






文章目录
摘要
This week, I analyzed a paper on Convolutional Neural Networks, which proposed a new network structure called Deep Residual Networks, whose core module is the residual block. Because of the emergence of the residual block structure, the number of layers of the deep neural network model can be continuously deepened, and the problem of model degradation caused by the deepening of the number of convolutional network layers has been greatly solved. I tried to use the code to implement the residual block, and use the angle of eigenvalues and eigenvectors to analyze why the convolution kernel can extract features.
本周,一篇关于卷积神经网络的论文被我分析了,它提出了一种全新的网络结构叫做深度残差网络,其核心模块是残差块。因为残差块结构的出现,使得深度神经网络模型的层数可以不断变深,并且使因为卷积网络层数加深而导致模型退化问题得到了大幅解决。我尝试了用代码去实现残差块,以及用特征值和特征向量的角度去解析卷积核为什么可以提取特征。
文献阅读
1、题目
原文链接:Deep Residual Learning for Image Recognition
2、摘要
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8×deeper than VGG nets [41] but still having lower complexity. An ensemble of these residual nets achieves 3.57% erroron the ImageNet testset. This result won the 1st place on theILSVRC 2015 classification task. We also present analysison CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importancefor many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deepresidual nets are foundations of our submissions to ILSVRC& COCO 2015 competitions1, where we also won the 1stplaces on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
3、网络结构
3.1 网络示意图
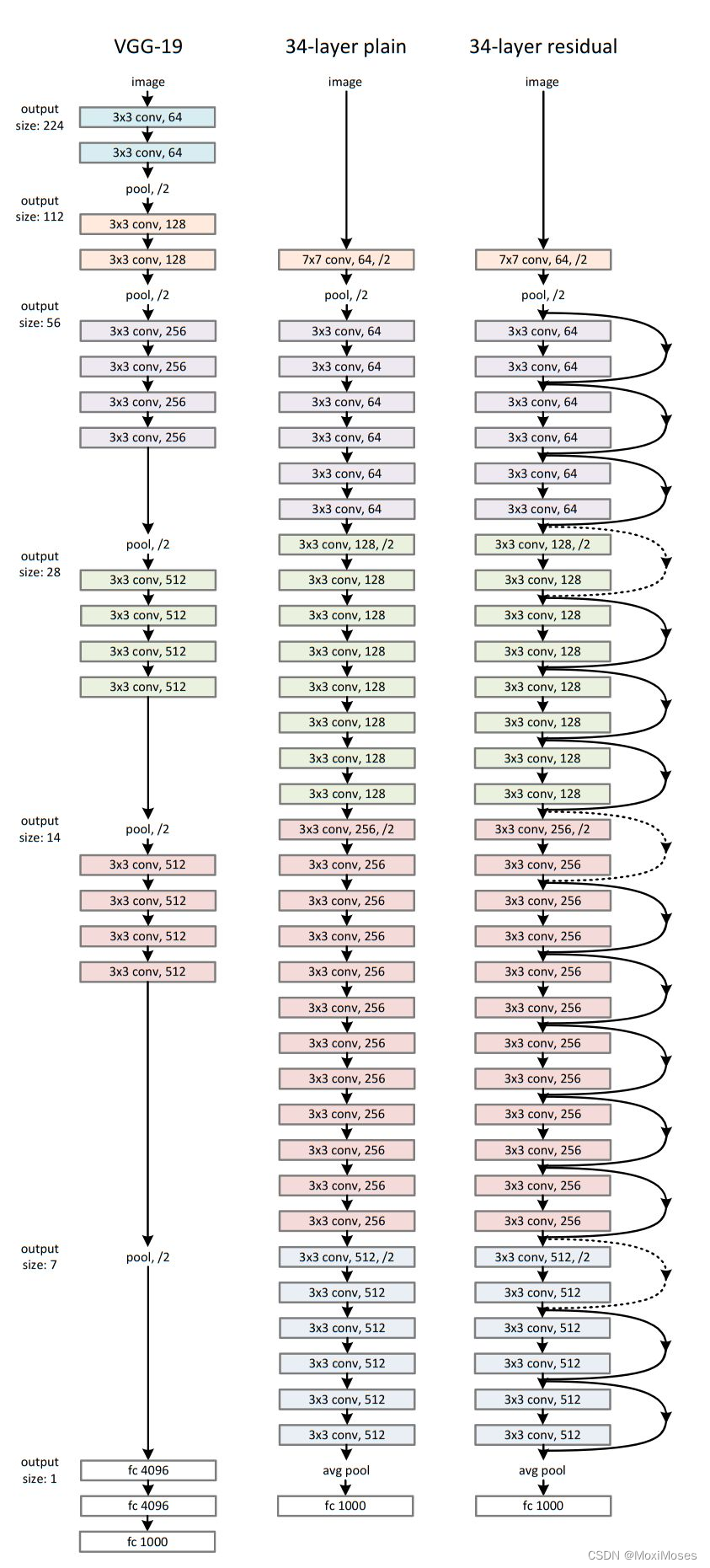
3.2 残差块
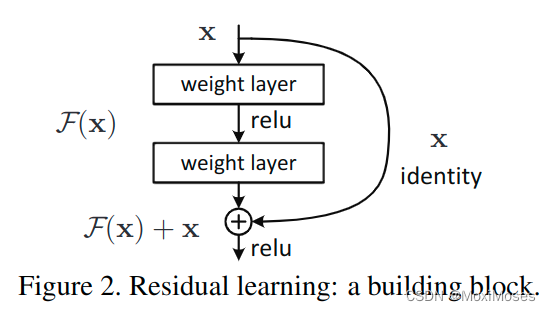
4、问题的提出
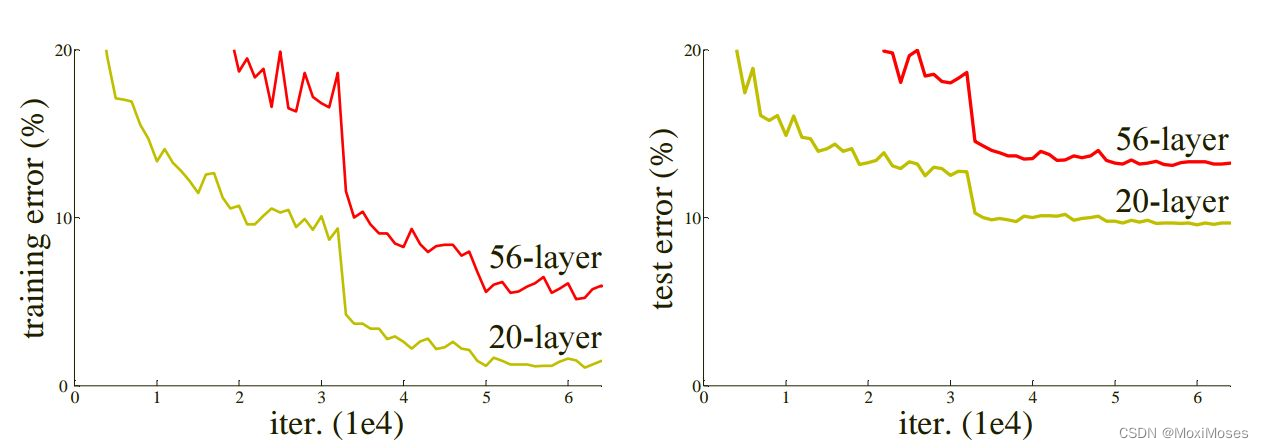
如下图所示,CIFER10在20层和56层普通网络结构下测试和训练过程中的损失。
4.1 网络加深的后果
在引入残差块结构之前,如果一个神经网络模型的深度过大,可能会导致梯度消失和梯度爆炸的问题。
当随着正则化方法的应用,可以缓解上述问题,但是随着深度的继续加深,又会出现模型退化的问题。
4.2 网络模型的退化
从上图中不难发现,简单地提高网络的深度,并没有带来精度的提升,反而导致网络模型的退化。
为什么加深网络会带来退化问题?
现在提出假设,假设新增加的层数不学习特征,保持恒等的输出,因此加深后的模型精度应该等于之前为加深时的水平,如果新增加的层数学习有用特征,那么加深后的模型精度应该大于之前为加深时的水平。
但是,实现上述情况是比较困难的,因为在训练过程中,每一层都会经过线性修正单元relu的处理,这样的处理方式必然导致特征信息的损失,因此简单的堆叠层数必然带来网络模型的退化。
当添加了带shortcut的残差块结构之后,会使得整个深度神经网络的层数可以大幅增加,深度变得更大,从而有时会带来更好的训练效果。
4.3 退化问题的解决
残差块的构想:通过shortcut/skip connection的方式,绕过这些新增的layer,通过shortcut通路来保持恒等。
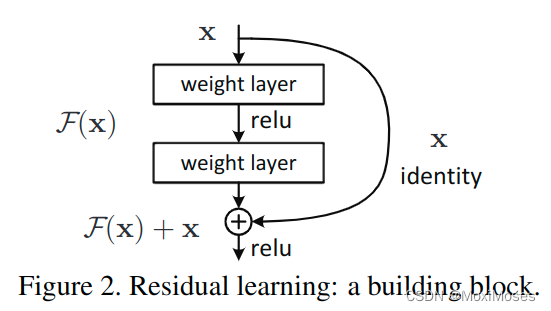
假设原有网络结构的基础映射为H(x),这里又添加了两个layer,在网络中的映射称为F(x),为了保持恒等性,所以使H(x) = F(x) + x 同原输出H(x)结果接近,因此这里我们只需要去优化F(x),将F(x)趋近于0。
5、残差学习-shortcut恒等映射
残差块的结构:
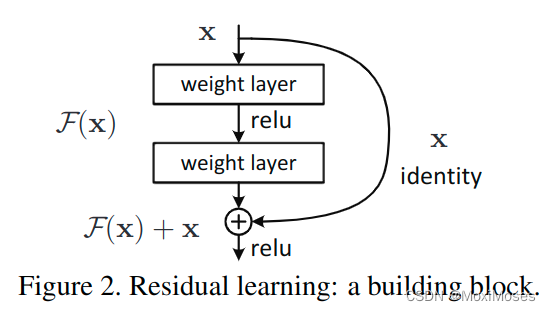
残差块的公式:

其中:
x:输入
y:输出
F(x, {Wi}):需要进行残差学习的函数
残差函数可以表示为:

其中:
激活函数为ReLU,省略了偏差bias。这个公式没有引入额外参数,因此也不增加计算复杂度。
因为x和F(x)的尺寸必须相等,因此可以通过矩阵Ws来改变输入x的维度:

在残差块中堆叠的layer数量至少为2,因为如果只增加了1层,整个表达式便退化成了线性方程,而这就失去作用了。
6、实验
论文中,对ImageNet2012分类数据集评估了残差网络,128万张训练图,5万张验证图,1000个分类,在测试服务器上通过10万张测试图评估得到了top-1和top-5错误率。
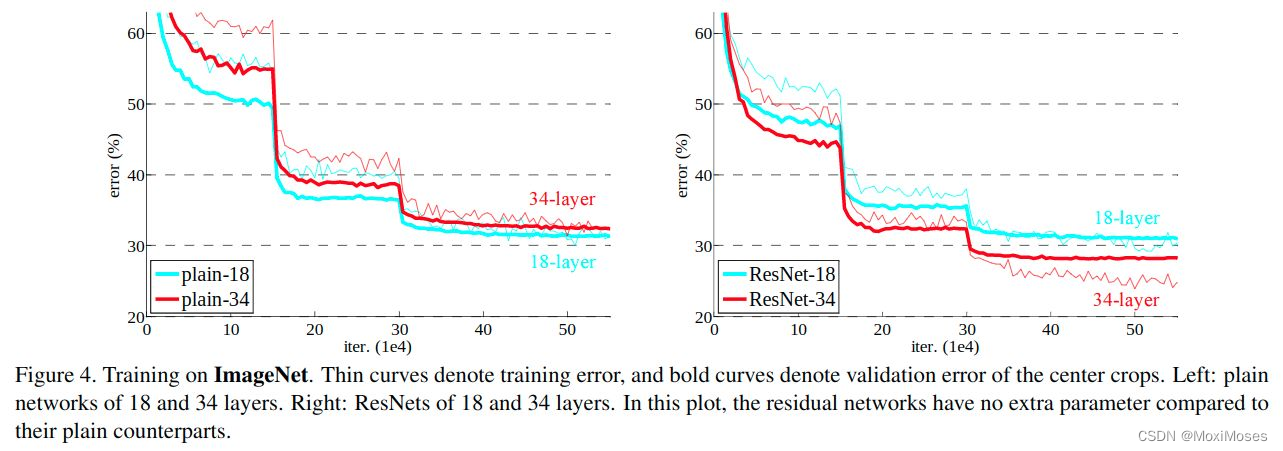
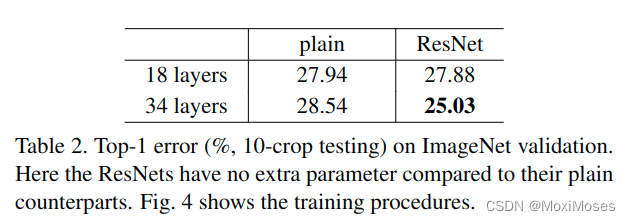
6.1 普通网络
在普通网络的对比中,34 layers 比18 layers的误差大,存在模型退化现象。
6.2 残差网络
1)当模型深度不是很深时,普通网络和ResNet网络的准确率差不多,这里是因为通过一些初始化和正则化方法,可以降低普通卷积神经网络的过拟合问题。
2)当模型的层数不断加深时,就会出现模型退化的问题,此时ResNet很好地解决了退化问题。
6.3 不同深度ResNet的对比
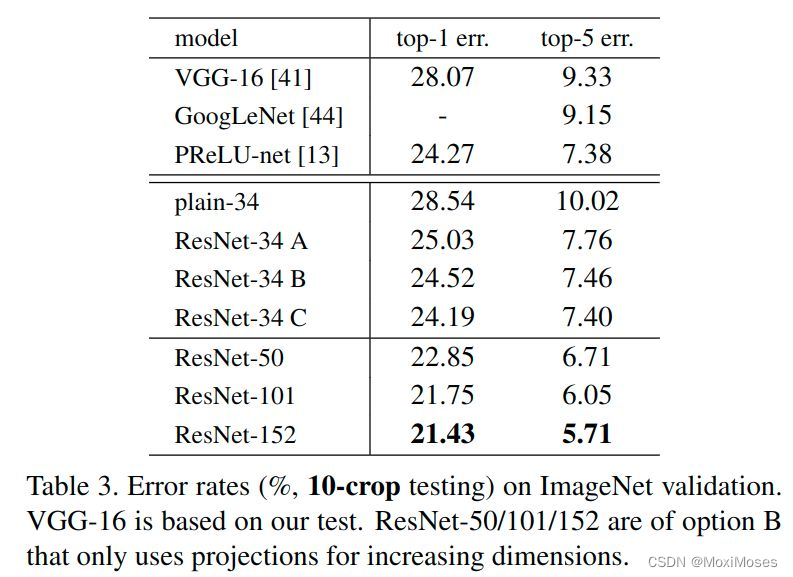
从图中不难看出,ResNet网络随着layer深度加深,网络的精度越高,也没有出现模型退化的现象。
6.4 经典网络对比
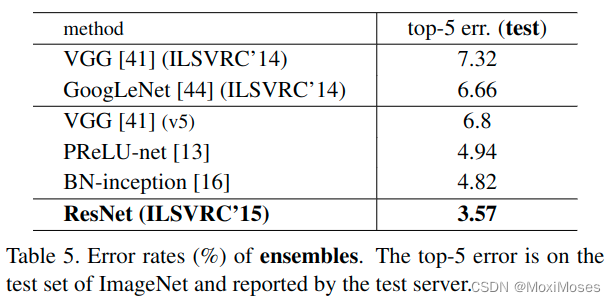
从图中不难发现,ResNet网络的表现优于其他网络。
7、结论
1)随着网络层数地增加,普通网络结构的训练误差相比残差网络更高。
2)深度残差网络可以更容易地通过增加深度来提高网络精度,而且结果比浅层网络好很多。
深度学习
1、为什么卷积核可以提取特征
从特征值和特征向量的角度分析:
1)什么是卷积操作的本质?
卷积就是对每个像素点领域范围内的像素进行加权求和。
2)什么是图像的特征?
图像的本质是矩阵,对图像进行特征提取,提取出来的特征就是向量,对应特征向量,而每一个特征的重要性可以用特征值来表示。
3)什么是特征向量和特征值?
矩阵A经过特征分解后就会得到特征向量和特征值,即Ax = λx,其中x是特征向量,λ是特征值。
理解矩阵和矩阵乘法的概念:矩阵代表线性变换规则,乘法代表一个变换。也就是说,向量x在矩阵A的变换规则下就可以变换为向量y。在线性代数中指出了它的几何意义:矩阵乘法就是把一个向量变成另一个方向或长度都不相同的新向量。在这个变换过程中,原向量发生了旋转伸缩的变换,而对原向量只进行伸缩变换而无旋转操作后得到的就是特征向量,伸缩比例就是对应的特征值。
举例说明,假设A是一个100 * 100的矩阵,经过A = QEQ逆的分解后,得到特征向量Q和特征值E,其中E为100 * 100的对角矩阵,对角线上的数值就是特征值,因此可以说A经过分解后提取出图像的100个特征,这100个特征的重要性由E中对角线上的值来表示。
4)结论
图像使用卷积核提取特征就相当于为图像矩阵A寻找最合适的特征向量集。神经网络就是通过反向传播来不断拟合一个非常逼近的特征向量,也就是我们的卷积核的值。有了这个权重值,让它与原始图像矩阵相乘,就能得到我们想要的特征了。
2、基于pytorch的残差网络实现
定义残差块

残差块主要由两个3 * 3的卷积层组成,并且加入批量标准化,即在每一个卷积层后会经过一个批量标准化层和ReLU激活函数。从上图中我们可以发现,我们可以跳过这两个卷积运算,直接把输入放在最后的ReLU激活函数前面,但是这样的设计要求经过两次卷积层后的输出与输入的形状一致,从而使它们相加。而图中的1 * 1卷积层是为了防止通道数不一致,从而需要一个1 * 1的卷积层对通道进行升维或降维。
import torch
from torch import nn
import torch.nn.functional as F
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, strides=1, use_1x1conv=False):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(input_channels,
num_channels,
kernel_size=3,
padding=1,
stride=strides)
self.conv2 = nn.Conv2d(num_channels,
num_channels,
kernel_size=3,
padding=1,
stride=strides)
# 如果需要变换维度, 增加1 * 1卷积层
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels,
num_channels,
kernel_size=1,
stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, x):
y = F.relu(self.bn1(self.conv1(x)))
y = self.bn2(self.conv2(y))
if self.conv3:
x = self.conv3(x)
y += x
return F.relu(y)
定义产生残差块的函数
ResNet-18总计有4个残差块stack,每个stack包含两个残差块,因此下面定义产生残差块的函数:
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))
else:
blk.append(Residual(input_channels, num_channels))
return blk
定义ResNet模型
我们以ResNet-18为例,如下图所示。

ResNet的结构:
首先经过输出通道数为64,步长为2的7 * 7卷积层,然后进入一层批量标准化层和一个步长为2的3 * 3的最大池化层。
此后,ResNet使用了4个残差块组成的模块,每一个模块使用残差块的输出通道数一致,其中第一个模块的输出通道数与输入通道数一致。
由于此前使用了步长为2的最大汇聚层,因此不需要减小宽和高,而此后的每一个模块在第一个残差块会将上一个模块的通道数翻倍,并将宽和高减半。
class ResNet(nn.Module):
def __init__(self):
super(ResNet, self).__init__()
self.b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
self.b3 = nn.Sequential(*resnet_block(64, 128, 2))
self.b4 = nn.Sequential(*resnet_block(128, 256, 2))
self.b5 = nn.Sequential(*resnet_block(256, 512, 2))
self.out = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(512, 10))
def forward(self, x):
y = y = self.out(self.b5(self.b4(self.b3(self.b2(self.b1(x))))))
return y
net = ResNet()
print(net)
查看网络结构:
ResNet(
(b1): Sequential(
(0): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(b2): Sequential(
(0): Residual(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(b3): Sequential(
(0): Residual(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv3): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(b4): Sequential(
(0): Residual(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(b5): Sequential(
(0): Residual(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(out): Sequential(
(0): AdaptiveAvgPool2d(output_size=(1, 1))
(1): Flatten(start_dim=1, end_dim=-1)
(2): Linear(in_features=512, out_features=10, bias=True)
)
)
总结
残差网络的出现大幅度提高了模型精度,因为它能够大幅度地解决神经网络中模型退化问题,让其摆脱了深度的束缚。在下周,我将继续阅读卷积神经网络的相关论文,以及用代码去实现CNN的相关模型。















 2925
2925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









