE)
train_dataset = torch. utils. data. TensorDataset( train_x_tensor, train_target_tensor)
train_loader = torch. utils. data. DataLoader( train_dataset, batch_size= batch_size, shuffle= shuffle)
val_x_tensor = torch. from_numpy( val_x) . type ( torch. FloatTensor) . to( DEVICE)
val_target_tensor = torch. from_numpy( val_target) . type ( torch. FloatTensor) . to( DEVICE)
val_dataset = torch. utils. data. TensorDataset( val_x_tensor, val_target_tensor)
val_loader = torch. utils. data. DataLoader( val_dataset, batch_size= batch_size, shuffle= False )
test_x_tensor = torch. from_numpy( test_x) . type ( torch. FloatTensor) . to( DEVICE)
test_target_tensor = torch. from_numpy( test_target) . type ( torch. FloatTensor) . to( DEVICE)
test_dataset = torch. utils. data. TensorDataset( test_x_tensor, test_target_tensor)
test_loader = torch. utils. data. DataLoader( test_dataset, batch_size= batch_size, shuffle= False )
print ( 'train:' , train_x_tensor. size( ) , train_target_tensor. size( ) )
print ( 'val:' , val_x_tensor. size( ) , val_target_tensor. size( ) )
print ( 'test:' , test_x_tensor. size( ) , test_target_tensor. size( ) )
return train_loader, train_target_tensor, val_loader, val_target_tensor, test_loader, test_target_tensor, mean, std
注释:
PyTorch之torch.utils.data.DataLoader详解
≠
32
\neq 32
= 32 drop_last=True丢掉呢??get_adjacency_matrix变量 类型 举例 distance_df_filename str ./data/PEMS04/distance.csv num_of_vertices int 307 id_filename None
1. 如果是.npy格式邻接矩阵直接np.load读取并返回A,None
2. 否则读取.csv格式的数据
3. 根据顶点个数创建全0的array数组A, distanceA
4. 如果id_filename有内容的话,。。。。,然会A,distanceA
5. 否则的话,用csv打开distance_df_filename,数据填充进A和distanceA并返回
* A 是无权的邻接矩阵(0-1)
* distanceA是加权的邻接矩阵
def get_adjacency_matrix ( distance_df_filename, num_of_vertices, id_filename= None ) :
'''
Returns
----------
A: np.ndarray, adjacency matrix
'''
if 'npy' in distance_df_filename:
adj_mx = np. load( distance_df_filename)
return adj_mx, None
else :
import csv
A = np. zeros( ( int ( num_of_vertices) , int ( num_of_vertices) ) , dtype= np. float32)
distaneA = np. zeros( ( int ( num_of_vertices) , int ( num_of_vertices) ) , dtype= np. float32)
if id_filename:
with open ( id_filename, 'r' ) as f:
id_dict = { int ( i) : idx for idx, i in enumerate ( f. read( ) . strip( ) . split( '\n' ) ) }
with open ( distance_df_filename, 'r' ) as f:
f. readline( )
reader = csv. reader( f)
for row in reader:
if len ( row) != 3 :
continue
i, j, distance = int ( row[ 0 ] ) , int ( row[ 1 ] ) , float ( row[ 2 ] )
A[ id_dict[ i] , id_dict[ j] ] = 1
distaneA[ id_dict[ i] , id_dict[ j] ] = distance
return A, distaneA
else :
with open ( distance_df_filename, 'r' ) as f:
f. readline( )
reader = csv. reader( f)
for row in reader:
if len ( row) != 3 :
continue
i, j, distance = int ( row[ 0 ] ) , int ( row[ 1 ] ) , float ( row[ 2 ] )
A[ i, j] = 1
distaneA[ i, j] = distance
return A, distaneA
train_main变量 类型 举例 用途 start_epoch int 0 模型训练开始的轮次 params_path str experiments\PEMS04\astgcn_r_h1d0w0_channel1_1.000000e-03 参数保存的路径 masked_flag int 0或1 用来选择控制损失函数 global_step int init 0 全局变量,记录当前训练轮次 best_epoch int init 0 记录验证模型最好的轮次 best_val_loss float init 无穷大 记录验证最好的结果
#######准备工作#######
1. 通过start_epoch和params_path组合来保证参数保存的路径的正确性和可靠性
2. 打印相关参数
3. masked_flag和loss_function控制2个损失函数criterion和criterion_masked
4. 使用Adam方法初始化优化器optimizer
5. 初始化SummaryWriter以将信息写入日志目录
6. 打印net模型、net's state_dict、Optimizer's state_dict
7. 如果不是从0开始训练,则获得参数文件,net加载参数
8. 设置初始全局变量:global_step = 0 best_epoch = 0,best_val_loss为无穷大
#####模型训练#######
for epoch in range(start_epoch, epochs)
a. 参数文件路径的获取部分
b. 模型验证部分
c. 模型训练部分
net.train()
for ...train_loader:
获取数据inputs,label
梯度设置为0
outputs=net(inputs)
根据masked_flag获得损失值loss
loss.backward()向后函数
optimizer.step()优化
training_loss = loss.item()损失值剥离
global_step += 1训练次数+1
sw.add_scalar 写入日志
#####获取最优net####
打印best_val_loss和best_epoch
并根据获得最优的net
使用 predict_main函数预测最优结果
def train_main ( ) :
if ( start_epoch == 0 ) and ( not os. path. exists( params_path) ) :
os. makedirs( params_path)
print ( 'create params directory %s' % ( params_path) )
elif ( start_epoch == 0 ) and ( os. path. exists( params_path) ) :
shutil. rmtree( params_path)
os. makedirs( params_path)
print ( 'delete the old one and create params directory %s' % ( params_path) )
elif ( start_epoch > 0 ) and ( os. path. exists( params_path) ) :
print ( 'train from params directory %s' % ( params_path) )
else :
raise SystemExit( 'Wrong type of model!' )
print ( 'param list:' )
print ( 'CUDA\t' , device)
print ( 'in_channels\t' , in_channels)
print ( 'nb_block\t' , nb_block)
print ( 'nb_chev_filter\t' , nb_chev_filter)
print ( 'nb_time_filter\t' , nb_time_filter)
print ( 'time_strides\t' , time_strides)
print ( 'batch_size\t' , batch_size)
print ( 'graph_signal_matrix_filename\t' , graph_signal_matrix_filename)
print ( 'start_epoch\t' , start_epoch)
print ( 'epochs\t' , epochs)
masked_flag= 0
criterion = nn. L1Loss( ) . to( device)
criterion_masked = masked_mae
if loss_function== 'masked_mse' :
criterion_masked = masked_mse
masked_flag= 1
elif loss_function== 'masked_mae' :
criterion_masked = masked_mae
masked_flag = 1
elif loss_function == 'mae' :
criterion = nn. L1Loss( ) . to( device)
masked_flag = 0
elif loss_function == 'rmse' :
criterion = nn. MSELoss( ) . to( device)
masked_flag= 0
optimizer = optim. Adam( net. parameters( ) , lr= learning_rate)
sw = SummaryWriter( logdir= params_path, flush_secs= 5 )
print ( net)
print ( 'Net\'s state_dict:' )
total_param = 0
for param_tensor in net. state_dict( ) :
print ( param_tensor, '\t' , net. state_dict( ) [ param_tensor] . size( ) )
total_param += np. prod( net. state_dict( ) [ param_tensor] . size( ) )
print ( 'Net\'s total params:' , total_param)
print ( 'Optimizer\'s state_dict:' )
for var_name in optimizer. state_dict( ) :
print ( var_name, '\t' , optimizer. state_dict( ) [ var_name] )
global_step = 0
best_epoch = 0
best_val_loss = np. inf
start_time = time( )
if start_epoch > 0 :
params_filename = os. path. join( params_path, 'epoch_%s.params' % start_epoch)
net. load_state_dict( torch. load( params_filename) )
print ( 'start epoch:' , start_epoch)
print ( 'load weight from: ' , params_filename)
for epoch in range ( start_epoch, epochs) :
params_filename = os. path. join( params_path, 'epoch_%s.params' % epoch)
if masked_flag:
val_loss = compute_val_loss_mstgcn( net, val_loader, criterion_masked, masked_flag, missing_value, sw, epoch)
else :
val_loss = compute_val_loss_mstgcn( net, val_loader, criterion, masked_flag, missing_value, sw, epoch)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_epoch = epoch
torch. save( net. state_dict( ) , params_filename)
print ( 'save parameters to file: %s' % params_filename)
net. train( )
for batch_index, batch_data in enumerate ( train_loader) :
encoder_inputs, labels = batch_data
optimizer. zero_grad( )
outputs = net( encoder_inputs)
if masked_flag:
loss = criterion_masked( outputs, labels, missing_value)
else :
loss = criterion( outputs, labels)
loss. backward( )
optimizer. step( )
training_loss = loss. item( )
global_step += 1
sw. add_scalar( 'training_loss' , training_loss, global_step)
if global_step % 1000 == 0 :
print ( 'global step: %s, training loss: %.2f, time: %.2fs' % ( global_step, training_loss, time( ) - start_time) )
print ( 'best epoch:' , best_epoch)
predict_main( best_epoch, test_loader, test_target_tensor, metric_method , _mean, _std, 'test' )
predict_main变量 类型 举例 用途 global_step int >=0 训练轮次 data_loader 迭代器 test_loader 用于预测的测试数据 data_target_tensor Tensor test_target_tensor 测试的标签数据 metric_method str unmask _mean (1,1,1,1) load_graphdata_channel1中而来 均值 _std (1,1,1,1) load_graphdata_channel1中而来 标准差 type str test 表明哪个数据样本
1. 参数路径的拼接获取
2. net加载参数路径
3. predict_and_save_results_mstgcn函数获得预测结果
def predict_main ( global_step, data_loader, data_target_tensor, metric_method, _mean, _std, type ) :
params_filename = os. path. join( params_path, 'epoch_%s.params' % global_step)
print ( 'load weight from:' , params_filename)
net. load_state_dict( torch. load( params_filename) )
predict_and_save_results_mstgcn( net, data_loader, data_target_tensor, global_step, metric_method, _mean, _std, params_path, type )
masked_maedef masked_mae ( preds, labels, null_val= np. nan) :
if np. isnan( null_val) :
mask = ~ torch. isnan( labels)
else :
mask = ( labels != null_val)
mask = mask. float ( )
mask /= torch. mean( ( mask) )
mask = torch. where( torch. isnan( mask) , torch. zeros_like( mask) , mask)
loss = torch. abs ( preds - labels)
loss = loss * mask
loss = torch. where( torch. isnan( loss) , torch. zeros_like( loss) , loss)
return torch. mean( loss)
compute_val_loss_mstgcn变量 类型 举例 用途 net nn.Module 模型 val_loader 迭代器 验证集数据 criterion fun nn.MSELoss 损失函数 masked_flag int 0或1 用于配合损失函数 sw tensorboardX.SummaryWriter 训练日志 epoch int >=0 第几轮训练
1. net.train(False)去点dropout机制
2. 模型静态0梯度:
tmp=[ ] 存储loss结果
for enumerate(val_loader):
outputs=net(输入)
用masked_flag选择损失函数返回损失loss
validation_loss是多轮次的平均损失值
将epoch和validation_loss写入日志sw
return validation_loss
《Dropout理解-原理,实现,优缺点》
def compute_val_loss_mstgcn ( net, val_loader, criterion, masked_flag, missing_value, sw, epoch, limit= None ) :
net. train( False )
with torch. no_grad( ) :
val_loader_length = len ( val_loader)
tmp = [ ]
for batch_index, batch_data in enumerate ( val_loader) :
encoder_inputs, labels = batch_data
outputs = net( encoder_inputs)
if masked_flag:
loss = criterion( outputs, labels, missing_value)
else :
loss = criterion( outputs, labels)
tmp. append( loss. item( ) )
if batch_index % 100 == 0 :
print ( 'validation batch %s / %s, loss: %.2f' % ( batch_index + 1 , val_loader_length, loss. item( ) ) )
if ( limit is not None ) and batch_index >= limit:
break
validation_loss = sum ( tmp) / len ( tmp)
sw. add_scalar( 'validation_loss' , validation_loss, epoch)
return validation_loss
predict_and_save_results_mstgcn注意到:该函数多次用到type,input等原本具有函数意义的变量。不建议如此使用。
变量 类型 举例 用途 net nn.Module data_loader 迭代器 test_loader 测试数据用于预测 data_target_tensor Tensor test_target_tensor 测试数据的label global_step int >=0 用于选择第几轮次模型参数 metric_method str unmask _mean Tensor (1,1,1,1) 均值 _std Tensor (1,1,1,1) 标准差 params_path str 文件路径 type str “test” 说明数据类型的
A. net.train(False) # 去掉dropout机制
B. with torch.no_grad() 以下均在此环境中进行
1. prediction=[]用于存储net结果;input=[]用于存储输入数据
2. 注意到所有与net相关的数据转换:detach().cpu().numpy()
3. for ... enumerate(data_loader):
outputs=net(encoder_inputs)
输入和输出数据分别放入input和prediction
4. 对input数据按照axis=0进行合并,再利用_mean和_std进行反归一化
5. 对prediction数据按照axis=0进行合并
6. 打印input,prediction,data_target_tensor的shape
7. excel_list=[]用于存储误差
8. for i in range(prediction.shape[2]):
确保 data_target_tensor和prediction的shape一致
对数据data_target_tensor[:, :, i]和prediction[:, :, i]求误差
if metric_method == 'mask':
计算mae,rmse,mape并打印结果
if metric_method == 'unmask'
计算mae,rmse,mape并打印结果
[mae,rmse,mape]放入excel_list
9. if metric_method == 'mask':
对数据data_target_tensor.reshape(-1, 1),和prediction.reshape(-1, 1)求误差
计算mae,rmse,mape
10. if metric_method == 'ummask':
对数据data_target_tensor.reshape(-1, 1),和prediction.reshape(-1, 1)求误差
计算mae,rmse,mape
11. 打印mae,rmse,mape这个总结果,并放入excel_list中
def predict_and_save_results_mstgcn ( net, data_loader, data_target_tensor, global_step, metric_method, _mean, _std, params_path, type ) :
net. train( False )
with torch. no_grad( ) :
data_target_tensor = data_target_tensor. cpu( ) . numpy( )
loader_length = len ( data_loader)
prediction = [ ]
input = [ ]
for batch_index, batch_data in enumerate ( data_loader) :
encoder_inputs, labels = batch_data
input . append( encoder_inputs[ : , : , 0 : 1 ] . cpu( ) . numpy( ) )
outputs = net( encoder_inputs)
prediction. append( outputs. detach( ) . cpu( ) . numpy( ) )
if batch_index % 100 == 0 :
print ( 'predicting data set batch %s / %s' % ( batch_index + 1 , loader_length) )
input = np. concatenate( input , 0 )
input = re_normalization( input , _mean, _std)
prediction = np. concatenate( prediction, 0 )
print ( 'input:' , input . shape)
print ( 'prediction:' , prediction. shape)
print ( 'data_target_tensor:' , data_target_tensor. shape)
output_filename = os. path. join( params_path, 'output_epoch_%s_%s' % ( global_step, type ) )
np. savez( output_filename, input = input , prediction= prediction, data_target_tensor= data_target_tensor)
excel_list = [ ]
prediction_length = prediction. shape[ 2 ]
for i in range ( prediction_length) :
assert data_target_tensor. shape[ 0 ] == prediction. shape[ 0 ]
print ( 'current epoch: %s, predict %s points' % ( global_step, i) )
if metric_method == 'mask' :
mae = masked_mae_test( data_target_tensor[ : , : , i] , prediction[ : , : , i] , 0.0 )
rmse = masked_rmse_test( data_target_tensor[ : , : , i] , prediction[ : , : , i] , 0.0 )
mape = masked_mape_np( data_target_tensor[ : , : , i] , prediction[ : , : , i] , 0 )
else :
mae = mean_absolute_error( data_target_tensor[ : , : , i] , prediction[ : , : , i] )
rmse = mean_squared_error( data_target_tensor[ : , : , i] , prediction[ : , : , i] ) ** 0.5
mape = masked_mape_np( data_target_tensor[ : , : , i] , prediction[ : , : , i] , 0 )
print ( 'MAE: %.2f' % ( mae) )
print ( 'RMSE: %.2f' % ( rmse) )
print ( 'MAPE: %.2f' % ( mape) )
excel_list. extend( [ mae, rmse, mape] )
if metric_method == 'mask' :
mae = masked_mae_test( data_target_tensor. reshape( - 1 , 1 ) , prediction. reshape( - 1 , 1 ) , 0.0 )
rmse = masked_rmse_test( data_target_tensor. reshape( - 1 , 1 ) , prediction. reshape( - 1 , 1 ) , 0.0 )
mape = masked_mape_np( data_target_tensor. reshape( - 1 , 1 ) , prediction. reshape( - 1 , 1 ) , 0 )
else :
mae = mean_absolute_error( data_target_tensor. reshape( - 1 , 1 ) , prediction. reshape( - 1 , 1 ) )
rmse = mean_squared_error( data_target_tensor. reshape( - 1 , 1 ) , prediction. reshape( - 1 , 1 ) ) ** 0.5
mape = masked_mape_np( data_target_tensor. reshape( - 1 , 1 ) , prediction. reshape( - 1 , 1 ) , 0 )
print ( 'all MAE: %.2f' % ( mae) )
print ( 'all RMSE: %.2f' % ( rmse) )
print ( 'all MAPE: %.2f' % ( mape) )
excel_list. extend( [ mae, rmse, mape] )
print ( excel_list)
























 3413
3413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









