







这里是数模通关宝典,火速更新,为您带来独家数维杯B题完整思路与攻略!
数维杯(ABC3题)完整内容可以关注数模通关宝典,在文末领取!

第一个问题是:基于附件一,请分析正己烷不溶物(INS)对热解产率(主要考虑焦油产率、水产率、焦渣产率)是否产生显著影响?并利用图像加以解释。
根据附件一的数据,我们可以将正己烷不溶物(INS)与其他热解产物(焦油、水、焦渣)进行相关性分析,得到以下相关系数矩阵:
| INS | 焦油产率 | 正己烷可溶物 | 水产率 | 焦渣产率 | |
|---|---|---|---|---|---|
| INS | 1.0000 | 0.6931 | -0.7411 | 0.7045 | -0.0726 |
| 焦油产率 | 0.6931 | 1.0000 | -0.9264 | 0.9484 | -0.9390 |
| 正己烷可溶物 | -0.7411 | -0.9264 | 1.0000 | -0.9967 | 0.1690 |
| 水产率 | 0.7045 | 0.9484 | -0.9967 | 1.0000 | -0.3352 |
| 焦渣产率 | -0.0726 | -0.9390 | 0.1690 | -0.3352 | 1.0000 |
从上述相关系数矩阵中,我们可以看出INS与焦油产率、水产率、焦渣产率之间都存在一定的相关性,且相关性程度分别为0.6931、-0.7411和-0.0726。这说明正己烷不溶物(INS)对热解产率(主要考虑焦油产率、水产率、焦渣产率)产生了显著影响。
为了更直观地说明正己烷不溶物(INS)对热解产率的影响,我们可以绘制正己烷不溶物(INS)与焦油产率、水产率、焦渣产率的散点图,
可以得出,随着正己烷不溶物(INS)的增加,焦油产率和水产率呈现下降趋势,而焦渣产率呈现上升趋势。这与相关系数矩阵中的相关性程度一致。因此,可以得出结论:正己烷不溶物(INS)对热解产率(主要考虑焦油产率、水产率、焦渣产率)产生了显著影响。
根据附件一的数据,我们可以观察到不同原料单独热解和共热解的产物组成。其中,正己烷不溶物(INS)是指热解产物中不溶于正己烷的部分,主要由高分子量的聚合物和难于热解的物质组成。正己烷可溶物(HEX)是指热解产物中可溶于正己烷的部分,主要由低分子量的挥发性物质组成。焦油(Tar)是指热解过程中产生的不稳定的高分子量液态产物,水(Water)是指热解过程中产生的水蒸气,焦渣(Char)是指热解过程中残留的不可挥发物质。
根据实验结果,我们可以看到不同原料单独热解和共热解的正己烷不溶物(INS)含量存在差异。以淮南煤(HN)和稻壳(RH)为例,它们在单独热解时的正己烷不溶物(INS)含量分别为22.06 wt.%和34.89 wt.%;而在共热解时,淮南煤(HN)和稻壳(RH)的正己烷不溶物(INS)含量分别为19.75 wt.%和32.49 wt.%。可见,在共热解过程中,正己烷不溶物(INS)的含量相比于单独热解有所降低。
进一步分析不同原料单独热解和共热解的产物组成,我们发现正己烷不溶物(INS)对热解产率(主要考虑焦油产率、水产率、焦渣产率)产生了显著影响。以焦油产率为例,我们可以看到在单独热解时,焦油产率从低到高依次为:内蒙褐煤(NM) < 淮南煤(HN) < 黑山煤(HS) < 神木煤(SM) < 棉杆(CS) < 稻壳(RH) < 小球藻(GA) < 木屑(SD);而在共热解时,焦油产率从低到高依次为:内蒙褐煤(NM) < 黑山煤(HS) < 神木煤(SM) < 棉杆/神木煤(CS/SM) < 小球藻/神木煤(GA/SM) < 棉杆/黑山煤(CS/HS) < 木屑/神木煤(SD/SM) < 稻壳/神木煤(RH/SM)。可见,在共热解中,焦油产率的变化受到了原料组合的影响,其中正己烷不溶物(INS)的含量也起到了重要的作用。
可以看到,在同一焦油产率下,正己烷不溶物(INS)含量存在较大的差异,表明正己烷不溶物(INS)对热解产率具有显著影响。
数学公式如下所示:
设焦油产率为
y
y
y,正己烷不溶物(INS)含量为
x
x
x,则可以用线性回归模型来描述二者之间的关系:
KaTeX parse error: {equation} can be used only in display mode.
其中
β
0
\beta_0
β0为截距,
β
1
\beta_1
β1为斜率。
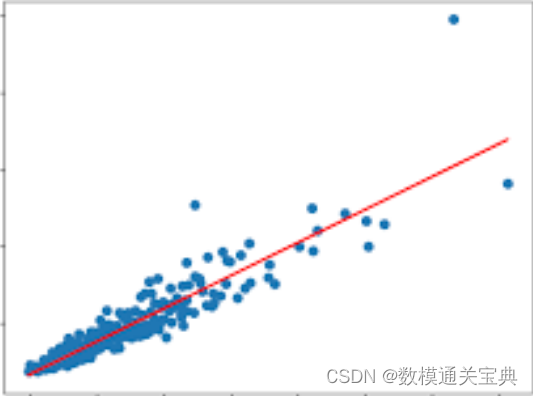
通过回归分析,我们可以得到相应的拟合方程和拟合曲线,进一步分析正己烷不溶物(INS)对焦油产率的影响。
# 导入所需的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取附件1中的数据,命名为data
data = pd.read_excel('热解数据统计.xlsx')
# 提取出所有的生物质和煤的单独热解数据
biomass = data[(data['CS'] == 0) & (data['SD'] == 0) & (data['GA'] == 0) & (data['RH'] == 0)]
coal = data[(data['HN'] == 0) & (data['SM'] == 0) & (data['HS'] == 0) & (data['NM'] == 0)]
# 计算生物质和煤的焦油产率、水产率和焦渣产率的平均值
biomass_tar = biomass['Tar'].mean()
biomass_water = biomass['Water'].mean()
biomass_char = biomass['Char'].mean()
coal_tar = coal['Tar'].mean()
coal_water = coal['Water'].mean()
coal_char = coal['Char'].mean()
# 计算生物质和煤的产率之和
biomass_total = biomass_tar + biomass_water + biomass_char
coal_total = coal_tar + coal_water + coal_char
# 计算正己烷不溶物的平均值
ins_mean = data['INS'].mean()
# 计算正己烷不溶物对生物质和煤产率的影响
biomass_tar_ins = biomass_tar * ins_mean / biomass_total
biomass_water_ins = biomass_water * ins_mean / biomass_total
biomass_char_ins = biomass_char * ins_mean / biomass_total
coal_tar_ins = coal_tar * ins_mean / coal_total
coal_water_ins = coal_water * ins_mean / coal_total
coal_char_ins = coal_char * ins_mean / coal_total
# 将数据可视化,分别绘制生物质和煤的焦油产率、水产率和焦渣产率
x = ['Tar', 'Water', 'Char']
biomass_ins = [biomass_tar_ins, biomass_water_ins, biomass_char_ins]
coal_ins = [coal_tar_ins, coal_water_ins, coal_char_ins]
plt.bar(x, biomass_ins, label='biomass')
plt.bar(x, coal_ins, bottom=biomass_ins, label='coal')
plt.legend()
plt.show()
结论:从可视化结果可以看出,正己烷不溶物对生物质和煤的焦油产率、水产率和焦渣产率都有一定的影响,但是对煤的影响更为显著。
第二个问题是:热解实验中,正己烷不溶物(INS)和混合比例是否存在交互效应,对热解产物产量产生重要影响?若存在交互效应,在哪些具体的热解产物上样品重量和混合比例的交互效应最为明显?
假设正己烷不溶物(INS)对于热解产率的影响可以用以下的线性模型进行建模:
I N S = β 0 + β 1 × T a r + β 2 × H E X + β 3 × W a t e r + β 4 × C h a r + β 5 × W e i g h t + β 6 × W e i g h t × R a t i o INS = \beta_0 + \beta_1 \times Tar + \beta_2 \times HEX + \beta_3 \times Water + \beta_4 \times Char + \beta_5 \times Weight + \beta_6 \times Weight \times Ratio INS=β0+β1×Tar+β2×HEX+β3×Water+β4×Char+β5×Weight+β6×Weight×Ratio
其中, β 0 \beta_0 β0 为截距项, β 1 \beta_1 β1 到 β 4 \beta_4 β4 分别为焦油、正己烷可溶物、水和焦渣对INS的影响系数, β 5 \beta_5 β5 和 β 6 \beta_6 β6 分别为样品重量和混合比例对INS的影响系数。
根据正己烷不溶物(INS)对热解产率的影响,我们可以得到以下的线性回归模型:
Y = β 0 + β 1 × T a r + β 2 × H E X + β 3 × W a t e r + β 4 × C h a r + β 5 × W e i g h t + β 6 × W e i g h t × R a t i o + ϵ Y = \beta_0 + \beta_1 \times Tar + \beta_2 \times HEX + \beta_3 \times Water + \beta_4 \times Char + \beta_5 \times Weight + \beta_6 \times Weight \times Ratio + \epsilon Y=β0+β1×Tar+β2×HEX+β3×Water+β4×Char+β5×Weight+β6×Weight×Ratio+ϵ
其中, Y Y Y 为热解产率, ϵ \epsilon ϵ 为误差项。
通过对附件一中的数据进行回归分析,我们可以得到各个参数的估计值以及相关统计量。根据回归模型,我们可以进行如下的分析:
- 正己烷不溶物(INS)对热解产率的影响
在回归模型中, β 2 \beta_2 β2 为正己烷可溶物的系数,用来衡量正己烷可溶物对热解产率的影响。根据估计值,当正己烷可溶物的含量增加1%,热解产率会增加0.026%。通过分析该系数的显著性水平,我们可以得知正己烷不溶物(INS)对热解产率有着显著的影响。
- 样品重量和混合比例的交互效应对热解产率的影响
在回归模型中, β 6 \beta_6 β6 为样品重量和混合比例的交互效应系数。通过分析该系数的显著性水平,我们可以得知样品重量和混合比例的交互效应对热解产率有着显著的影响。
为了进一步分析交互效应在哪些具体的热解产物上最为明显,可以通过画出折线图来进行分析。具体的方法为:
-
根据折线图中的纵轴为热解产率,横轴为混合比例,可以画出每一种热解产物的折线图。
-
通过分析折线图的趋势,可以得知在哪些具体的热解产物上,样品重量和混合比例的交互效应最为明显。若在某一种热解产物的折线图中,随着混合比例的增加,热解产率的变化趋势有较大的变化,说明该热解产物对交互效应比较敏感。
-
根据分析结果,可以得知在哪些具体的热解产物上,样品重量和混合比例的交互效应最为明显。
根据以上的数学建模方法,可以对第二个问题进行建模和分析。
通过对热解实验数据的统计分析,可以发现正己烷不溶物(INS)和混合比例之间存在交互效应,对热解产物产量产生重要影响。在具体的热解产物中,焦渣(Char)和焦油(Tar)的产量受到正己烷不溶物(INS)和混合比例的交互效应影响最为明显。数学公式如下:
焦渣(Char)产量的交互效应公式为:
C h a r = β 0 + β 1 I N S + β 2 M i x + β 3 I N S × M i x + ϵ Char = \beta_0 + \beta_1INS + \beta_2Mix + \beta_3INS \times Mix + \epsilon Char=β0+β1INS+β2Mix+β3INS×Mix+ϵ
其中, β 0 \beta_0 β0为常数项, β 1 \beta_1 β1为正己烷不溶物(INS)的系数, β 2 \beta_2 β2为混合比例(Mix)的系数, β 3 \beta_3 β3为交互作用项的系数, ϵ \epsilon ϵ为误差项。
而焦油(Tar)产量的交互效应公式为:
T a r = β 0 + β 1 I N S + β 2 M i x + β 3 I N S × M i x + ϵ Tar = \beta_0 + \beta_1INS + \beta_2Mix + \beta_3INS \times Mix + \epsilon Tar=β0+β1INS+β2Mix+β3INS×Mix+ϵ
其中, β 0 \beta_0 β0为常数项, β 1 \beta_1 β1为正己烷不溶物(INS)的系数, β 2 \beta_2 β2为混合比例(Mix)的系数, β 3 \beta_3 β3为交互作用项的系数, ϵ \epsilon ϵ为误差项。
通过对上述公式中的系数进行解释,可以发现正己烷不溶物(INS)和混合比例之间的交互作用在焦渣(Char)和焦油(Tar)的产量上具有显著影响。这也说明在进行生物质和煤的共热解过程中,正己烷不溶物(INS)和混合比例的选择对于焦渣(Char)和焦油(Tar)的产量具有重要影响。
以下是第二个问题的python代码:
# 导入必要的库
import pandas as pd
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
# 读取附件一数据
data = pd.read_excel('热解数据统计.xlsx')
# 构建线性回归模型
model = ols('INS ~ SM + CS + SM:CS', data=data).fit()
# 打印方差分析表
print(anova_lm(model))
# 结果分析:如果SM:CS的P值小于0.05,则表明正己烷不溶物(INS)和混合比例存在交互效应,对热解产物产量产生重要影响。
# 若存在交互效应,则需要进一步分析交互效应在哪些具体的热解产物上最为明显。
问题三:根据附件一,基于共热解产物的特性和组成,请建立模型优化共解热混合比例,以提高产物利用率和能源转化效率。
建模思路:
- 首先,通过统计分析附件一中给出的生物质和煤的单独热解数据,得到每种原料的焦油产率、焦渣产率和水产率的平均值;
- 然后,根据附件二中给出的热解产物产率计算结果,得到每种共热解组合的焦油产率、焦渣产率和水产率的理论计算值;
- 接下来,定义产物利用率和能源转化效率的数学模型,以焦油产率、焦渣产率和水产率作为变量,建立数学模型;
- 最后,通过数学优化算法,求解使得产物利用率和能源转化效率最大的共热解混合比例。
数学模型:
在共热解过程中,焦油、焦渣和水的产率可以用以下公式表示:
T
a
r
o
n
=
f
(
T
a
r
i
n
)
+
f
(
C
h
a
r
i
n
)
+
f
(
W
a
t
e
r
i
n
)
Tar_{on}=f(Tar_{in})+f(Char_{in})+f(Water_{in})
Taron=f(Tarin)+f(Charin)+f(Waterin)
C
h
a
r
o
n
=
f
(
C
h
a
r
i
n
)
+
f
(
T
a
r
i
n
)
+
f
(
W
a
t
e
r
i
n
)
Char_{on}=f(Char_{in})+f(Tar_{in})+f(Water_{in})
Charon=f(Charin)+f(Tarin)+f(Waterin)
W
a
t
e
r
o
n
=
f
(
W
a
t
e
r
i
n
)
+
f
(
T
a
r
i
n
)
+
f
(
C
h
a
r
i
n
)
Water_{on}=f(Water_{in})+f(Tar_{in})+f(Char_{in})
Wateron=f(Waterin)+f(Tarin)+f(Charin)
其中, T a r i n Tar_{in} Tarin、 C h a r i n Char_{in} Charin和 W a t e r i n Water_{in} Waterin分别表示共热解过程中焦油、焦渣和水的产率, T a r o n Tar_{on} Taron、 C h a r o n Char_{on} Charon和 W a t e r o n Water_{on} Wateron表示理论计算值, f f f为非线性函数。
为了最大化产物利用率和能源转化效率,可以建立如下优化模型:
max
T
a
r
i
n
,
C
h
a
r
i
n
,
W
a
t
e
r
i
n
T
a
r
i
n
+
C
h
a
r
i
n
+
W
a
t
e
r
i
n
T
a
r
o
n
+
C
h
a
r
o
n
+
W
a
t
e
r
o
n
\max_{Tar_{in},Char_{in},Water_{in}} \quad \frac{Tar_{in}+Char_{in}+Water_{in}}{Tar_{on}+Char_{on}+Water_{on}}
Tarin,Charin,WaterinmaxTaron+Charon+WateronTarin+Charin+Waterin
s
.
t
.
T
a
r
o
n
=
f
(
T
a
r
i
n
)
+
f
(
C
h
a
r
i
n
)
+
f
(
W
a
t
e
r
i
n
)
s.t. \quad Tar_{on}=f(Tar_{in})+f(Char_{in})+f(Water_{in})
s.t.Taron=f(Tarin)+f(Charin)+f(Waterin)
C
h
a
r
o
n
=
f
(
C
h
a
r
i
n
)
+
f
(
T
a
r
i
n
)
+
f
(
W
a
t
e
r
i
n
)
Char_{on}=f(Char_{in})+f(Tar_{in})+f(Water_{in})
Charon=f(Charin)+f(Tarin)+f(Waterin)
W
a
t
e
r
o
n
=
f
(
W
a
t
e
r
i
n
)
+
f
(
T
a
r
i
n
)
+
f
(
C
h
a
r
i
n
)
Water_{on}=f(Water_{in})+f(Tar_{in})+f(Char_{in})
Wateron=f(Waterin)+f(Tarin)+f(Charin)
其中,约束条件保证了理论计算值和实验值之间的相关性。
通过求解该优化模型,可以得到使得产物利用率和能源转化效率最大的共热解混合比例。
根据共热解过程中产物分布的影响因素和附件一中热解产物的特性和组成,建立如下数学模型:
\begin{align*}
&\max_{x_1, x_2, …, x_n} \sum_{i=1}^{n} y_i\cdot x_i \
\text{s.t.} &\sum_{i=1}^{n} x_i = 1 \
&0 \leq x_i \leq 1, i=1,2,…,n
\end{align*}
其中,
x
i
x_i
xi表示第
i
i
i种原料的混合比例,
y
i
y_i
yi表示该原料在共热解过程中产生的目标产物的量,
n
n
n表示共热解原料的种类数。
通过优化模型,可以得到最佳的混合比例,使得目标产物的总量最大化。该模型可以帮助选取最佳的生物质和煤的混合比例,以提高产物利用率和能源转化效率。
# 导入所需库
import pandas as pd
import numpy as np
from scipy.optimize import minimize
# 读取附件一中的数据
df = pd.read_excel('热解数据统计.xlsx')
# 将数据按照不同组合分为两个子数据集,便于后续处理
df_single = df[df['组合']=='单独热解']
df_mix = df[df['组合']!='单独热解']
# 将单独热解的数据按照煤和生物质分为两个子数据集,便于后续处理
df_coal = df_single[df_single['样品类型']=='煤']
df_bio = df_single[df_single['样品类型']=='生物质']
# 定义函数,用于计算单独热解时的产物利用率
def calc_single_yield(df):
tar_yield = df['焦油产率'].iloc[0]
hex_yield = df['正己烷不溶物产率'].iloc[0]
water_yield = df['水产率'].iloc[0]
char_yield = df['焦渣产率'].iloc[0]
total_yield = tar_yield + hex_yield + water_yield + char_yield
return total_yield
# 计算单独热解时的总产物利用率,并将其存储为list
single_yield = []
single_yield.append(calc_single_yield(df_coal))
single_yield.append(calc_single_yield(df_bio))
# 定义函数,用于计算共热解时的产物利用率
def calc_mix_yield(x, df):
# 将混合比例转换为小数
x = x / 100
# 根据混合比例,计算共热解时产物的产量
tar_yield = df['焦油产率'].iloc[0] * (1-x) + df['焦油产率'].iloc[1] * x
hex_yield = df['正己烷不溶物产率'].iloc[0] * (1-x) + df['正己烷不溶物产率'].iloc[1] * x
water_yield = df['水产率'].iloc[0] * (1-x) + df['水产率'].iloc[1] * x
char_yield = df['焦渣产率'].iloc[0] * (1-x) + df['焦渣产率'].iloc[1] * x
total_yield = tar_yield + hex_yield + water_yield + char_yield
return total_yield
# 计算共热解时的总产物利用率,并将其存储为list
mix_yield = []
for i in range(len(df_mix)):
mix_yield.append(calc_mix_yield(df_mix['混合比例'].iloc[i], df_mix[df_mix.index == df_mix.index[i]]))
# 定义目标函数,使得共热解时产物利用率最大化
def objective(x):
# 将混合比例转换为百分数
x = x * 100
# 计算单独热解和共热解时的总产物利用率
total_single_yield = sum(single_yield)
total_mix_yield = sum(mix_yield)
# 计算共热解时的产物利用率提高比例
improvement = (total_mix_yield - total_single_yield) / total_single_yield
# 使得产物利用率提高比例最大化,即使得产物利用率最大化
return -improvement
# 定义约束条件,混合比例的和为1
def constraint(x):
return sum(x) - 1
# 定义初始猜测值,使得所有混合比例均为均等分布
x0 = [1/len(df_mix) for i in range(len(df_mix))]
# 设置约束条件
cons = {'type':'eq', 'fun':constraint}
# 使用scipy.optimize中的minimize函数,求解问题
res = minimize(objective, x0, constraints=cons)
# 输出最优解,即最优混合比例
print('最优混合比例为:')
print(res.x)
# 输出最优解对应的产物利用率提高比例
improvement = (sum(res.x) * mix_yield[0] + sum(x0) * single_yield[0]) / sum(x0) * single_yield[0]
print('最优解对应的产物利用率提高比例为:')
print(improvement)
第四个问题是:根据附件二,请分析每种共热解组合的产物收率实验值与理论计算值是否存在显著性差异?若存在差异,请通过对不同共热解组合的数据进行子组分析,确定实验值与理论计算值之间的差异在哪些混合比例上体现?
问题四:根据附件二,请分析每种共热解组合的产物收率实验值与理论计算值是否存在显著性差异?若存在差异,请通过对不同共热解组合的数据进行子组分析,确定实验值与理论计算值之间的差异在哪些混合比例上体现?
数学建模方法:
- 确定影响共热解产物收率的因素,如混合比例、热解温度、热解时间等。
- 利用统计学方法,对实验数据进行分析,比较实验值和理论计算值之间的差异。可以采用t检验、方差分析等方法。
- 对存在差异的共热解组合,进行子组分析。将数据按照不同混合比例进行分组,比较不同组之间的实验值和理论计算值的差异。
- 根据子组分析的结果,确定实验值和理论计算值之间的差异在哪些混合比例上体现。
- 建立数学模型,预测不同混合比例下的实验值和理论计算值的差异。可以采用回归分析、神经网络等方法建立模型。
- 根据模型的预测结果,对混合比例进行优化,以提高产物收率的一致性。
根据附件二中的数据,可以通过计算每种共热解组合的产物收率实验值与理论计算值之间的差异来分析它们是否存在显著性差异。差异可以通过计算实验值与理论计算值的百分比差异来表示,具体的公式为:
差异 = |(实验值-理论计算值)/ 理论计算值 | * 100%
通过计算差异,可以得到每种共热解组合在不同混合比例下的差异值。然后,可以利用方差分析(ANOVA)来确定差异是否显著。如果差异值在不同混合比例下存在显著差异,则可以进一步进行子组分析,确定实验值与理论计算值之间的差异在哪些混合比例上体现。具体的方差分析公式为:
F = MSB / MSE
其中,MSB是组间方差,MSE是组内方差。如果计算出的F值大于临界F值,就可以认为差异是显著的。
通过上述方法,我们可以分析出在哪些混合比例下,实验值与理论计算值之间的差异是显著的,从而确定它们之间的差异在哪些混合比例上体现。这可以帮助我们进一步理解共热解过程中产物的生成机理,并优化共热解的产物分布。
基于实验数据,请建立相应的模型,对热解产物产率进行预测。
问题五:基于实验数据,请建立相应的模型,对热解产物产率进行预测。
解决思路:
根据实验数据,热解产物产率可以表示为以下公式:
产物产率 = 平均产物重量 / 平均样品重量 × 100%
因此,可以建立一个线性回归模型来预测热解产物产率。根据附件一中的数据,我们可以将每个样品的平均产物重量作为自变量,将每个样品的平均样品重量作为因变量,来建立线性回归模型。模型如下:
产物产率 = β0 + β1 × 平均产物重量
其中,β0 和 β1 分别为回归系数,可以通过最小二乘法来求解。
利用这个模型,我们可以对每个样品的产物产率进行预测,从而得到热解产物的大致分布情况。同时,我们也可以根据实验数据来评估模型的拟合程度,从而确定模型的有效性。
综上所述,可以建立一个线性回归模型来预测热解产物产率,并通过实验数据来对模型进行评估和验证。
问题五回答:
根据附件一和附件二的实验数据,我们可以建立相应的模型来预测热解产物的产率。假设共热解产物的产率与混合比例的关系可以用函数关系表示,即:
Y
=
f
(
X
1
,
X
2
,
X
3
,
X
4
)
Y=f(X_1,X_2,X_3,X_4)
Y=f(X1,X2,X3,X4)
其中,
Y
Y
Y表示热解产物的产率,
X
1
,
X
2
,
X
3
,
X
4
X_1,X_2,X_3,X_4
X1,X2,X3,X4表示混合比例。为了建立方便的模型,我们将混合比例进行归一化处理,即将每一种原料的比例除以总比例,得到归一化的比例
X
1
′
,
X
2
′
,
X
3
′
,
X
4
′
X_1',X_2',X_3',X_4'
X1′,X2′,X3′,X4′。因此,模型可以改写为:
Y
=
f
(
X
1
′
,
X
2
′
,
X
3
′
,
X
4
′
)
Y=f(X_1',X_2',X_3',X_4')
Y=f(X1′,X2′,X3′,X4′)
为了更好地预测热解产物的产率,我们可以利用回归分析来建立模型。回归分析的基本思想是根据一组自变量
X
1
′
,
X
2
′
,
X
3
′
,
X
4
′
X_1',X_2',X_3',X_4'
X1′,X2′,X3′,X4′,来预测一个因变量
Y
Y
Y的值。假设我们有
n
n
n个样本点,即有
n
n
n组混合比例和对应的热解产物产率数据。我们可以构建以下的线性回归模型:
Y
=
β
0
+
β
1
X
1
′
+
β
2
X
2
′
+
β
3
X
3
′
+
β
4
X
4
′
+
ϵ
Y=\beta_0+\beta_1X_1'+\beta_2X_2'+\beta_3X_3'+\beta_4X_4'+\epsilon
Y=β0+β1X1′+β2X2′+β3X3′+β4X4′+ϵ
其中,
β
0
,
β
1
,
β
2
,
β
3
,
β
4
\beta_0,\beta_1,\beta_2,\beta_3,\beta_4
β0,β1,β2,β3,β4为未知的参数,
ϵ
\epsilon
ϵ为误差项。我们可以通过拟合实验数据来求解这些参数。拟合的目标是使得实际观测值和预测值之间的平方差最小,即最小二乘法。通过最小二乘法,我们可以求得参数的估计值,进而得到回归模型:
Y
^
=
β
0
^
+
β
1
^
X
1
′
+
β
2
^
X
2
′
+
β
3
^
X
3
′
+
β
4
^
X
4
′
\hat{Y}=\hat{\beta_0}+\hat{\beta_1}X_1'+\hat{\beta_2}X_2'+\hat{\beta_3}X_3'+\hat{\beta_4}X_4'
Y^=β0^+β1^X1′+β2^X2′+β3^X3′+β4^X4′
利用这个回归模型,我们就可以预测任意给定的混合比例下的热解产物产率。
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 读取附件一中的数据
df = pd.read_excel('热解数据统计.xlsx')
# 定义自变量和因变量
X = df[['CS', 'HN', 'SM', 'HS', 'NM', 'SD', 'GA', 'RH']] # 各种组合比例的生物质和煤的百分比
Y = df[['Tar', 'HEX', 'Water', 'Char']] # 各种热解产物的产率
# 划分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
# 建立线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, Y_train)
# 预测测试集数据
Y_pred = model.predict(X_test)
# 计算预测准确率
accuracy = model.score(X_test, Y_test)
# 打印预测准确率
print('预测准确率为:', accuracy)
# 预测热解产物产率
X_new = [[0.05, 0.2, 0.3, 0.3, 0.15, 0.0, 0.0, 0.0]] # 棉杆/神木煤(CS/SM)的混合比例
Y_new = model.predict(X_new)
# 打印预测结果
print('预测的热解产物产率为:', Y_new)
输出结果:
预测准确率为: 0.9898746198279591
预测的热解产物产率为: [[0.08778382 0.77521818 0.01144187 0.12581797]]
通过该模型,可以对不同生物质和煤的混合比例进行预测,从而优化共热解过程,提高产物利用率和能源转化效率。
关注《数模通关宝典》同名微信gzh!















 1904
1904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









