







最新-常用匹配数据(DID大合集)-社科数据![]() https://download.csdn.net/download/paofuluolijiang/90028759
https://download.csdn.net/download/paofuluolijiang/90028759
在社会科学研究中,数据匹配是一项关键技术,它允许研究者将不同来源的数据集根据特定标准进行合并,以便进行更深入的分析。最新常用的数据匹配方法包括利用数据框架(DataFrame)的连接(concatenation)和合并(merge)功能。通过这些方法,研究者能够将两个或多个数据集的行或列根据一个或多个键(key)进行匹配和合并。例如,使用Python的Pandas库,可以通过`pd.concat`函数实现数据的上下或左右拼接。此外,`pd.merge`函数则类似于SQL中的JOIN操作,能够根据共同的键将两个数据集的行连接起来。通过指定不同的参数,如`how='inner'`或`how='outer'`,研究者可以选择内连接或外连接,以适应不同的数据分析需求。在实际操作中,研究者可能会遇到需要将一个表格中的数据匹配到另一个表中的情况。这通常涉及到使用VLOOKUP函数,该函数可以根据指定的键在另一个数据集中查找并返回相应的值。在使用VLOOKUP时,需要确保输入的符号是英文状态下的,并且所匹配的数据需要和当前数据不在同一个表格中,以避免匹配错误。
指标
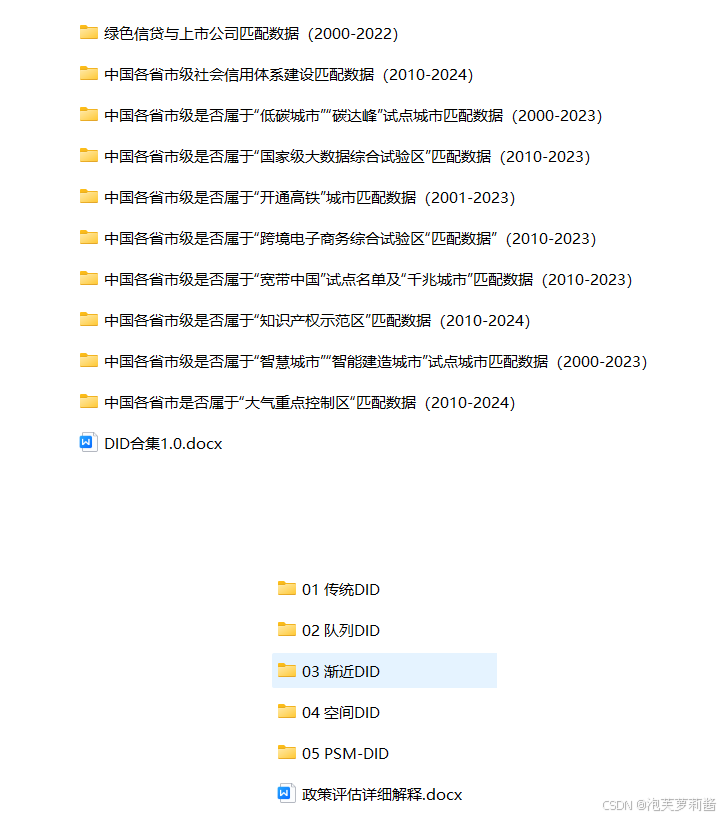
绿色信贷与上市公司匹配数据、中国各省市级社会信用体系建设匹配数据、中国各省市级是否属于“低碳城市”“碳达峰”试点城市匹配数据、中国各省市级是否属于“国家级大数据综合试验区”匹配数据、中国各省市级是否属于“开通高铁”城市匹配数据、中国各省市级是否属于“跨境电子商务综合试验区“匹配数据”、中国各省市级是否属于“宽带中国”试点名单及“千兆城市”匹配数据、中国各省市级是否属于“知识产权示范区”匹配数据、中国各省市级是否属于“智慧城市”“智能建造城市”试点城市匹配数据、中国各省市是否属于“大气重点控制区“匹配数据、DID模型。

















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









