







目录
一、前言
作为"资本家",你要尽可能的榨取 CPU,内存与 IO 的剩余价值,但三者完成任务的速度相差很大,CPU > 内存 > IO分,CPU 是天,那内存就是地,内存是天,那 IO 就是地,那怎样平衡三者,提升整体速度呢?
- CPU 增加缓存,还不止一层缓存,平衡内存的慢
- CPU 能者多劳,通过分时复用,平衡 IO 的速度差异
- 优化编译指令
上面的方式貌似解决了木桶短板问题,但同时这种解决方案也伴随着产生新的可⻅性,原子性,和有序性的问题
二、三大问题
1.可见性
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可⻅性
谈到可⻅性,要先引出 JMM (Java Memory Model) 概念, 即 Java 内存模型,Java 内存模型规定,将所有的变量都存放在主内存 中。当线程使用变量时,会把主内存里面的变量复制到自己的工作空间或者叫作私有内存 ,线程读写变量时操作的是自己工作内存中的变量。
用 Git 的工作流程理解上面的描述就很简单了,Git 远程仓库就是主内存,Git 本地 仓库就是自己的工作内存

看这个场景
1. 主内存中有变量 x,初始值为 0
2. 线程 A 要将 x 加 1,先将 x=0 拷⻉到自己的私有内存中,然后更新 x 的值
3. 线程 A 将更新后的 x 值回刷到主内存的时间是不固定的
4. 刚好在线程 A 没有回刷 x 到主内存时,线程 B 同样从主内存中读取 x,此时为 0,和线程 A一样的操作,最后期盼的 x=2 就会变成 x=1
JMM 是一个抽象的概念,在实际实现中线程的工作内存是这样的

为了平衡内存/IO 短板,会在 CPU 上增加缓存,每个核都只有自己的一级缓存,甚 至有一个所有 CPU 都共享的二级缓存。
从上图中你也可以看出,在 Java 中,所有的实例域,静态域和数组元素都存储在堆内存中,堆内存在线程之间共享,这些在后续文章中都称之为「共享变量」。局部变量,方法定义参数和异常处理器参数不会在线程之间共享,所以他们不会有内存可⻅性的问题,也就不受内存模型的影响。
一句话,要想解决多线程可⻅性问题,所有线程都必须要刷取主内存中的变量。怎么解决可⻅性问题呢?Java 关键字 volatile 帮你搞定
2.原子性
所谓原子操作是指不会被线程调度机制打断的操作。 这种操作一旦开始,就一 直运行到结束,中间不会有任何 context switch
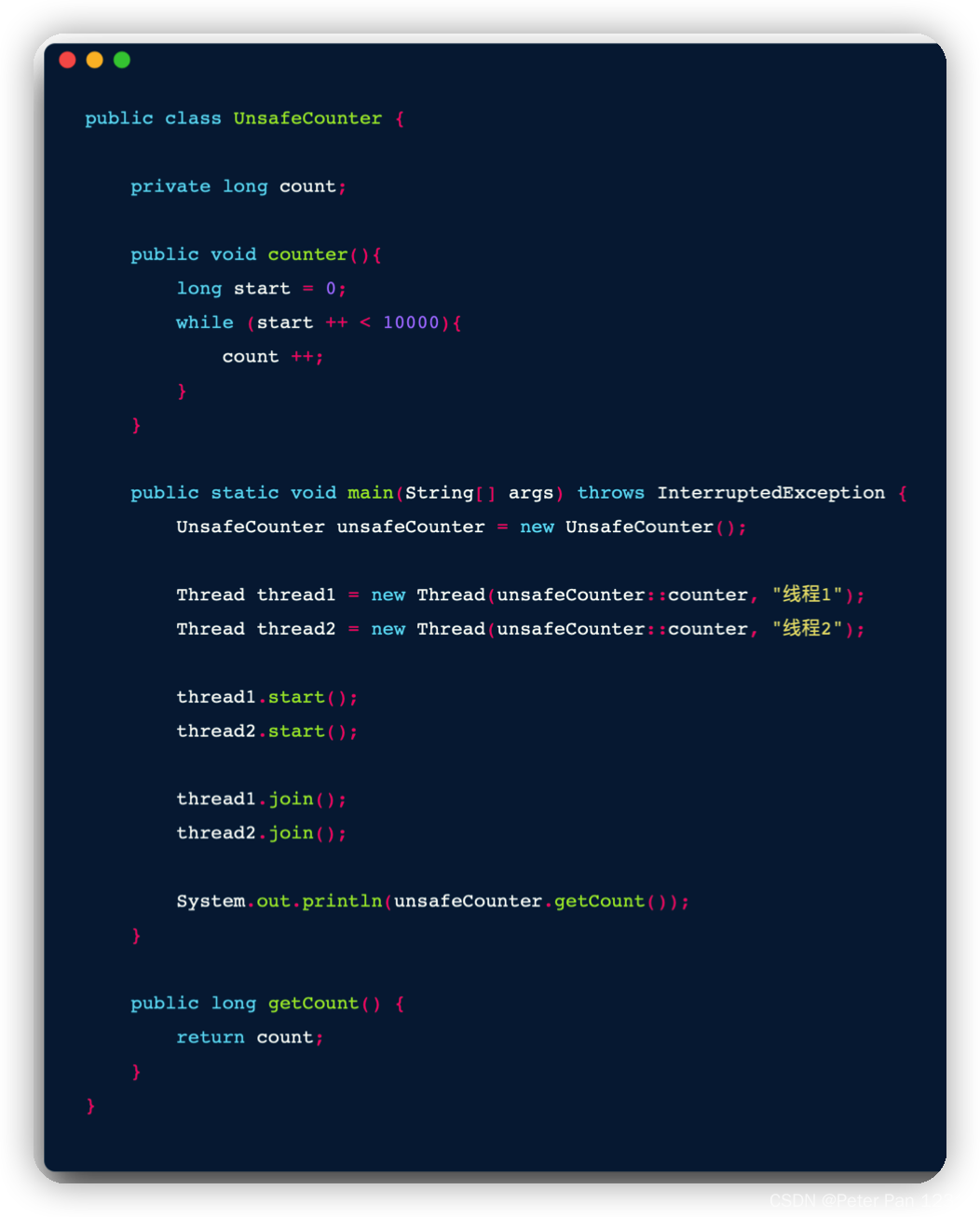
多线程情况下能得到我们期盼的 count = 20000 的值吗? 也许有同学会认为,线程调用的 counter 方法只有一个 count++ 操作,是单一操作,所以是原子性的,非也。在线程第一讲中说过我们不能用高级语言思维来理解 CPU 的处理方式, count++ 转换成 CPU 指令则需要三步

16 : 获取当前 count 值,并且放入栈顶
19 : 将常量 1 放入栈顶
20 : 将当前栈顶中两个值相加,并把结果放入栈顶
21 : 把栈顶的结果再赋值给 count
简单的 count++ 不是一步操作,被转换为汇编后就不具备原子性了,就 好比大象装冰箱,其实要分三步:
第一步,把冰箱⻔打开
第二步,把大象放进去
第三步,把冰箱⻔带上
结合 JMM 结构图理解,说明一下为什么很难得到 count=20000 的结果

多线程计数器,如何保证多个操作的原子性呢? 最粗暴的方式是在方法上加 synchronized 关键字,比如这样:

3.有序性
生活中你问候他人「吃了吗你?」和「你吃了吗?」是一个意思,你写的是下面程序:
a = 1;
b = 2;
System.out.println(a);
System.out.println(b);编译器优化后可能就变成了这样
b = 2;
a = 1;
System.out.println(a);
System.out.println(b);编译器调整了语句顺序没什么影响,但编译器擅自优化顺序,就给我们埋下了雷,比如应用双重检查方式实现的单例

问题出现在 instance = new Singleton(); ,这 1 行代码转换成了 CPU 指令后又变成了 3 个,我们理解 new 对象应该是这样的
1. 分配一块内存 M
2. 在内存 M 上初始化 Singleton 对象3. 然后 M 的地址赋值给 instance 变量
但编译器擅自优化后可能就变成了这样:
1. 分配一块内存 M
2. 然后将 M 的地址赋值给 instance 变量3. 在内存 M 上初始化 Singleton 对象
编译器优化后的 顺序可能导致问题的发生
线程 A 先执行 getInstance 方法,当执行到指令 2 时,恰好发生了线程切换
线程 B 刚进入到 getInstance 方法,判断 if 语句 instance 是否为空
线程 A 已经将 M 的地址赋值给了 instance 变量,所以线程 B 认为 instance 不为
空
线程 B 直接 return instance 变量
CPU 切换回线程 A,线程 A 完成后续初始化内容
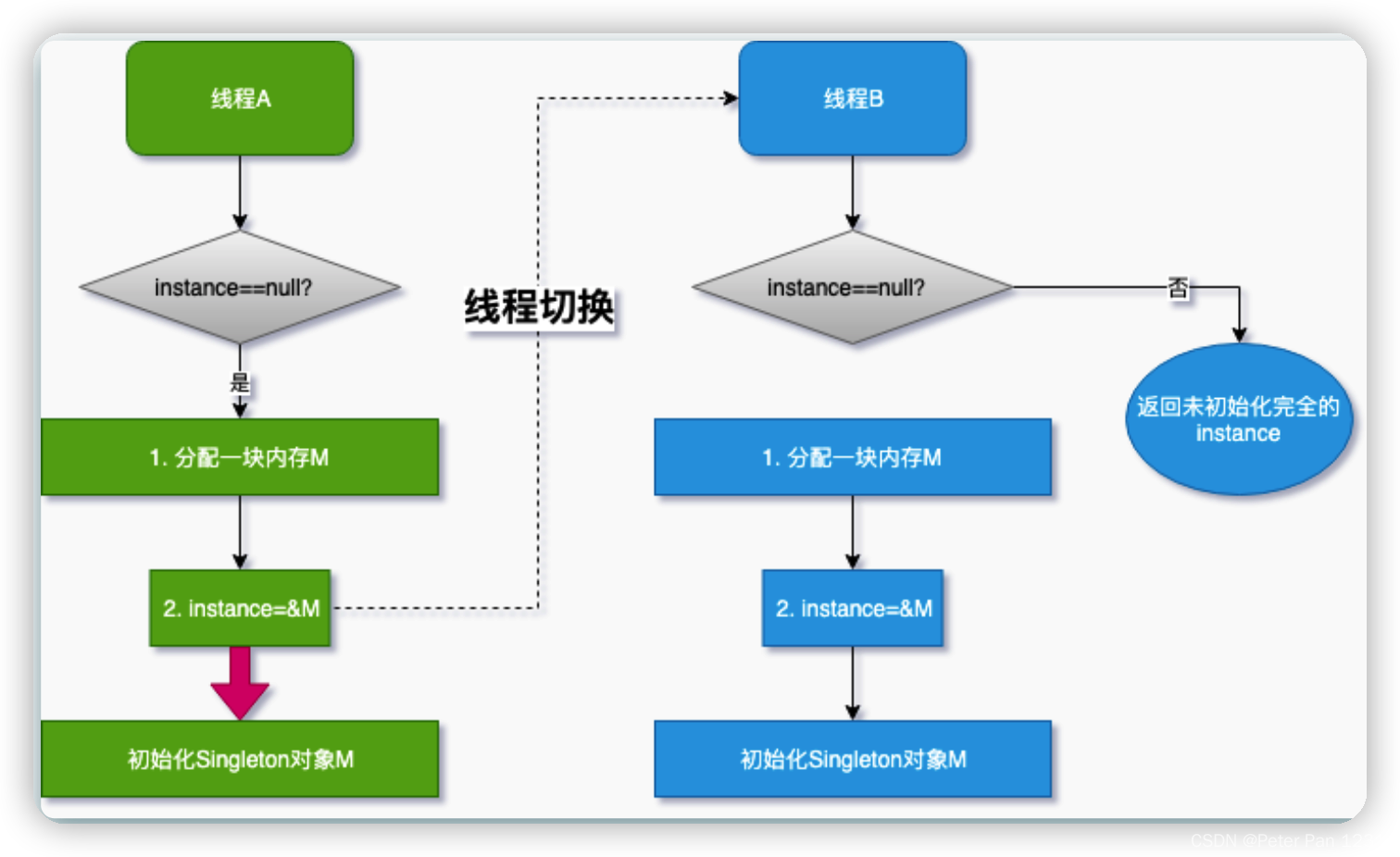
如果线程 A 执行到第 2 步,线程切换,由于线程 A 没有把红色箭头执行完全,线程 B 就会得到一个未初始化完全的对象,访问 instance 成员变量的时候就可能发生 NPE,如果将变量 instance 用 volatile 或者 final 修饰,问题就解决了.














 3543
3543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









