






上篇笔记记录到RNN的一个缺点:训练时会出现梯度消失,解决的办法是找到一个更优的计算单元。这里也有GRU和LSTM。
GRU(Gated Recurrent Unit)门控训练网络
什么是门控机制?就是对当前的输入进行一个筛选。门打开,信息进来,继续往下传,如果门关闭,信息就停留再此,不可以往下传。它决定了会有哪些信息往下传。

GRU有两个门,一个是更新门,一个是重置门,他的作用就是hi 或者hi-1和当前信息的比重问题,
从直观上来说,重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。使用门控机制学习长期依赖关系的基本思想和 LSTM 一致,但还是有一些关键区别:
- GRU 有两个门(重置门与更新门),而 LSTM 有三个门(输入门、遗忘门和输出门)。
- GRU 并不会控制并保留内部记忆(c_t),且没有 LSTM 中的输出门。
- LSTM 中的输入与遗忘门对应于 GRU 的更新门,重置门直接作用于前面的隐藏状态。
- 在计算输出时并不应用二阶非线性。

GRU 是标准循环神经网络的改进版,但到底是什么令它如此高效与特殊?
为了解决标准 RNN 的梯度消失问题,GRU 使用了更新门(update gate)与重置门(reset gate)。基本上,这两个门控向量决定了哪些信息最终能作为门控循环单元的输出。这两个门控机制的特殊之处在于,它们能够保存长期序列中的信息,且不会随时间而清除或因为与预测不相关而移除。
更新门帮助模型决定到底要将多少过去的信息传递到未来,或到底前一时间步和当前时间步的信息有多少是需要继续传递的。
重置门主要决定了到底有多少过去的信息需要遗忘。
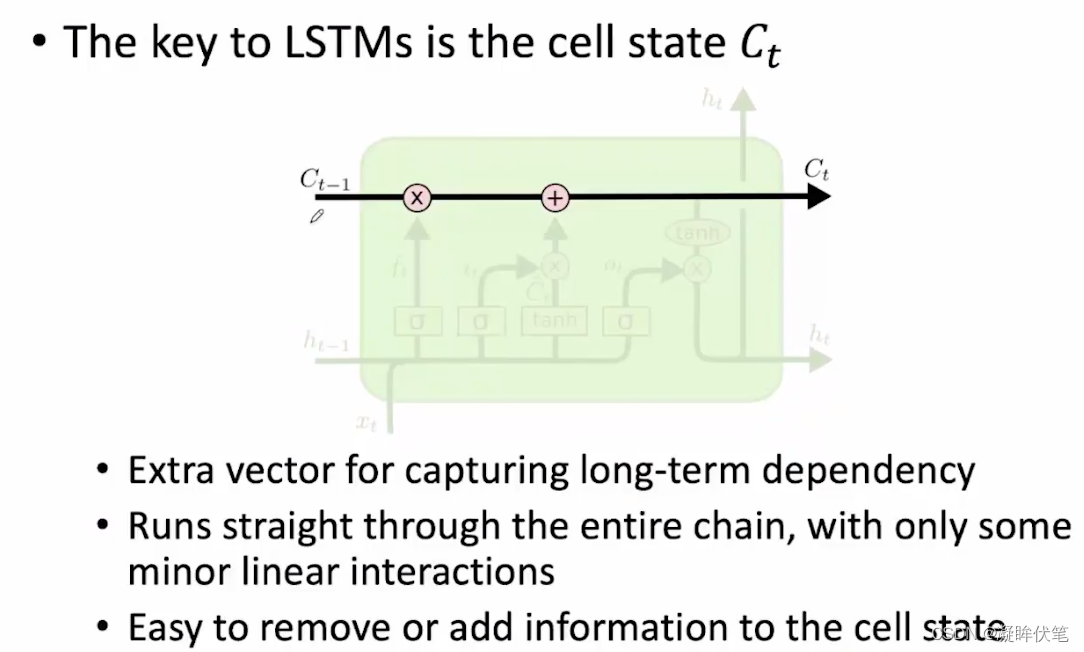
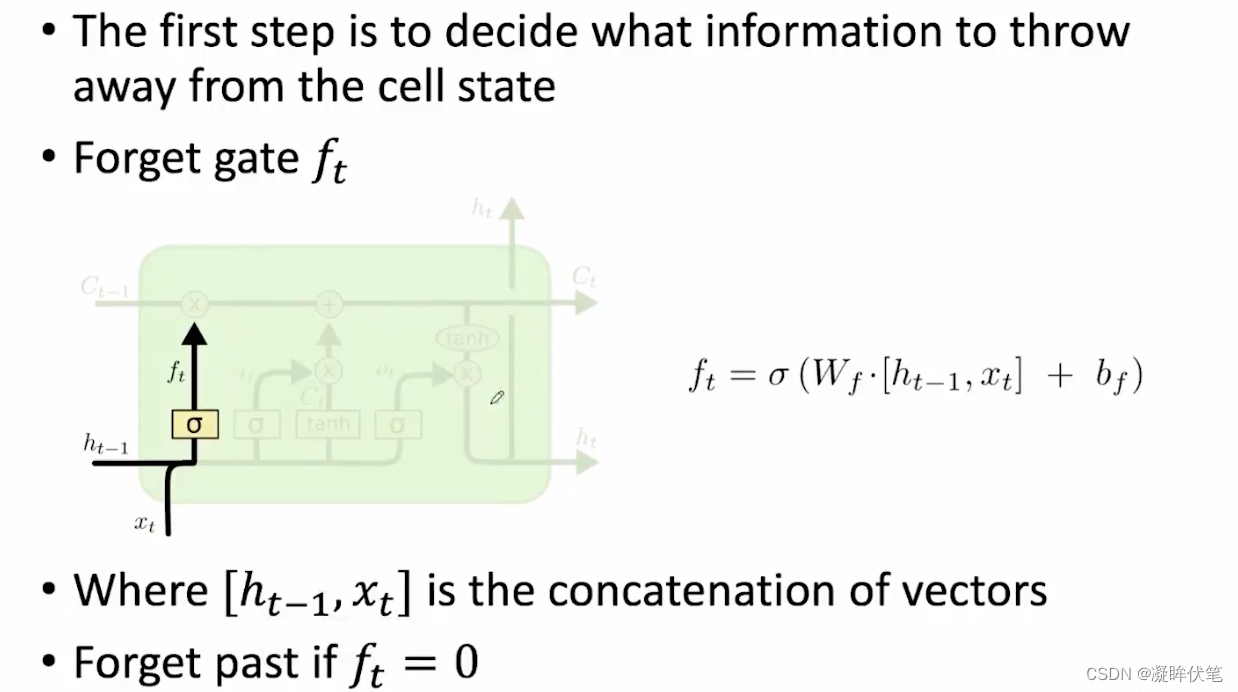
LSTM
长短期记忆网络(long short-term memory network)。LSTM 会以一种非常精确的方式来传递记忆——使用了一种特定的学习机制:哪些部分的信息需要被记住,哪些部分的信息需要被更新,哪些部分的信息需要被注意。与之相反,循环神经网络会以一种不可控制的方式在每一个时间步骤都重写记忆。这有助于在更长的时间内追踪信息。



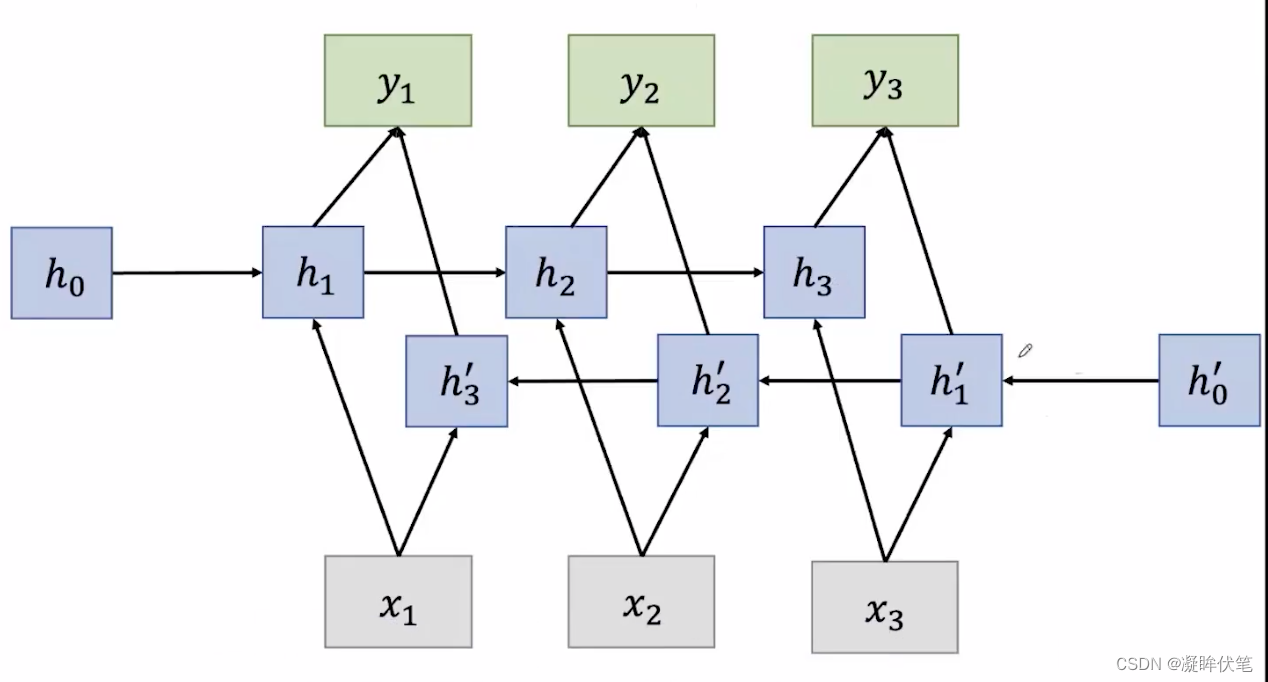
双向RNN
不仅需要前面的信息,还需要后面的信息,

总结

参考















 6797
6797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









