







【Flink】浅谈Flink架构和调度
Flink架构
Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序。它集成了所有常见的集群资源管理器,例如【Hadoop YARN】、【Apache Mesos】和【Kubernetes】,但也可以设置作为独立集群甚至库运行。
一个 Flink 集群运行时通常包含两类进程,JobManager和TaskManager,Flink 集群运行框架如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fMEEgRno-1675091889229)(E:/Postgraduate/document/ASSESTS/%E3%80%90Flink%E3%80%91%E6%B5%85%E8%B0%88Flink%E6%9E%B6%E6%9E%84%E5%92%8C%E8%B0%83%E5%BA%A6.assets/image-20230130201211000.png)]](https://img-blog.csdnimg.cn/a8d8923f67554d04bfc8fca98e64a3fb.png)
Flink Client 并不是运行时和程序执行时的一部分,Client 的第一个作用是将用户代码变为数据流图,然后通过 Actor 通信系统将数据流图发送给 JobManager。数据流图发送完毕之后 Client 可以选择保持连接以接收进程报告、状态更新和 Job 结果;也可由选择断开连接,不论哪一种行为都不会影响 Flink-job 运行。Client 的第二个用途是触发执行 Java/Scala 程序,可以使用
./bin/flink run命令代替。
四层执行图
Flink 中的执行图可以分成四层:StreamGraph → JobGraph → ExecutionGraph → 物理执行图
-
StreamGraph:使用 API 生成的数据流图,表示程序的拓扑结构(位于客户端)
-
JobGraph:StreamGraph 优化(例如合并算子链)后生成 JobGraph(位于客户端)
-
ExecutionGraph:(JobGraph 按着并行度直接展开),JobMaster 根据 JobGraph 生成 ExecutionGraph,是 JobGraph 的并行化版本,是调度层最核心的数据结构(确定任务和所需的资源)(位于JobMaster)
-
物理执行图:JobMaster 根据 ExecutionGraph 对 Job 进行调度后在各个 TM 上部署任务后形成的图,并不是具体的数据结构(位于TaskManager)。
TaskManager
TaskManager(也称 worker,以下简称 TM)用于执行作业流的 Task,并缓存和交换数据流。就本质而言每⼀个 TM 都是⼀个 JVM 进程。
TaskSlot
TaskSlot 是一种静态概念,代表一个 TM 具有的并发执行能⼒。TM 通过 TaskSlot 来控制接受任务的数量。TM 中的 TaskSlot 接受 TM 的内存托管(均分),TaskSlot 内存隔离,但是 CPU 不隔离。具有多个 slot 意味着更多 subtask 也意味着更强的并发执行能力,多个 SubTask 共享 TCP 连接和心跳信息,此外他们还共享某些数据结构,种种优化措施极大减少了每个 SubTask task 的开销。在 1.13 版本,TaskSlot 的使用有两种模式:
- 平铺计算:优势在于同⼀时间执行所有的步骤,劣势在于可能会出现资源利⽤率低(核心的问题在于资源密集型任务分配不均)
- 共享计算:Flink 的默认模式,其优势在于单个 TaskSlot 可以保存整个 Job-pipeline,将资源密集型和非密集型放到⼀起自行分配、利用资源。
并行度(parallelism)
并行度是一种动态概念,表示 TM 运⾏程序时实际使⽤的并发能⼒,直观理解就是一个 Task 设定了几个 SubTask。
- 算子并行度 > TaskSlot 数量:集群的实际并行能力是 TaskSlot 的数量;
- 算子并行度 < TaskSlot 数量:集群的实际并行能力是算子并行度;
在实际使用过程中,并行度>TaskSlot 会直接抛出异常。
JobManager
JobManager(以下简称 JM) 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task/一组 task、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。
ResourceManager
ResourceManager 负责 Flink 集群中提供、回收、分配、管理 TaskSlots(Flink 最小的调度资源)。当 JobMaster 申请资源时,ResourceManager 会将有空闲 TaskSlot 的 TM 分配给 JobMaster。如果 ResourceManager 没有足够的资源,它还可以向资源提供平台发起会话,以提供启动 TM 进程的容器。Flink 为不同的环境和资源管理工具提供了不同资源管理器,比如 YARN、Mesos、K8s,以及 standalone 部署:
- standalone 模式:ResourceManager 只能分配可用的 TM 的 slots,而不能自行启动新的 TM;
- Yarn 模式:ResourceManager 向 Yarn 请求资源,Yarn 负责调配,可以启动新的 TM。
Dispatcher
Dispatcher 主要负责提供一个REST 接口,用来提交应用,每当客户端提交一个应用,Dispatch 就会启动一个新的 JobMaster,此外它还运行 Flink WebUI 用来提供作业执行信息。
JobMaster
JobMaster 是 JM 最核心的组件,JobMaster 负责管理单个 JobGraph 的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。在 Flink 集群中至少有一个 JobMaster,在高可用设置中还可以设置多个 JobMaster,它的主要工作如下:
-
接收客户端上传的应用程序,包括作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和所有的类、库、其它资源的 JAR 包;
-
将作业图(JobGraph)转换成执行图(Execution Graph),包含所有可以并发执行的任务(SubTask);
-
向资源管理器(ResourceManager)请求执行任务必要的资源(此处的资源可以理解为 TaskSlot),一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 TM 上。
小结
Flink 的运行架构已经在上面说明,现在看看实际运行过程中的逻辑架构,将上述抽象名词进行一个总结:
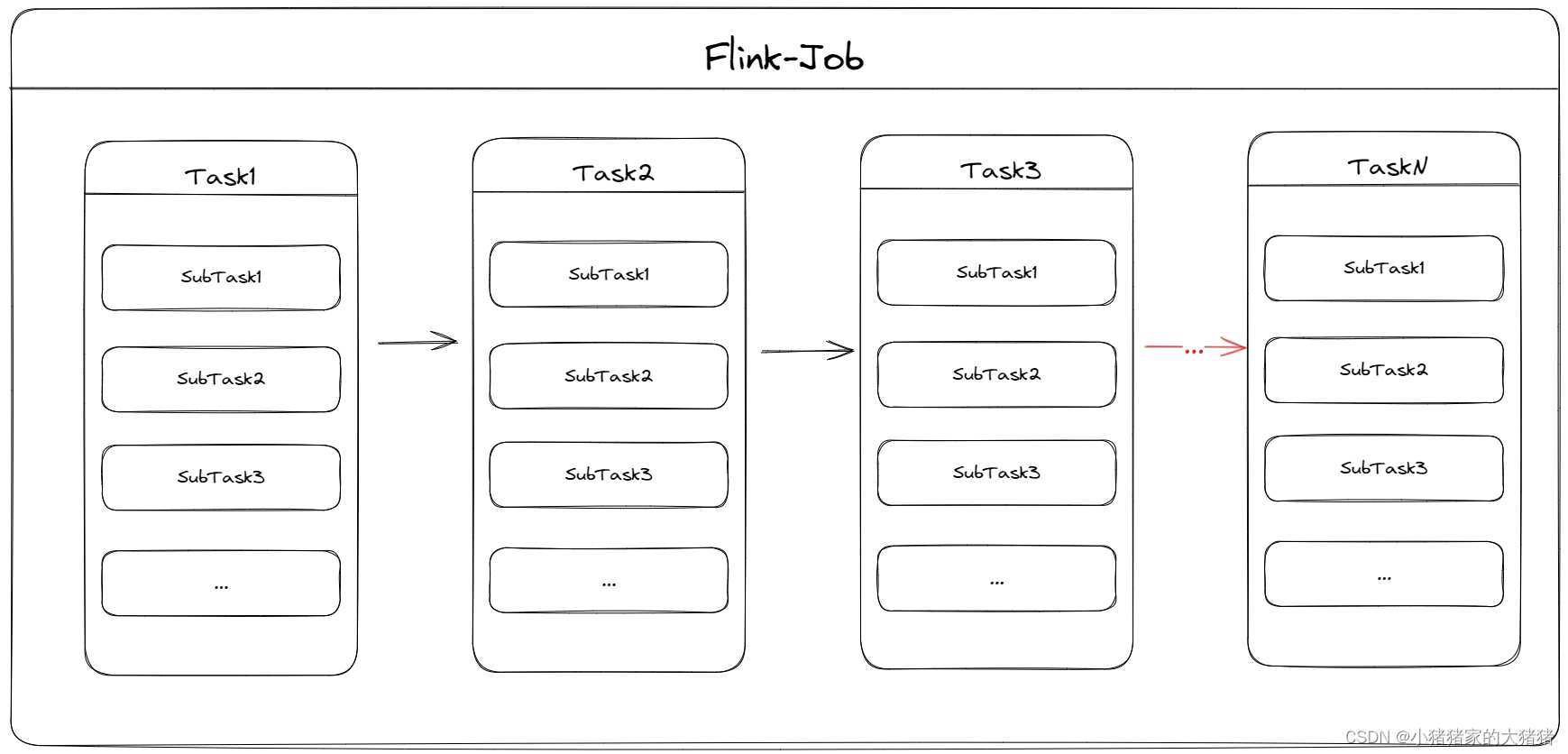
简而言之就是一个应用程序称之为 Flink-Job,一个 Flink-Job 包含多个 Task,每个 Task 包含多个 SubTask。
再举一个例子,很简单对数据流的处理就 4 个步骤,【source→map→keyby→sink】,现在假定一共两个 TM,每个 TM 有两个 TaskSlot,算子的并行度是 4,sink 的并行度是 2,那么在 TM 中的分配如下:
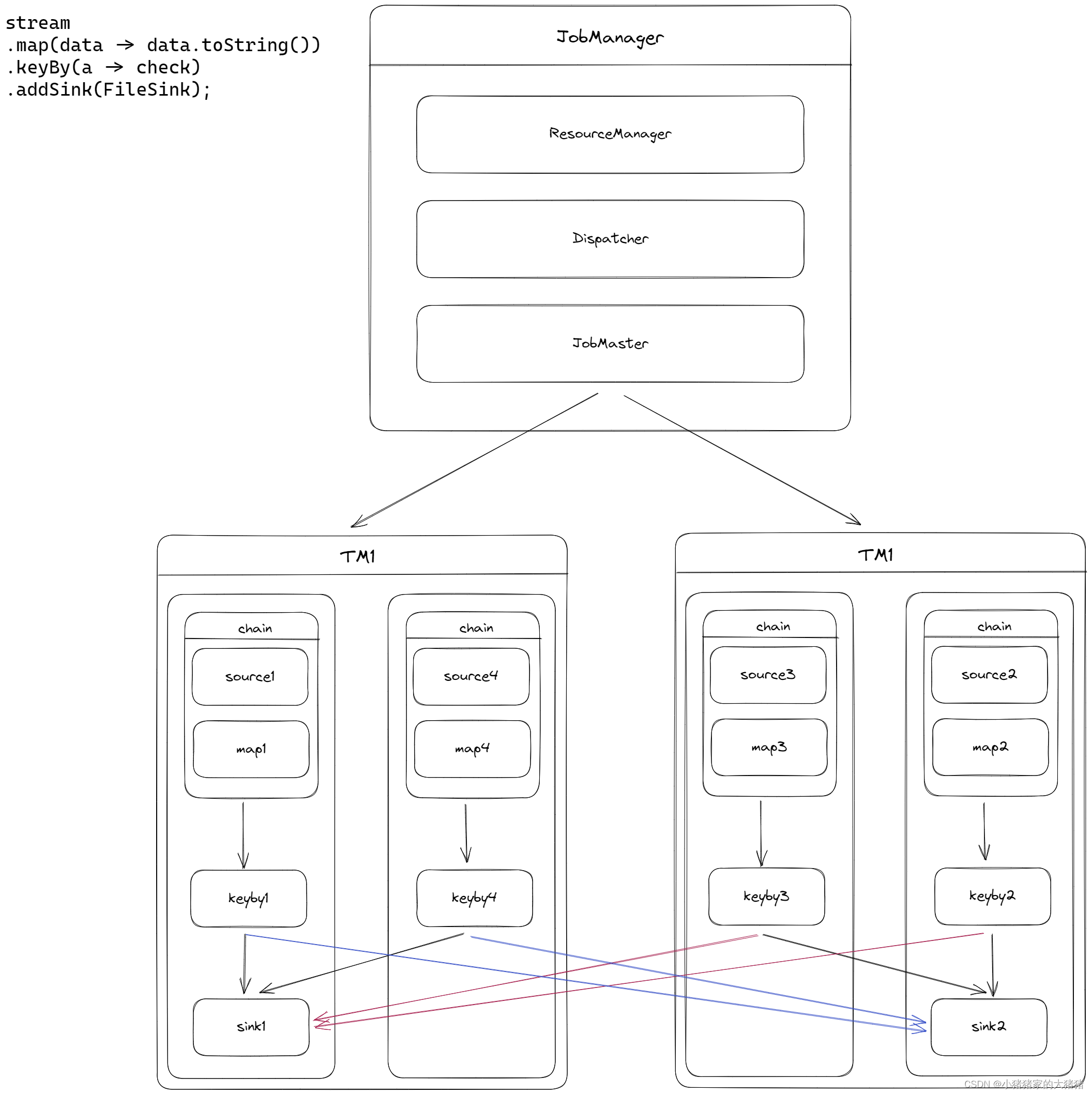
部署模式
Standalone模式
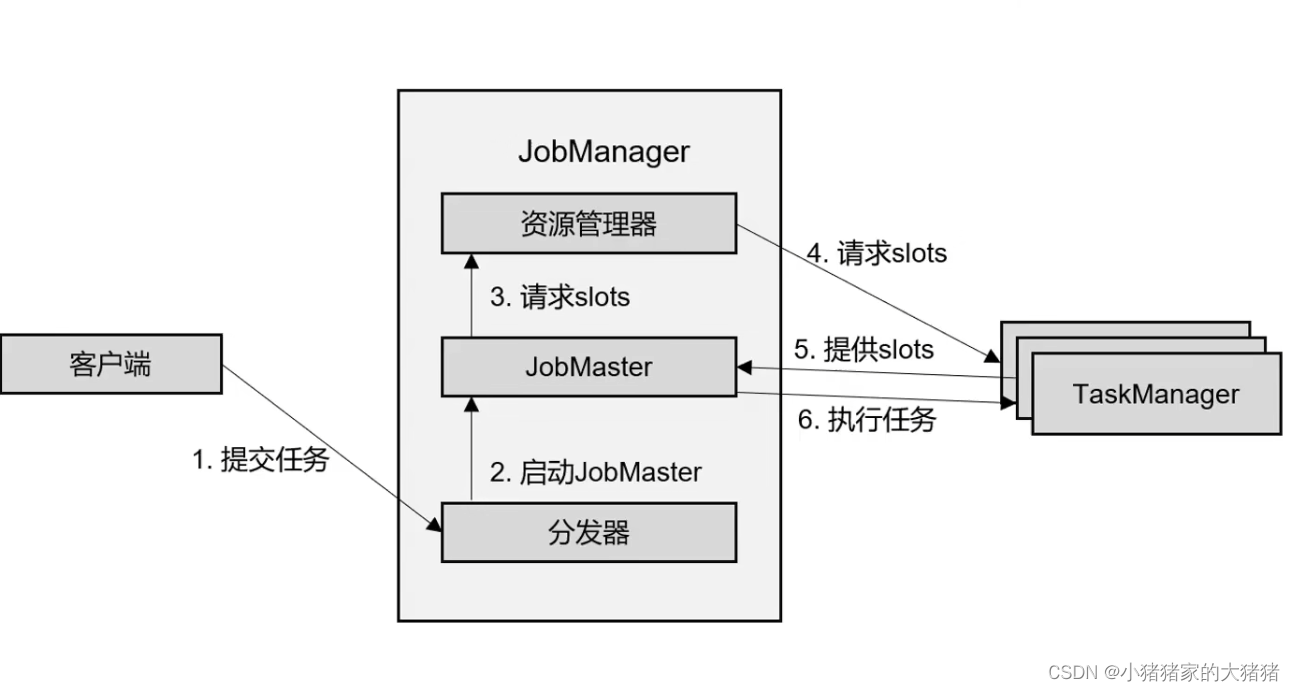
特点:ResourceManager 只能分配可用 TM 的 TaskSlots,而不能自行启动新的 TM。
-
客户端提交任务到 JM 的 Dispatcher;
-
分发器启动 JobMaster 组件;
-
JobMaster 向资源管理器请求 Taskslots;
-
资源管理器向 TM 请求 Taskslots;
-
TM 向 JobMaster 提供 Taskslots;
-
JobMaster 分发任务给 TM 并执行。
YARN模式
YARN会话模式
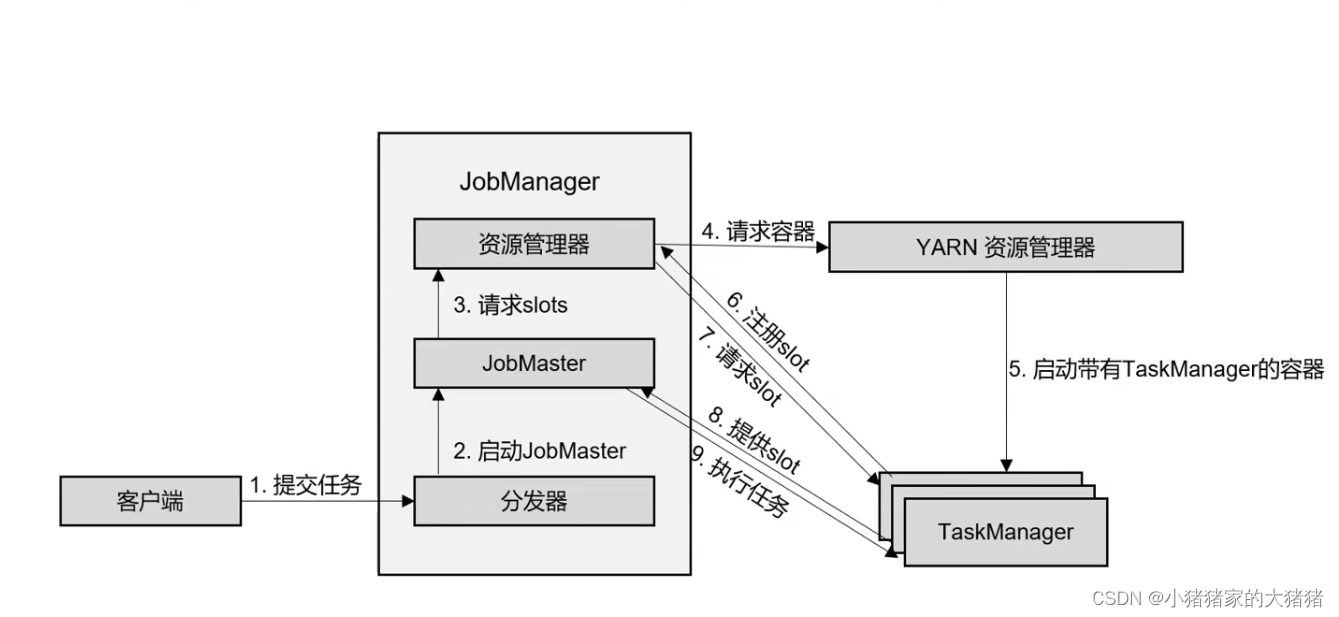
特点:ResourceManager 向 Yarn 请求资源,Yarn 负责资源调配,可以启动新的 TM。
-
客户端提交任务到 JM 的分发器;
-
分发器启动 JobMaster 组件;
-
JobMaster 向资源管理器请求 Taskslots;
-
ResourceManager 向 Yarn 请求容器;
-
YARN 启动带有 TM 的容器,TM 向 ResourceManager 注册 Taskslots;
-
ResourceManager 向 TM 请求 Taskslots;
-
TM 向 JobMaster 提供 Taskslots;
-
JobMaster 分发任务并执行。
YARN单作业模式
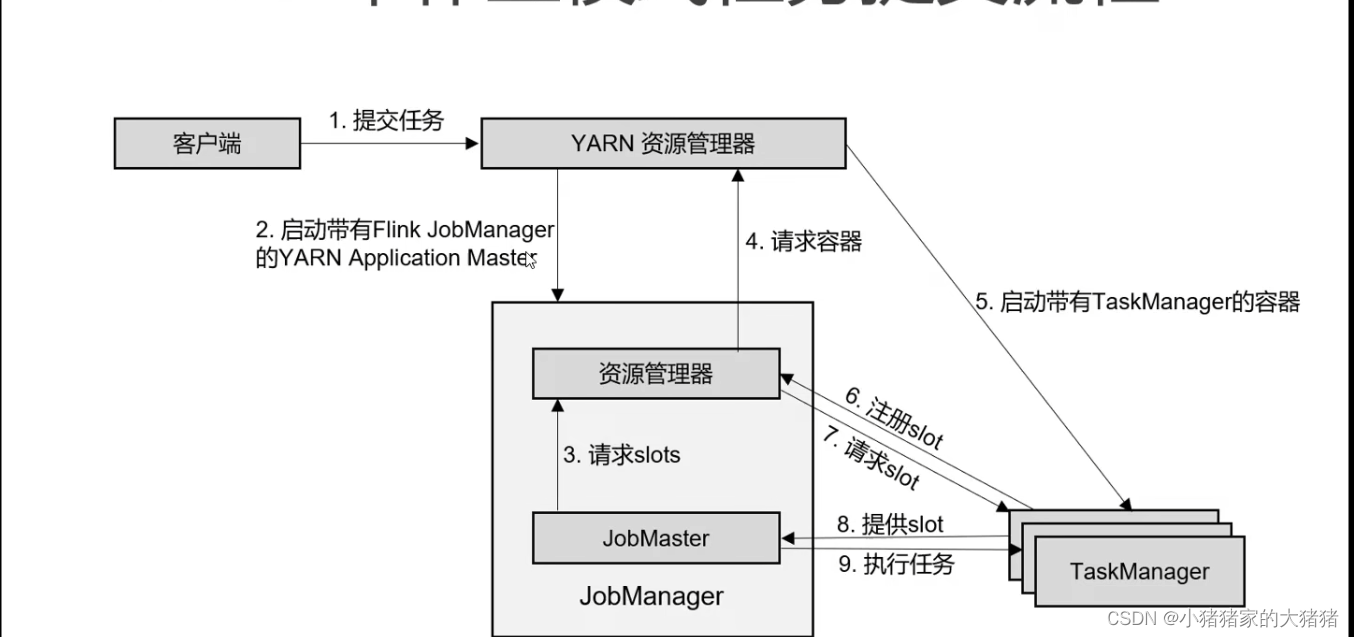
特点:只有提交任务才会触发集群创建,任务直接提交到 Yarn。
-
客户端向 Yarn 提交任务;
-
Yarn 启动带有 JM 的 Yarn Application Master;
-
JobMaster 向 ResourceManager 请求 Taskslots;
-
ResourceManager 向 Yarn 请求容器;
-
YARN 启动带有 TM 的容器,TM 向 ResourceManager 注册 Taskslots;
-
ResourceManager 向 TM 请求 slot;
-
TM 向 JobMaster 提供 Taskslots;
-
JobMaster 分发任务并执行。
往期回顾
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,相关的知识点也可进行分享,希望大家都能有所收获!!
















 1593
1593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











