






pandas借助python爬虫爬取网页html表格保存到excel文件
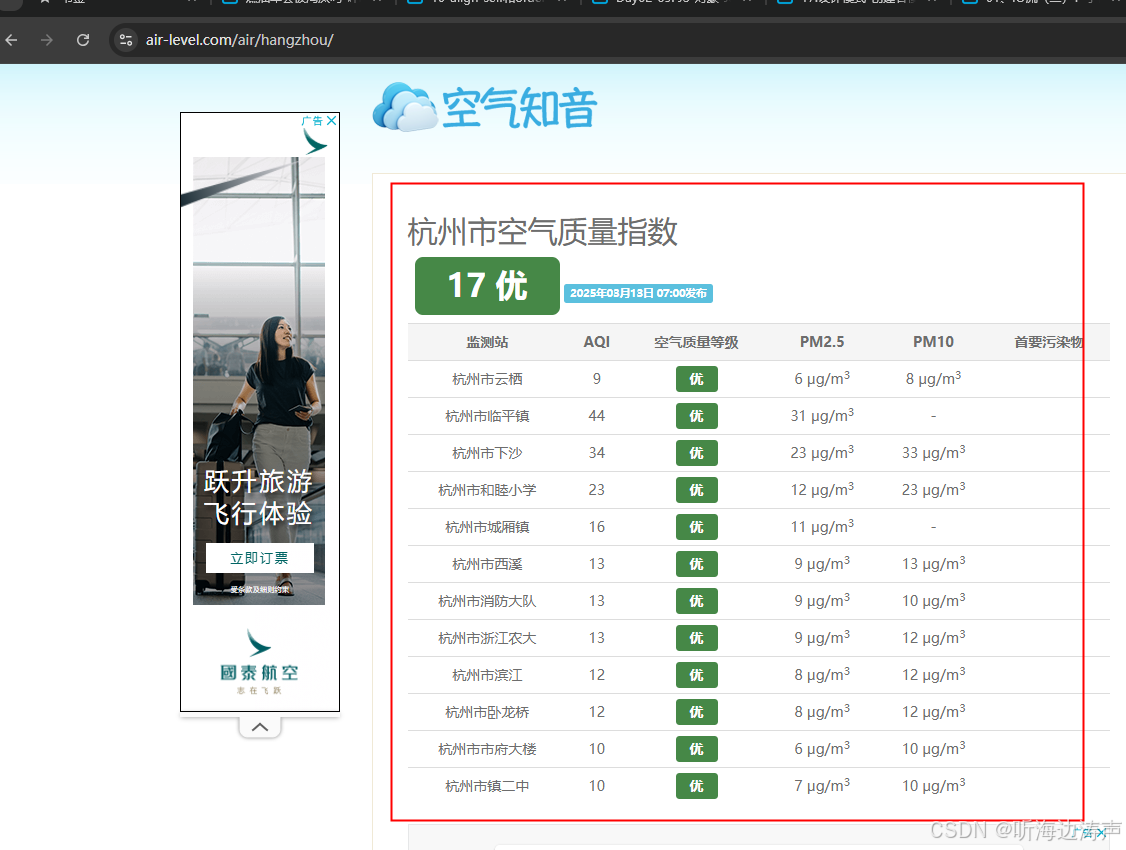
目标:将下面网页中的内容https://www.air-level.com/air/hangzhou/ 爬取下来,输出到excel中。
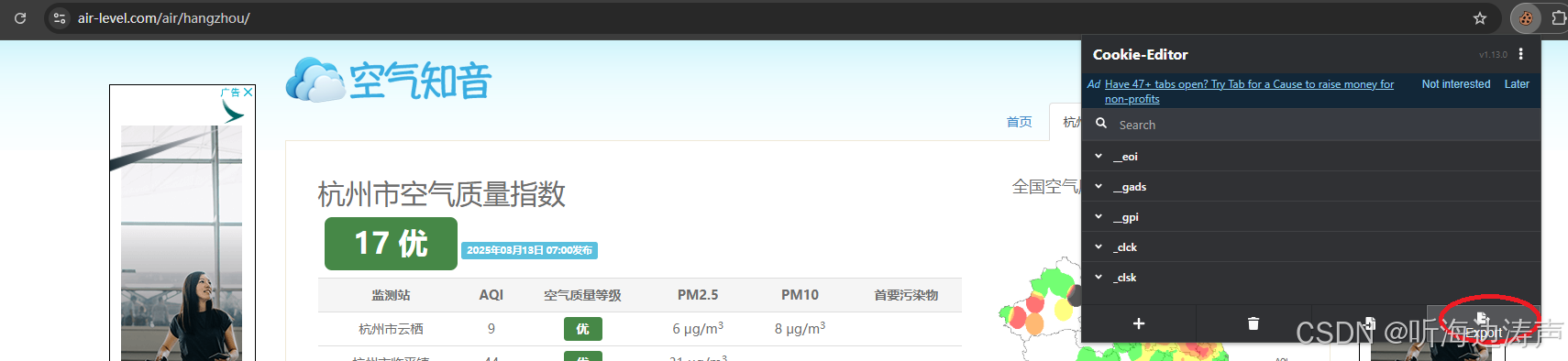
第1步:复制cookie到文件
这步的作用:通过python代码爬取的时候,可能有的网站限制,所以可以自己先用浏览器访问网站,获取到cookie,然后在python代码爬取的时候带上cookie。
我已经在chrome浏览器上安装了Cookie-Editor插件,如果不能访问chrome插件的官网,可以到https://crxdl.com/搜索下载。
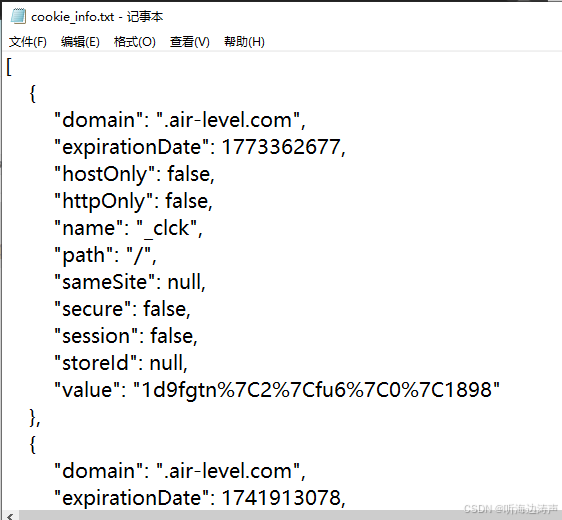
导出cookie为JSON格式(是在剪贴板中):
然后粘贴到文本文件中:
导入包:
import pandas as pd
import requests
构建RequestsCookieJar:
cookie_jar = requests.cookies.RequestsCookieJar()
with open('./cookie_info.txt') as f:
cookie_json = json.loads(f.read())
for cookie in cookie_json:
cookie_jar.set(name=cookie['name'], value=cookie['value'], domain=cookie['domain'], path=cookie['path'])
执行,看看生成的RequestsCookieJar:

第2步:将html的内容爬取下来
访问网址,爬取内容:
url = 'https://www.air-level.com/air/hangzhou/'
res = requests.get(url, cookies=cookie_jar)
看看响应:
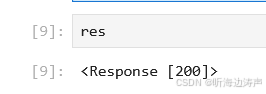
可以看到,响应成功了。
看看响应的内容:

第3步:使用pandas解析网页中的表格
将响应内容封装为StringIO:
from io import StringIO
html_content = StringIO(res.text)
用pandas读取返回内容中的表格:
df = pd.read_html(html_content)
查看读取的内容:
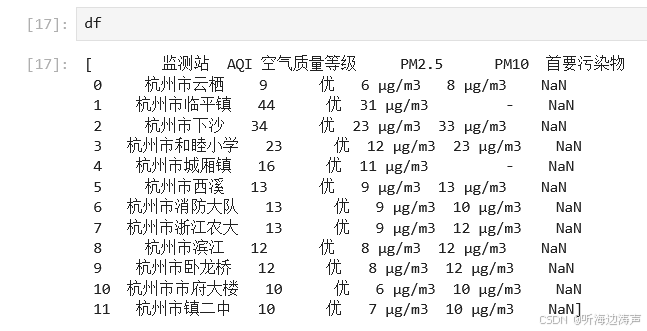
看看df的数据类型:
看看列表的长度:
看看列表中元素的数据类型:

可以看到,列表元素的类型是DataFrame。
查看列表中第一项的内容:
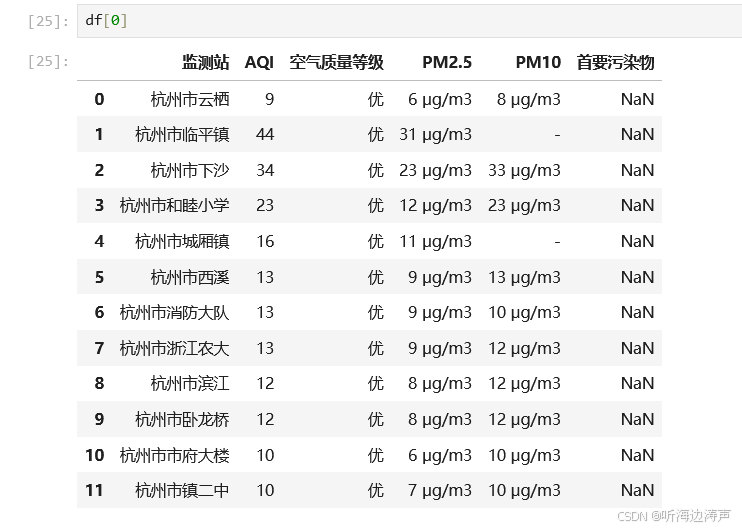
第4步:将结果输出到excel文件
df[0].to_excel('杭州市空气质量指数.xlsx', index=False)
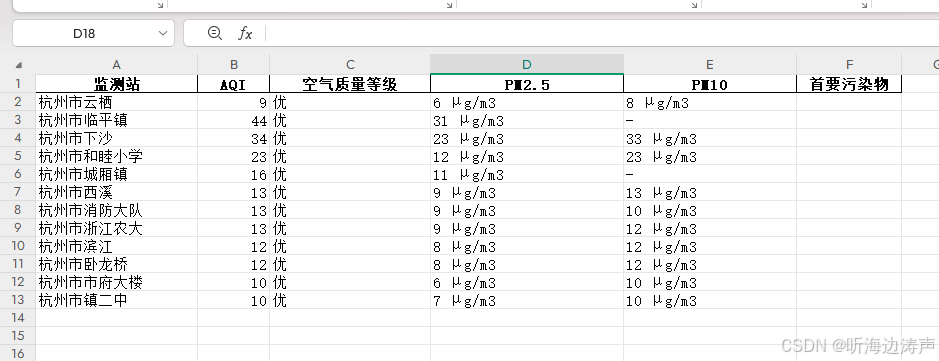
运行,查看输出文件的内容:

















 6122
6122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









