







目录
一、PSM模型
1.1 倾向性得分匹配法(PSM)
PSM的核心思想是从未受干预的用户群体中,找到和干预对象一模一样的用户,这样就可以把因果效应归因到干预上。
先来个案例说明倾向性得分匹配(PSM、Propensity Score Matching)可能解决的问题。
案例 1:
“试想需要比较不同类型学校的学生间收入差距,必然会得出私立大学的学生们收入奇高的结论。但稍加思考,我们就会发现收入上的差距可能是由于进入精英大学的学生本身能力就很强造成的,这并不能揭示哈佛大学学位所带来的收益。那么我们就需要保证学生自身能力、家庭背景等这些因素不变,去比较各方面都十分相似的学生就读于不同大学所带来的收入差距,这才是真正反映出精英私立大学教育回报率。明白了匹配的基本思想之后,接下来的问题就是如何进行匹配。不难发现除了高中成绩、家庭收入、性别等因素之外,还有许许多多因素影响着学生的未来收入,比如个人的勤奋程度、写作能力等等,将那么多广泛的因素进行控制是件十分困难的事情——此类可能性几乎无穷无尽,并且还存在不可观测的因素。
“
案例 2:(该统计也就是辛普森悖论的经典例子)
- 吸烟者:1 人是,0 人否
- 治疗:1 例接受治疗(治疗组),0 例未接受治疗(对照组)
- 结果:1 人死亡,0 人未死亡
如果我们忽略吸烟状况并比较对照组(23.5%)和治疗组(34%)的死亡率,我们会得出以下结论:假设ATE(平均治疗效果)为0.105(0.34 - 0.235),如果进行治疗,死亡率将增加10.5%。
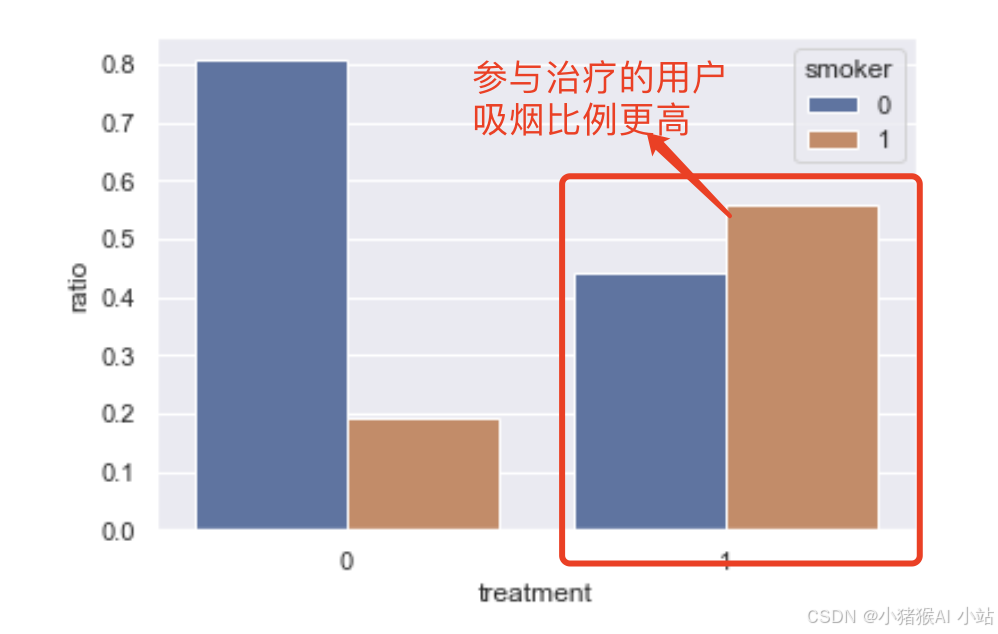
治疗组患者中吸烟者的数量(56%)远远高于对照组(19%)——这是否意味着吸烟会导致更高的死亡率?真实答案其实完全相反。
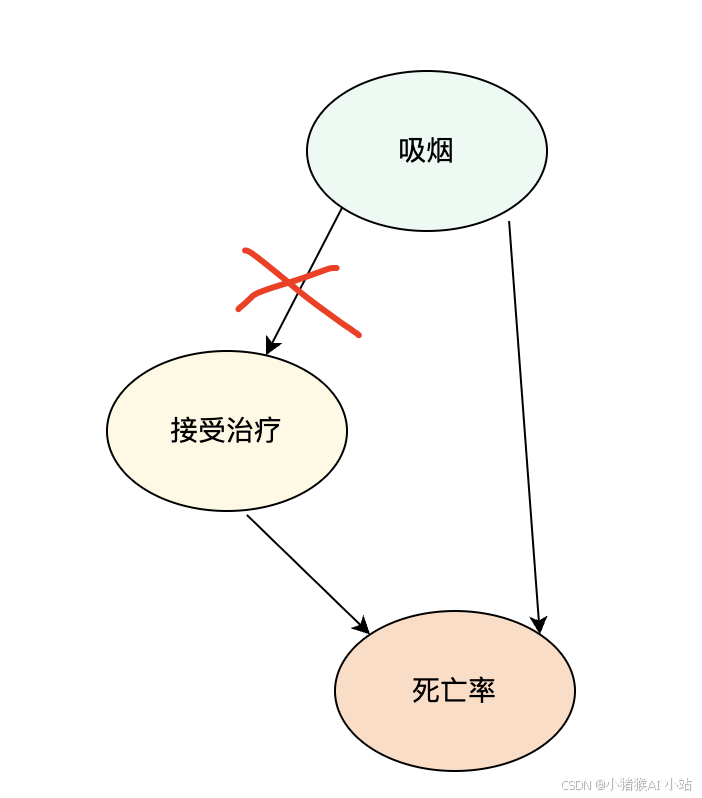
存在本轮的原因在于因果图中存在吸烟影响接受治疗率,同时影响死亡率。存在以下 2 点。
(1)吸烟影响死亡率;
(2)吸烟的人接受治疗率更高,治疗后可能死亡率变低;
本质上控制组用户和实验组用户不同质,导致了相反的结论。这时候 PSM 就派上用场的。
如果可以做 ABTest,那么就没倾向性得分匹配法什么事情,直接 ABTest 是最好的因果推断的选择。但是 ABTest 通常有一些问题:
(1)ABTest不可进行:比如我们不能强迫一组用户‘吸烟’,另一组用户‘不吸烟’去观察吸烟对健康的危害;
(2)ABTest成本太高:当线上实验的选择太多,而产品的流量/时间成本是有限时,逐一对每一个实验都进行测试显然不现实,此时通过离线数据进行因果推断可以帮助我们科学地预判不同实验策略的“前途”,让我们可以优先尝试前途更加光明的实验。
PSM是一种使用倾向性得分进行匹配的因果推断方法,由Paul R. Rosenbaum和Donald Rubin两位统计学家在1983年首次提出,可以降低或消除混淆变量的干扰,从而更准确地测算干预的效果。用倾向性得分匹配可以相同的‘同质’用户,也就是从对照组中寻找特征相似的个体与其实验组相匹配,这个群体是一一对应的,从而构造控制组和实验组,用控制组个体的结果来估计干预组个体的反事实结果,进而分离出处理变量的因果效应(ATE (平均治疗/干预效应)指标)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









