







Single-byte XOR cipher
string:
1b37373331363f78151b7f2b783431333d78397828372d363c78373e783a393b3736
descript:
... has been XOR'd against a single character. Find the key, decrypt the message.
You can do this by hand. But don't: write code to do it for you.
How? Devise some method for "scoring" a piece of English plaintext. Character frequency is a good metric. Evaluate each output and choose the one with the best score.
观察string,首先他们是十六进制的,应该是ascii编码
string:
1b 37 37 33 31 36 3f 78 15 1b 7f 2b 78 34 31 33 3d 78 39 78 28 37 2d 36 3c 78 37 3e 78 3a 39 3b 37 36
descript 告诉我们 XOR a single character。并且告诉我们可以使用 scoring a piece of English plaintext的这样一种方式,嗯… 就是character frequency 词频
嗯…什么意思呢 就是string XOR了一个character。我们可以通过枚举a-z 找出 正确的string ,而这个正确的string是一堆英文,我们可以通过词频,也就是制作一份英文词频表,使用它来确定纯英文文本(比如,这道题所枚举出的26种string),用于计数,并显示相应字母的使用比率。
至于output the best score 就是希望我们将输出与自己期望的输出进行对比,比较,进而获得正确的答案
其实说白了就是,我们对问题有一定根据的猜测,根据这个猜测来接近问题答案
当然,descript还说 don‘t write code to do it ,我当然是忽视啦,手动异或是在是烦死了
Single-byte XOR
最初的版本:
#set1_3
import string
s='1b37373331363f78151b7f2b783431333d78397828372d363c78373e783a393b3736'
#print(int('0x1b',16))
for j in string.ascii_letters:
#print(j)
t=''
for i in range(0,len(s),2):
temp=int('0x'+s[i:i+2],16)
#print(t)
t=t+str(chr(temp^ord(j)))
print(f'{j}:{t}')
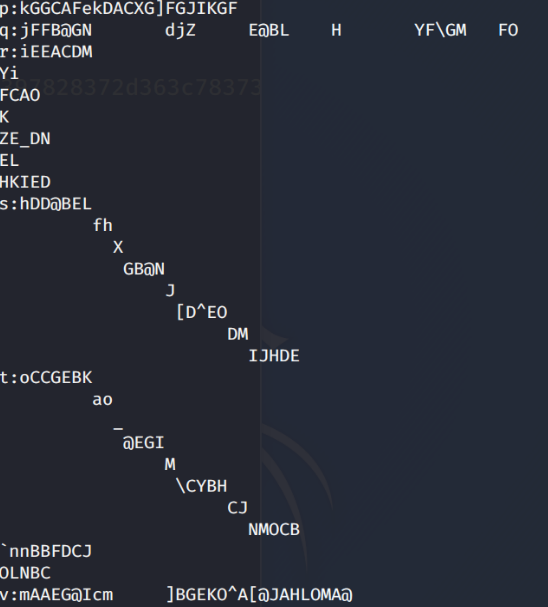
我们发现此时有些编码很奇怪,就和上面的一样,或者是其他奇怪的东西。
经过测定输出,我们会发现有些异或后出现的编码存在控制字符 \x00-\x1F 之间。我们需要将其删除。
这里可以使用正则表达式来删除。这里我用了一个 re.sub 这样一个模块函数
python使用手册:https://docs.python.org/zh-tw/3.8/library/re.html
re.sub详解:https://blog.csdn.net/mrzhoug/article/details/51585615
t=re.sub(r'[\x00-\x1F]+','', t)
#remove the ascii control charachers
#set1_3
import string
import re
s='1b37373331363f78151b7f2b783431333d78397828372d363c78373e783a393b3736'
#print(int('0x1b',16))
for j in string.ascii_letters:
#print(j)
t=''
for i in range(0,len(s),2):
temp=int('0x'+s[i:i+2] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3414
3414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









