






文章目录
一、Spatial Transformer Layer
1.CNN is not invariant to scaling and rotation
1) CNN并不能真正做到scaling和rotation。
2) 如下图所示,在通常情况下,左右两边的图片对于CNN来说是不一样的。
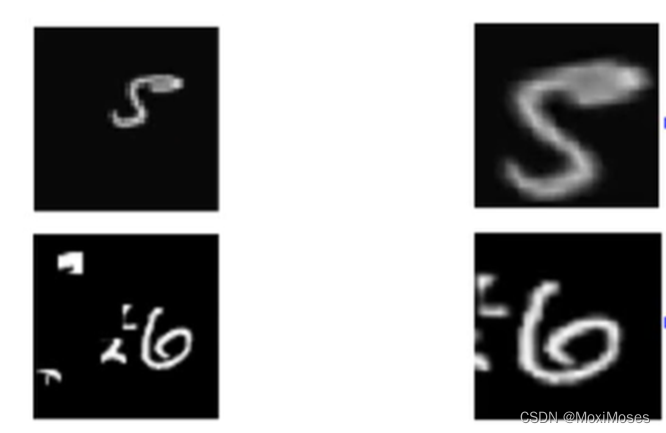
3)如下图所示,Spatial Transformer Layer是Neuron Network,而它的作用是多学习一层layer,对左边的图片做scaling和rotation后,能够被CNN识别出来。

2.How to transform an image/feature map
1) 平移其实是调整weight的过程。如下图所示,weight相同的颜色代表了权值相同,这里就是要将目标向下移动。
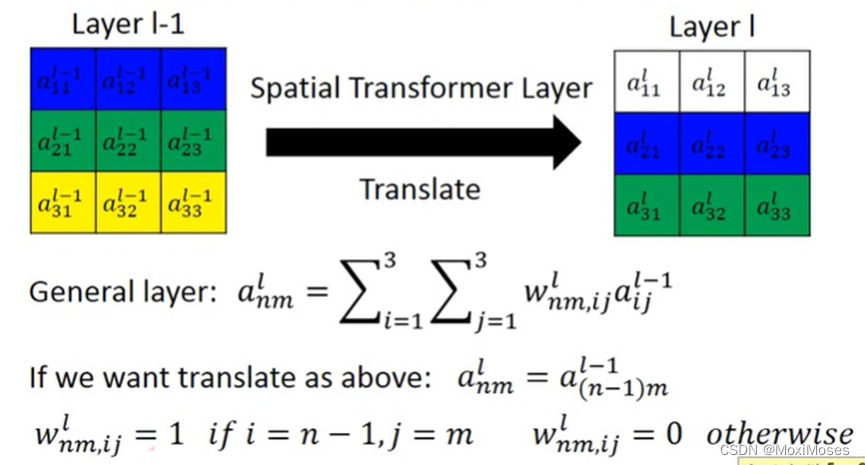
2) 如下图所示,向下平移,把[a13]^ (l-1)移动到[a23]^ l的位置上,[a13]^ (l-1)与[a23]^ l对应,[a23]^ l与左图的其他位置连接为0;向右旋转,把[a13]^ (l-1)移动到[a33]^ l的位置上,[a13]^ (l-1)与[a33]^ l对应, [a33]^ l与左图的其他位置连接为0。
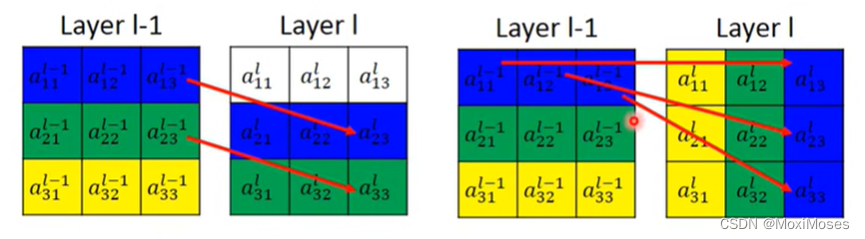
3) 用NN来控制联系。
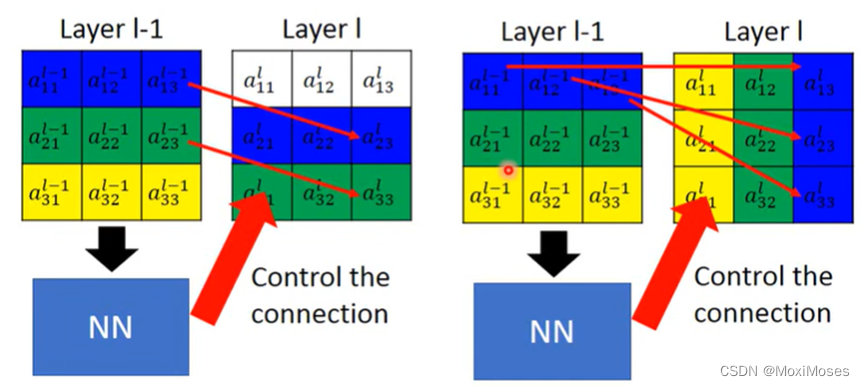
二、Image Transformation
1. 将图片放大,把图片中的每一个像素坐标化,矩阵[■(2&0@0&2)]是将图片放大,矩阵[■(0@0)]是对图片进行平移操作。
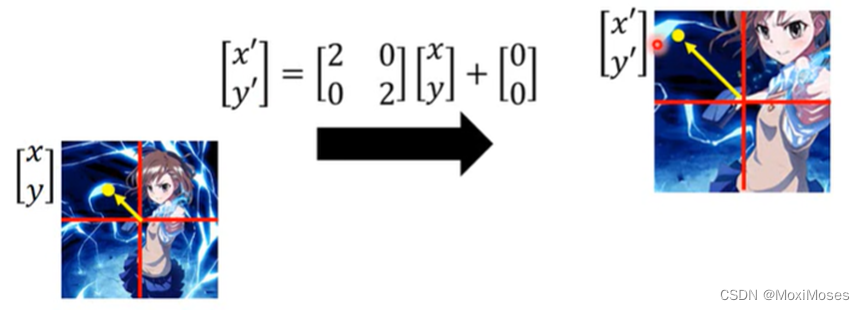
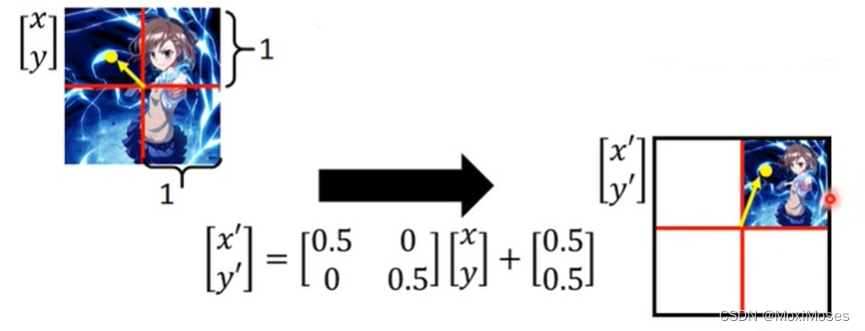
2. 将图片缩小,把图片中的每一个像素坐标化,矩阵[■(0.5&0@0&0.5)]是将图片缩小,矩阵[■(0.5@0.5)] 是对图片移动到右上方。
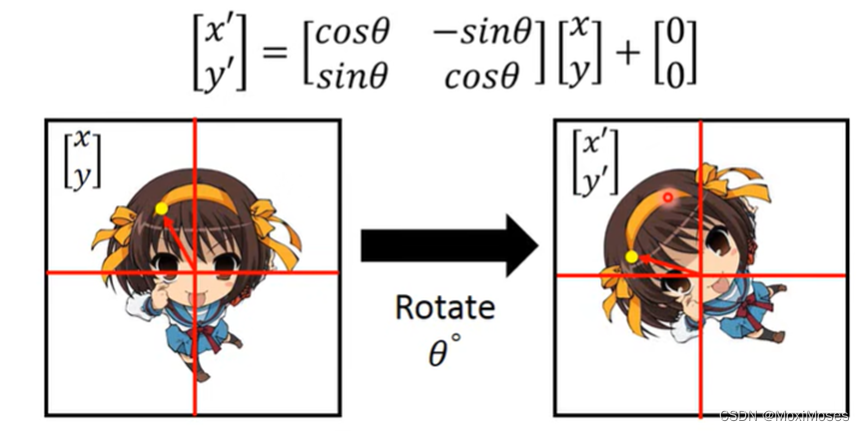
3. 将图片逆时针旋转θ度。
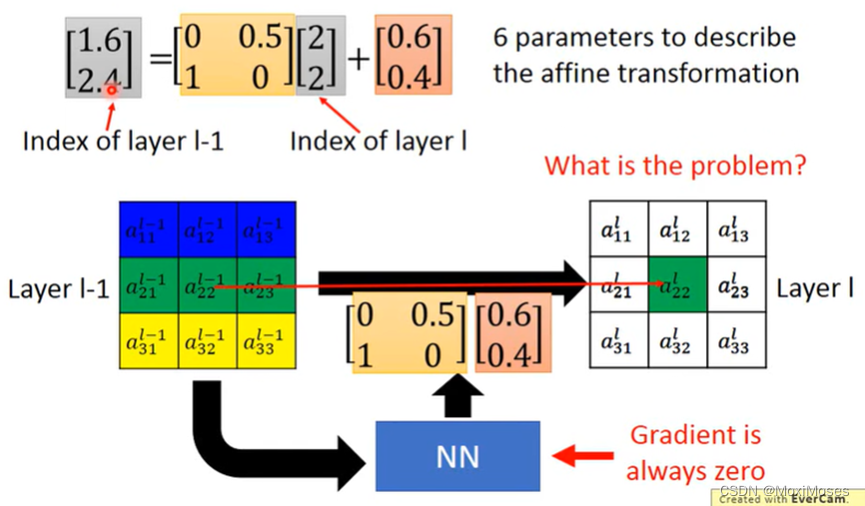
4. 综上所述,Spatial Transformer Layer只需要6个参数。但在实际计算中,当a、b、c、d、e、f的值为小数时,这个时候是不能进行Gradient Descent的,因为Gradient是一直为0的。
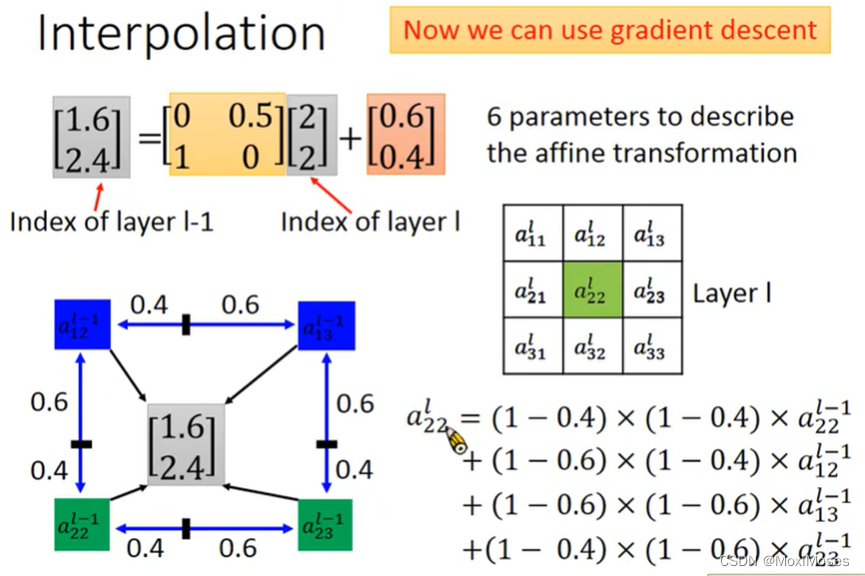
三、Interpolation
对于上面的问题,我们可以用Interpolation来解决,[a22] ^l = (1-0.4)* (1-0.4)* [a22] ^(l-1) + (1-0.6)* (1-0.4)* [a12] ^(l-1) + (1-0.6)* (1-0.6)* [a13] ^(l-1) + (1-0.4)* (1-0.6)* [a23] ^(l-1)。















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









