







 本文介绍了如何利用ChatGLM-6B和langchain技术构建个人知识库,通过向量嵌入和余弦相似度匹配,实现快速查询并结合LLM模型进行问题解答。文章详细描述了技术原理、应用场景和部署步骤,以及模型的使用注意事项.
本文介绍了如何利用ChatGLM-6B和langchain技术构建个人知识库,通过向量嵌入和余弦相似度匹配,实现快速查询并结合LLM模型进行问题解答。文章详细描述了技术原理、应用场景和部署步骤,以及模型的使用注意事项.
利用 ChatGLM-6B + langchain 实现个人专属知识库
一、技术原理
项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt 中 -> 提交给 LLM 生成回答。
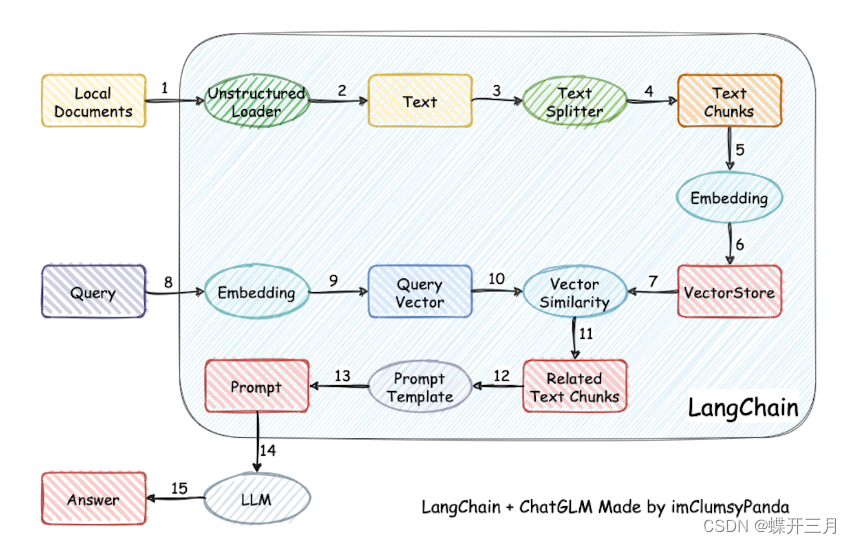
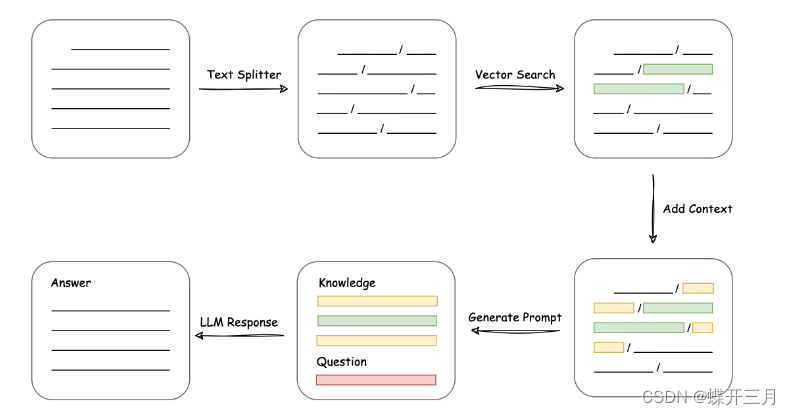
从上面就能看出,其核心技术就是向量 embedding,将用户知识库内容经过 embedding 存入向量知识库,然后用户每一次提问也会经过 embedding,利用向量相关性算法(例如余弦算法)找到最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 promt 提交给 LLM 回答。一个典型的 prompt 模板如下:
"""
已知信息:
{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}
"""
二、使用场景
可以调整 prompt,匹配不同的知识库,让 LLM 扮演不同的角色
- 上传公司财报,充当财务分析师
- 上传客服聊天记录,充当智能客服
- 上传经典Case,充当律师助手
- 上传医院百科全书,充当在线问诊医生
等等等等。。。。
三、实战
这里我们选用 langchain-ChatGLM 项目示例,其他的 LLM 模型对接知识库也是一个道理。
项目部署
环境准备好了以后,就可以开始准备部署工作了。
下载源码
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
安装依赖
cd langchain-ChatGLM
pip install -r requirements.txt
下载模型
# 安装 git lfs
git lfs install
# 下载 LLM 模型
git clone https://huggingface.co/THUDM/chatglm-6b /your_path/chatglm-6b
# 下载 Embedding 模型
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese /your_path/text2vec
# 模型需要更新时,可打开模型所在文件夹后拉取最新模型文件/代码
git pull
参数调整
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec": "/your_path/text2vec"
}
llm_model_dict = {
"chatyuan": "ClueAI/ChatYuan-large-v2",
"chatglm-6b-int4-qe": "THUDM/chatglm-6b-int4-qe",
"chatglm-6b-int4": "THUDM/chatglm-6b-int4",
"chatglm-6b-int8": "THUDM/chatglm-6b-int8",
"chatglm-6b": "/your_path/chatglm-6b",
}
Web 模式启动
pip install gradio
python webui.py模型配置

上传知识库

知识库问答

API 模式启动
python api.py
命令行模式启动
python cli_demo.py
亲测可用,但是回答的效果有点僵硬,特别要注意prompt格式,对回答效果影响很大,比起微调训练还是差点















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









