










文章目录
1、LLM大语言模型的原理
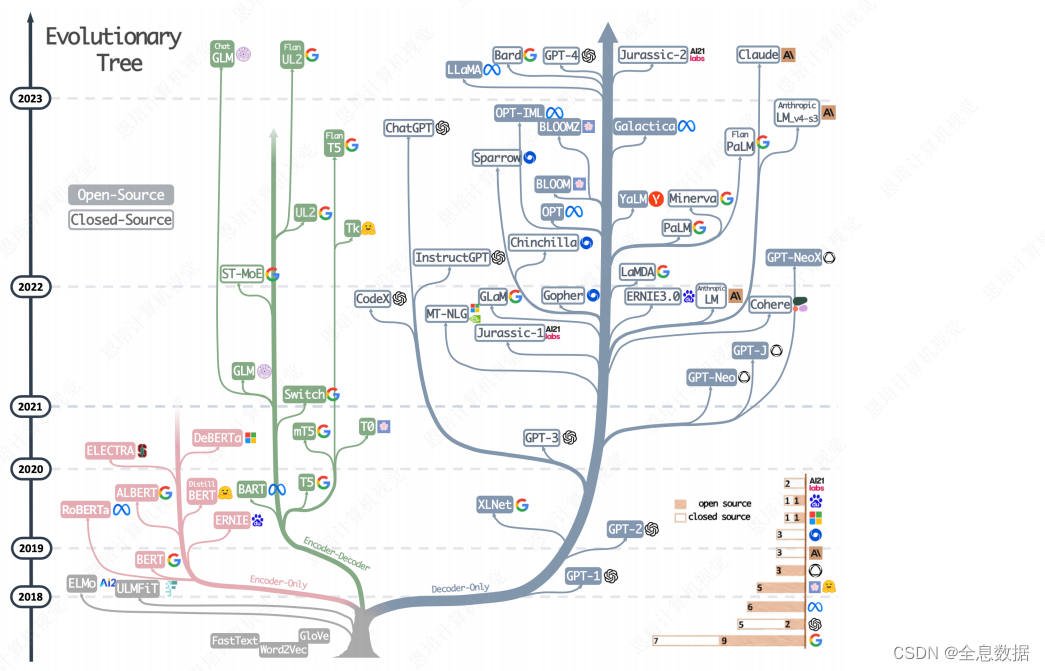
1.1 大语言模型LLM发展
除了下图左下最底侧棕(或灰)色的分支没有使用transformer(trm),其他分支都使用了trm,
1.2 Transformer的介绍
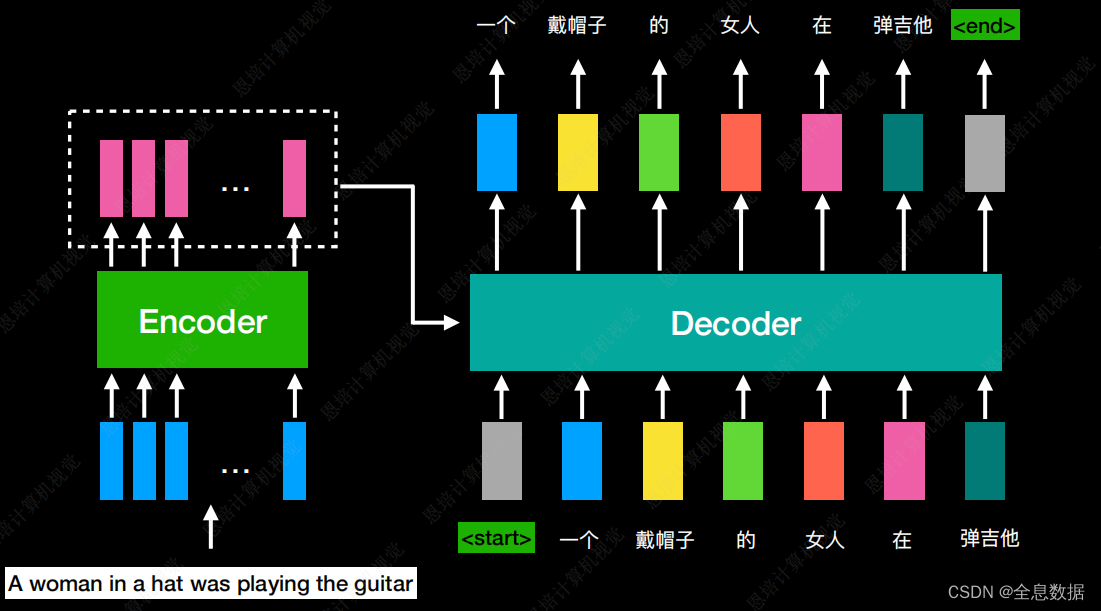
左边是Encoding,右边是Decoding,

trm的输入和输出都可以是序列,所以trm可以做文本翻译,
1.2.1 Encoder
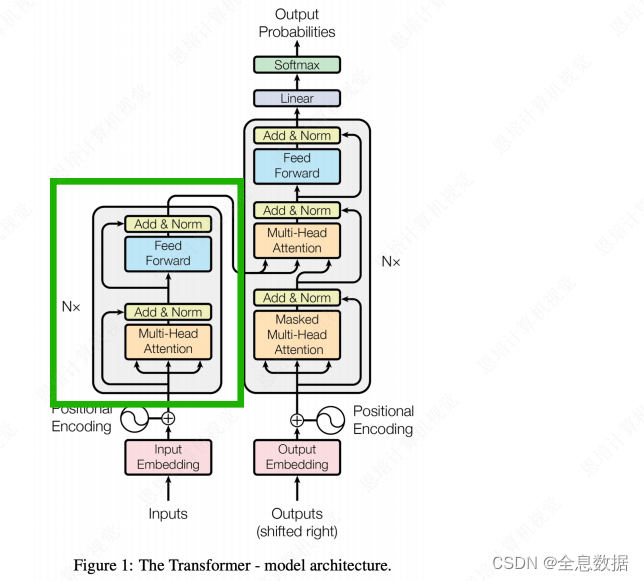
如下左图即是Encoder,
Encoder可以分为多个block,每个block输入和输出都是向量,block的结构如下图右半部分,包含残差结构,自注意力,Layer Norm,FC,
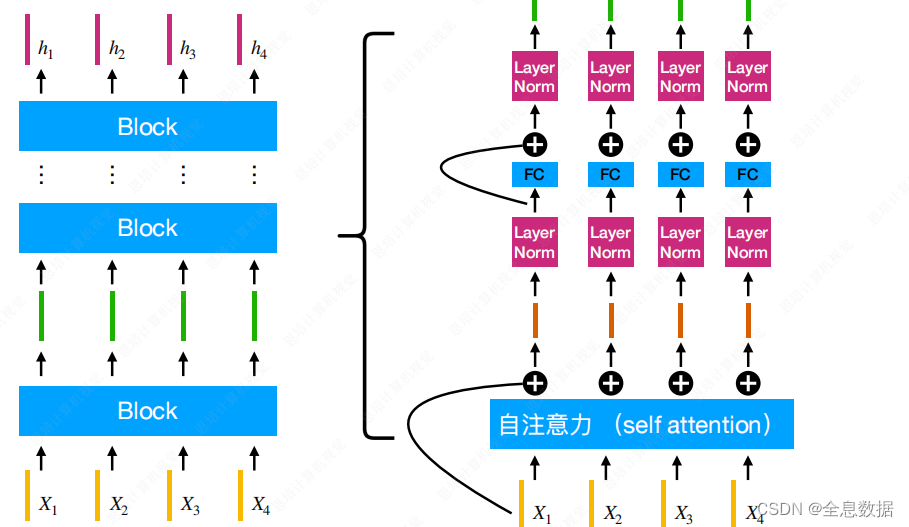
自注意力机制:
每一个输出要考虑到所有的输入,
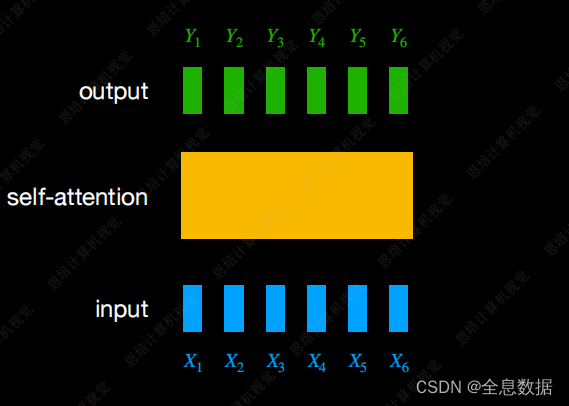
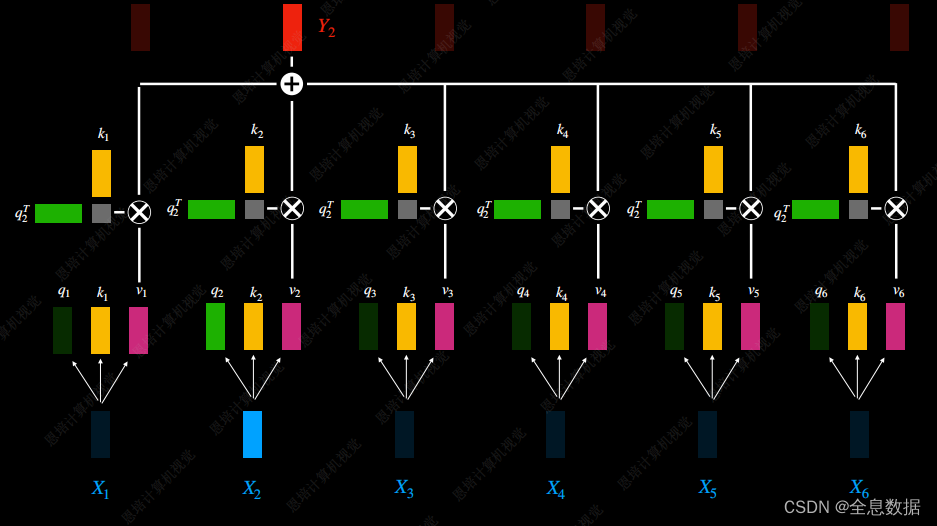
Y 2 Y_2 Y2的输出由 X 1 X_1 X1— X 6 X_6 X6决定,由自注意力机制决定每个输入的权重,
1.2.2 Decoder
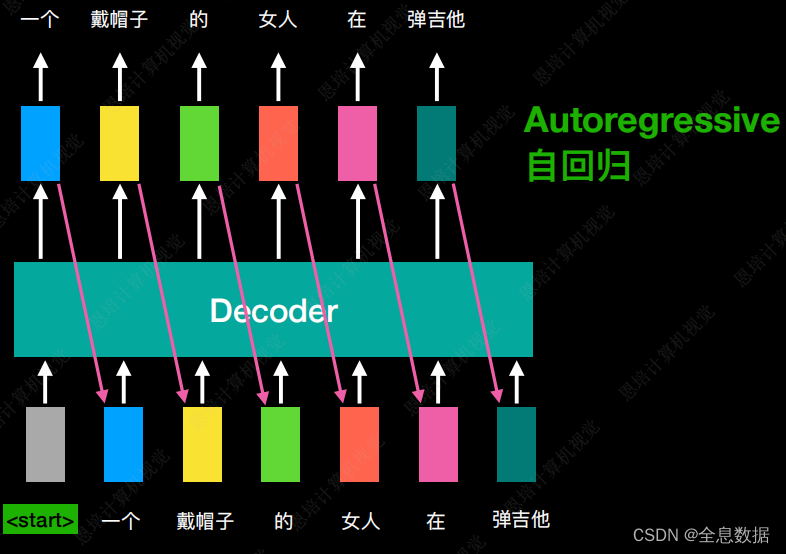
首先Decoder会将Encoder的输出作为输入,然后再给一个特殊的token符号,这个符号代表开始,以start为标志,这个特殊的符号可以选择任意一段字符,只要和输出的中文不一样就行,然后Decoder会吐出1个向量,向量的大小和输出的中文词汇数量一致,输出的每一个单词会对应一个概率值,最后选出概率最大的一个词,下图对应的输出为“一个”,
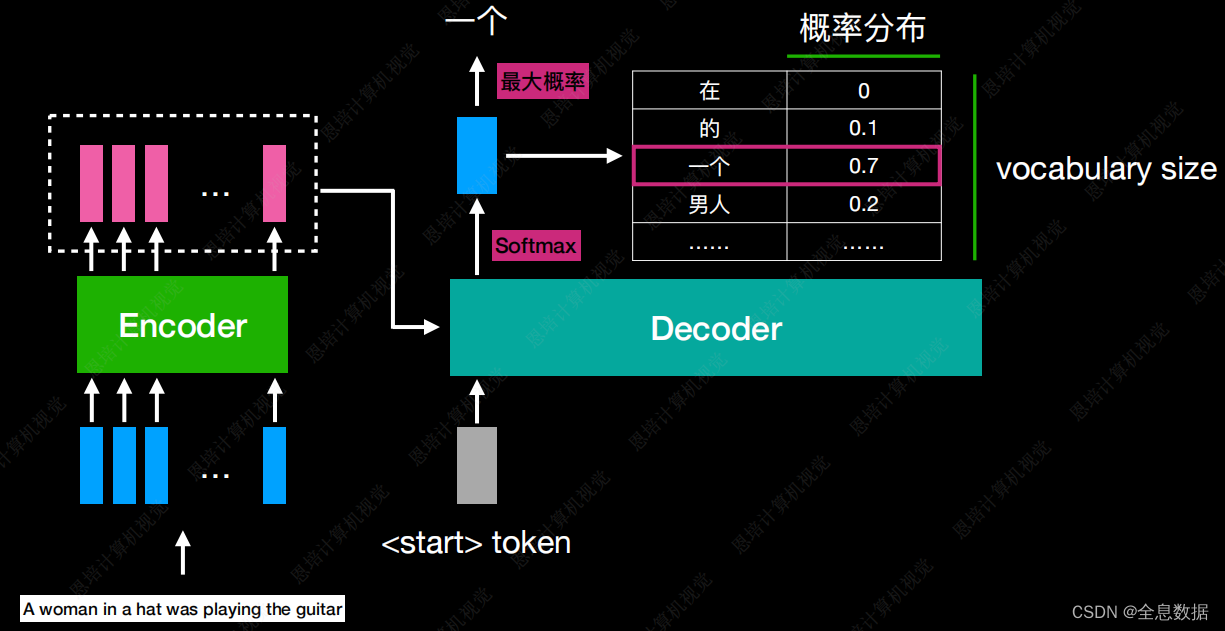
- 然后将上一个的输出“一个”作为下次的输入,Decoder根据“<start>”和“一个”作为输入,输出为“戴帽子”,然后以此类推。Decoder的输入为Decoder某个时间点的输出,这种流程叫Autoregressive(自回归),
- 这种流程有一个缺点就是会像成语接龙一样一直不断地输出,所以我们希望Decoder会输出一个<end>符号,让Decoder停止输出,

Decoder会比Encoder多出来下面绿色阴影的部分,
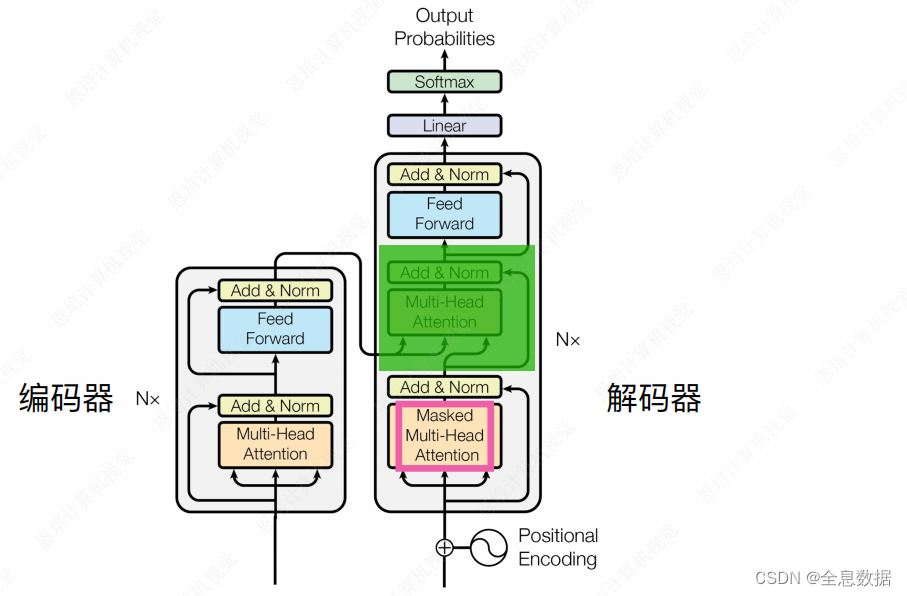
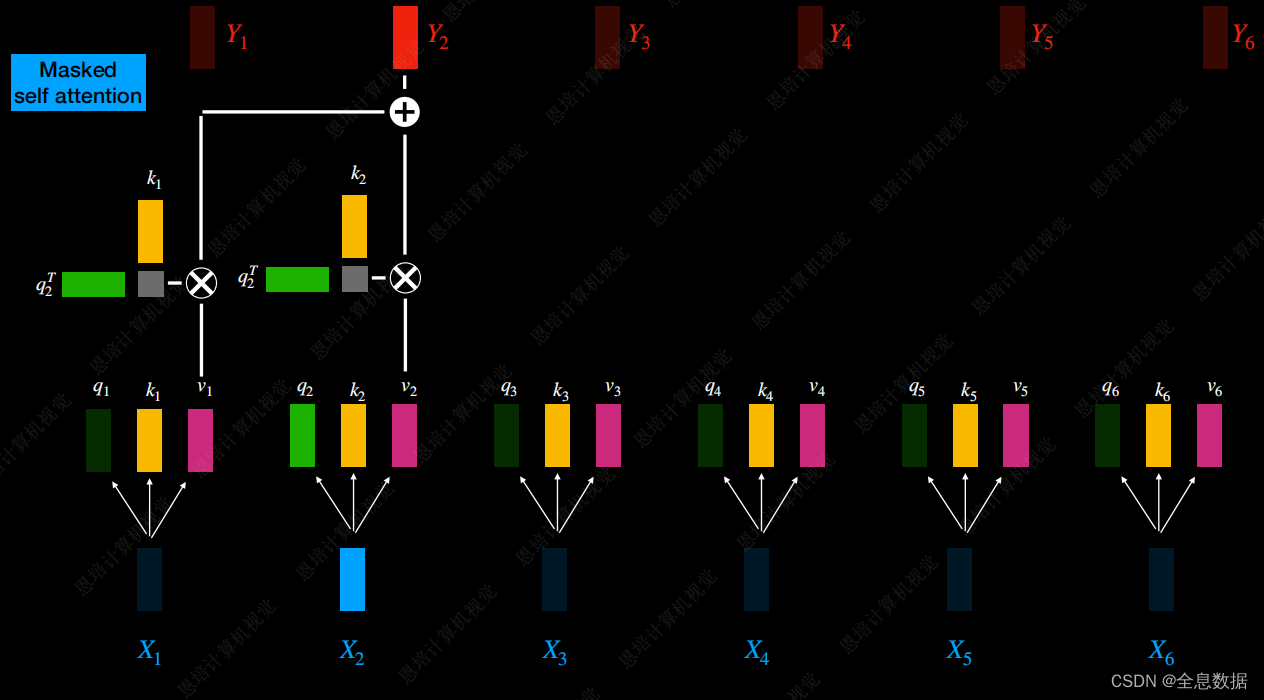
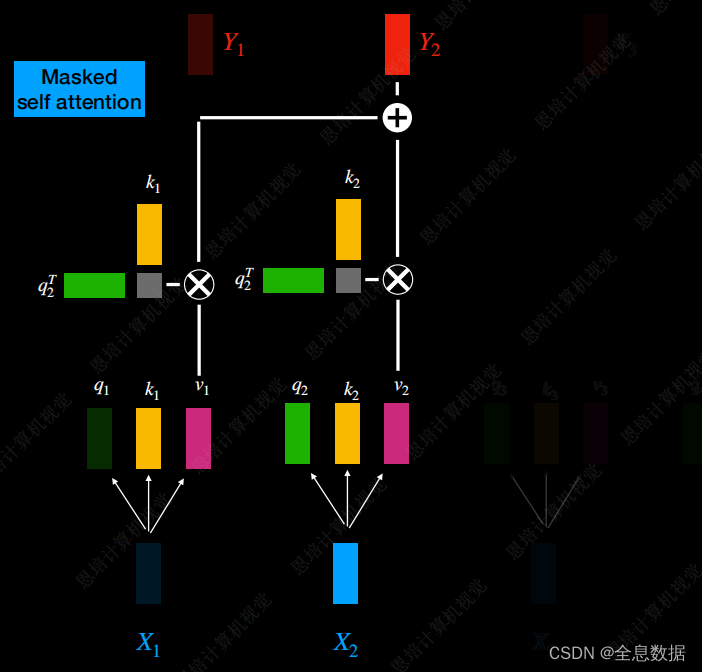
Masked Multi-Head Attention:
在 Multi-Head Attention中, Y 2 Y_2 Y2与 X 1 X_1 X1— X 6 X_6 X6的输入有关,而在Masked Multi-Head Attention中, Y 2 Y_2 Y2仅与 X 1 X_1 X1— X 2 X_2 X2的输入有关, Y 3 Y_3 Y3仅与 X 1 X_1 X1— X 3 X_3 X3的输入有关,这与Encoder和Decoder的输入输出有关,
2、BERT
2.1 Token编码
One-hot Ecoding (1-of-n Encoding):
采用One-hot Ecoding,有2个明显的缺点,其一它的维度与需要编码的词汇数量一致,如果词汇量很大那么编码的维度也很大,其二使用One-hot Ecoding无法体现词汇之间的关系,

Word Embedding:
使用Word Embedding可以自己定义向量的长度,然后通过大量数据的预训练,可以将句法信息也编码进来,可以体现词汇之间的关系,
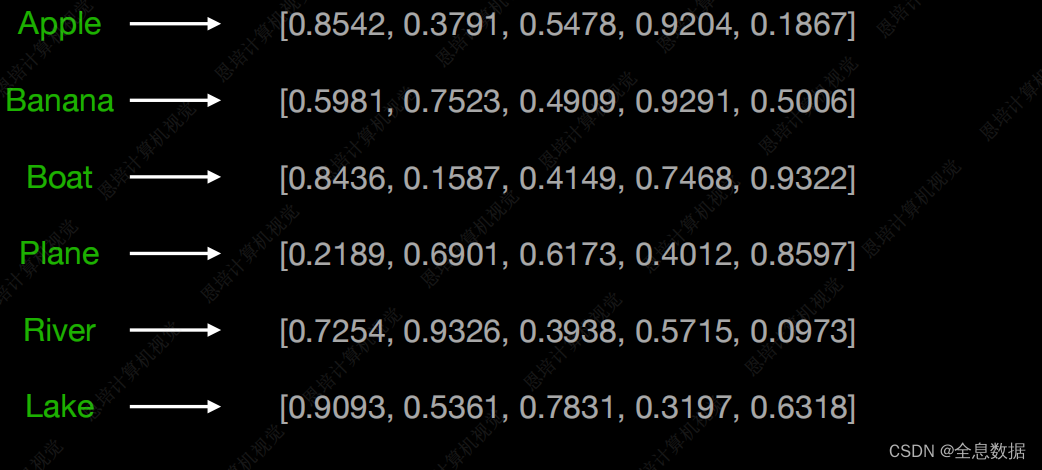
如下图,使用Word Embedding将不同词语之间的关系表示出来,

2.2 BERT介绍
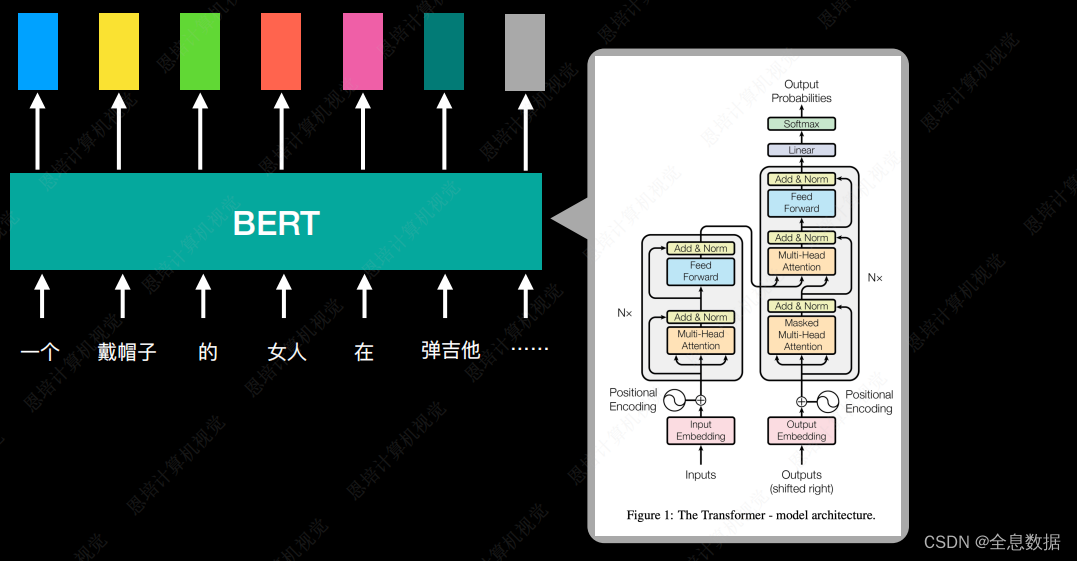
BERT是Bidirectional Encoder Representations from Transformers的缩写,
- BERT是Transformer的Encoder
- 一个预训练的语言表征模型
- 在大量未标注的文本数据集上训练
- 论文发表时在11个NLP任务上取得最佳指标
- BERT所做的事情就是把一个句子输出一个Embedding,
- 预训练后,只需额外添加输出层进行fine-tune,便可在其他下游任务(如分类、标注、摘要、问答等)中取得不错的表现
- 利用大规模文本数据的自监督性质来构建预训练任务,
2.3 BERT的训练
A、Masked Language Model
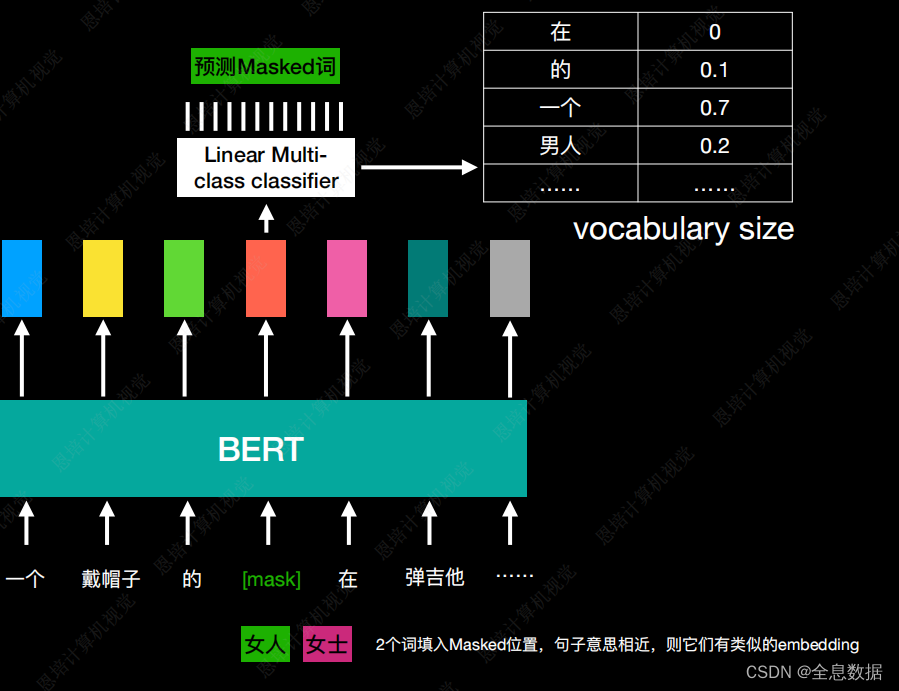
将一个句子随机地将15%替换为特殊的token,特殊的token可以用mask,然后将这个句子输入给BERT,BERT根据每个token输出每个Embedding,再将mask的Embedding输入到Linear Multi-class classifier,让它预测mask的值,Linear Multi-class classifier性能较弱,所以要求BERT的层数较深,
B、Next Sentence Prediction
这种训练方式让BERT判断2个句子是否连在一起,如下图2个句子分别是“提供一段代码”和“输出当前时间戳”,下图中特殊的token SEP代表2个句子的边界,另一个特殊的token是CLS,经过BERT输出为Embedding,再经过Linear Binary classifier 分类器输出YES或者NO,用来判断2个句子是否可以连在一起,

2.4 BERT的使用
A、文本分类
- 输入:一句话
- 输出:类别
- 例子:文档分类、文本情感分类
- 需要注意:BERT只需要微调,而Linear classifier需要完整训练参数,
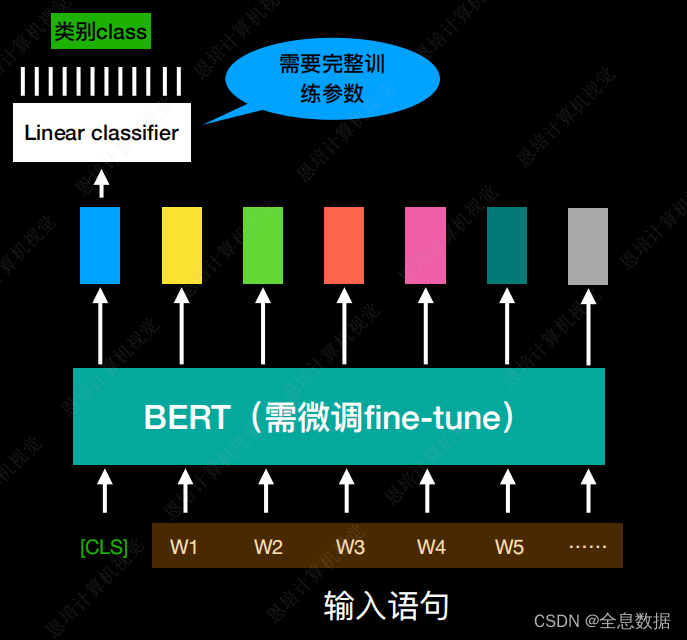
B、槽填充 slot filling
- 输入:一句话
- 输出:每个词的类别
- 如下图,判断一句话每个词的类别,
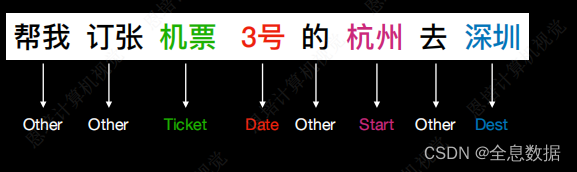
输入的语句经过BERT输出Embedding,再经过Linear classiifier输出每个词语的类别,同样的BERT需要微调,而Linear classiifier需要从头开始训练,

C、自然语言推断(inference)
- 输入:2句话
- 输出:类别
- 给定一个前提(promise),判断假设(hypothesis)真/假/未知,
SEP是分割2个句子之间的token符号,CLS用来判断2个句子之间的关系,

3、GPT
- GPT是Generative Pre-training缩写,
- GPT是Transformer的Decoder,
- GPT1、GPT2、GPT3、ChatGPT…
关于Decoder的Masked self attention已经在前面说过一次了,
3.1 GPT-1架构、训练目标及NLP任务
- GPT-1使用了Decoder的结构,用来做文本预测和文本分类,
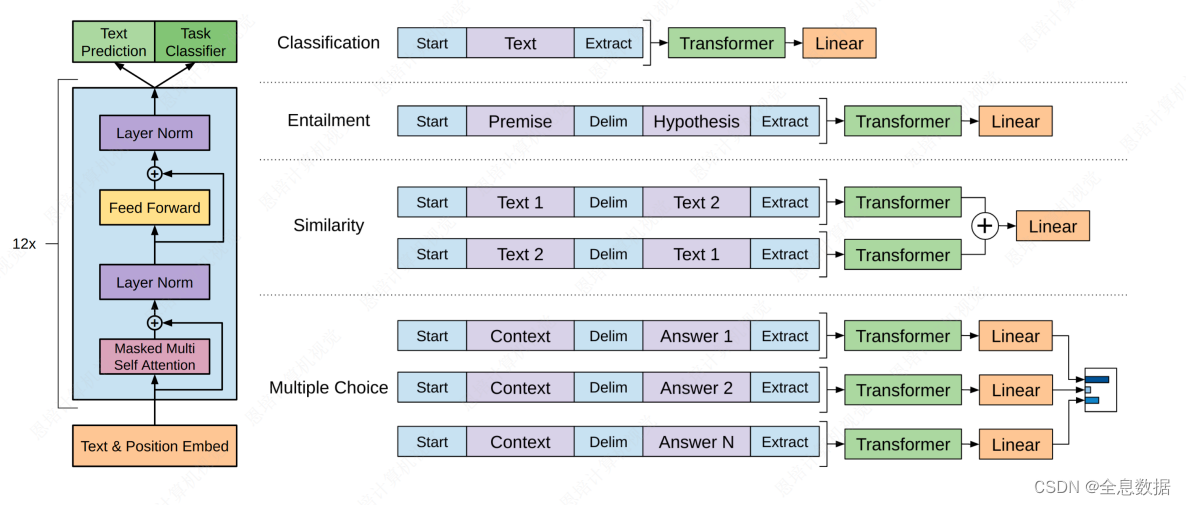
- 其中文本分类的做法和BERT类似,start作为开始token,Extract作为提取token,因为GPT-1使用了Decoder的结构,所以Extract只能放在末尾,再将Extract得到的Embedding输入给Linear进行分类,
- Entailment、Similarity、Multiple Choice和上面Classification的做法类似,最后都会经过trm层,再经Linear层,
3.2 GPT训练用的数据
A、GPT-1训练用的数据
GPT-1使用的数据集是BooksCorpus dataset,超过7000本未发表的书籍,

B、GPT-2 训练用的数据
通过爬虫爬取了4500万个网络链接,超过800万个文件,超过40 GB的文本,

3.3 GPT-2 zero-shot 零样本学习
- zero-shot是说在做NLP下游任务的时候不需要标注信息,也不需要训练这个模型,训练好的模型在任何地方都可以使用,
- 在做下游任务的时候,我们加入了一些特殊的token符号,















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









