






 本文深入探讨Python在数据挖掘领域的应用,特别是FP-Growth算法的理解与实践。涵盖程序架构分析、关键函数使用、迭代器与生成器概念、类定义及继承等,适合初学者和进阶学习者。
本文深入探讨Python在数据挖掘领域的应用,特别是FP-Growth算法的理解与实践。涵盖程序架构分析、关键函数使用、迭代器与生成器概念、类定义及继承等,适合初学者和进阶学习者。
此程序按照《数据挖掘导论》部分P224-P230理解,下面几幅图为《数据挖掘:技术与导论》插图,与程序不太吻合
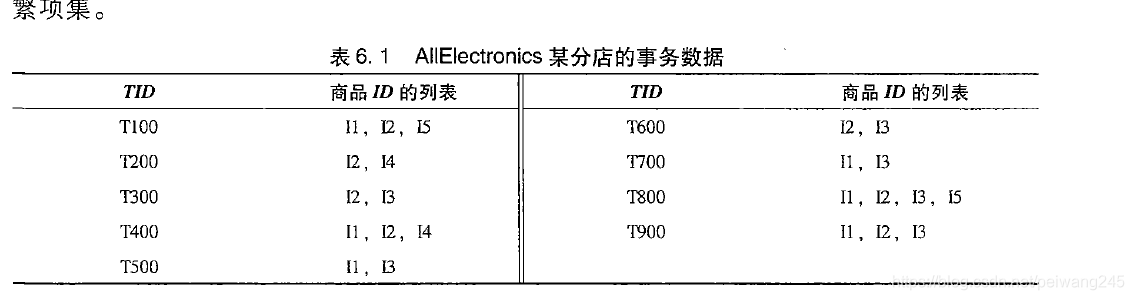
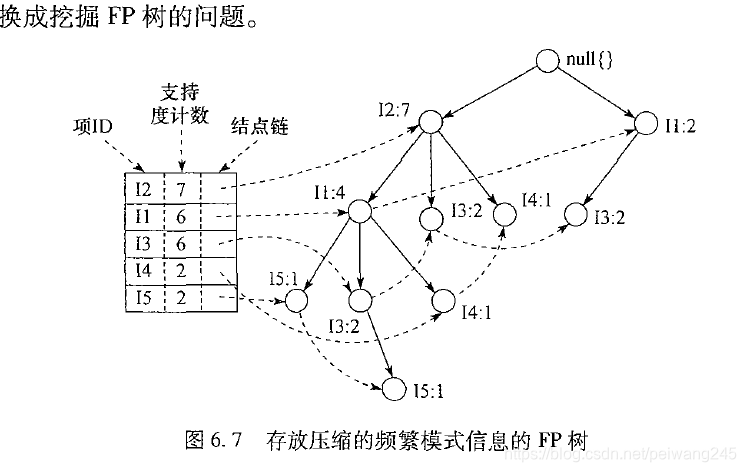
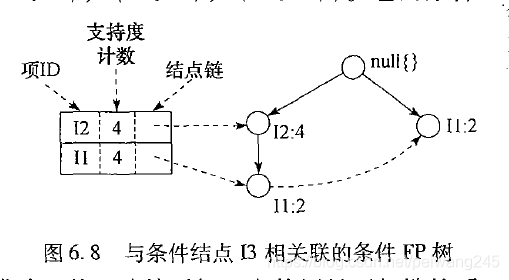
⑴.
刚开始看别人程序时遇见新的知识点可以先不求甚解,只有尝试过一遍或者过完程序有一些自己的理解时可以在进阶学习其奥妙之处,初始时应当以迅速走通程序,理解程序脉络与语句意思为最优。
⑵.
读别人的程序先把程序的架构弄清,比如程序内部函数的调用关系,那个是主函数,那个是被调用函数,哪个是主成分,哪个是被调用部分。
⑶.
一个.py文件中,一个函数定义中可以调用函数体后面定义的类
python -m fp_growth -s 4 examples/tsk.csv???
1.defaultdict(lambda:0)的使用方法:
这个类是dict的一个子类,重写了一个方法并增加了一个事件变量。在实例化的时候,第一个参数提供给default_factory的初始化函数。这个参数可以是一个类型或者函数,至于是类型这不难理解,其实类型基本上都是工厂函数。但是,有时候我们想用此方法传入一个常量,这个时候就需要自己单独设计一个常量函数或者直接使用lambda表达式。
先看如下的示范:
>>> fromcollections import defaultdict
>>> c1 =defaultdict(int)
>>>c1.get(123)
>>>c1.get('abc')
>>> defConst():
return 23
>>> c2 =defaultdict(Const)
>>>c2.get(123)
>>> c2
defaultdict(<functionConst at 0x000001D7E26F58C8>, {})
>>>c2[123]
23
>>>c2['abc']
23
>>>c1[123]
0从上面可以看出,这种方式可以为一个字典对象不存在的key自动给出一个默认的value。用上面的这种方式自然是可以实现value为某个常量,但是使用lambda可以使得代码更为简洁:
>>> c3 =defaultdict(lambda :123)
>>>c3[12]
1232. items = dict((item, support) for item, support in items.iteritems()
if support >= minimum_support)
Python 文档解释:
- dict.items(): Return a copy of the dictionary’s list of (key, value) pairs.
- dict.iteritems(): Return an iterator over the dictionary’s (key, value) pairs.
dict.items()返回的是一个完整的列表,而dict.iteritems()返回的是一个生成器(迭代器)。
dict.items()返回列表list的所有列表项,形如这样的二元组list:[(key,value),(key,value),...],dict.iteritems()是generator, yield 2-tuple。相对来说,前者需要花费更多内存空间和时间,但访问某一项的时间较快(KEY)。后者花费很少的空间,通过next()不断取下一个值,但是将花费稍微多的时间来生成下一item。

3.transaction.sort(key=lambda v: items[v], reverse=True)#降序排列
key表示列表中给谁排序,key就是谁。
4.Route = namedtuple('Route', 'head tail')
nemedtuple定义了一个类型Route,类名字为Route,类型为Route
如果tuple中的元素很多的时候操作起来就比较麻烦,有可能会由于索引错误导致出错。我们今天介绍的namedtuple对象就如它的名字说定义的那样,你可以给tuple命名,具体用户看下面的例子:
import collections
Person=collections.namedtuple('Person','name age gender')
print'Type of Person:',type(Person)
Bob=Person(name='Bob',age=30,gender='male')
print'Representation:',Bob
Jane=Person(name='Jane',age=29,gender='female')
print'Field by Name:',Jane.name
for people in[Bob,Jane]:
print"%s is %d years old %s" % people来解释一下nametuple的几个参数,以Person=collections.namedtuple(‘Person’,'name age gender’)为例,其中’Person’是这个namedtuple的名称,后面的’name age gender’这个字符串中三个用空格隔开的字符告诉我们,我们的这个namedtuple有三个元素,分别名为name,age和gender。我们在创建它的时候可以通过Bob=Person(name=’Bob’,age=30,gender=’male’)这种方式,这类似于Python中类对象的使用。而且,我们也可以像访问类对象的属性那样使用Jane.name这种方式访问namedtuple的元素。其输出结果如下:
Type of Person: <type 'type'>
Representation: Person(name='Bob', age=30, gender='male')
Field by Name: Jane
Bob is 30 years old male
Jane is 29 years old female但是在使用namedtyuple的时候要注意其中的名称不能使用Python的关键字,如:class def等;而且也不能有重复的元素名称,比如:不能有两个’age age’。如果出现这些情况,程序会报错。但是,在实际使用的时候可能无法避免这种情况,比如:可能我们的元素名称是从数据库里读出来的记录,这样很难保证一定不会出现Python关键字。这种情况下的解决办法是将namedtuple的重命名模式打开,这样如果遇到Python关键字或者有重复元素名时,自动进行重命名。看下面的代码:
import collections
with_class=collections.namedtuple('Person','name age class gender',rename=True)
print with_class._fields
two_ages=collections.namedtuple('Person','name age gender age',rename=True)
print two_ages._fields其输出结果为:
('name', 'age', '_2', 'gender')
('name', 'age', 'gender', '_3')我们使用rename=True的方式打开重命名选项。可以看到第一个集合中的class被重命名为 ‘_2′ ; 第二个集合中重复的age被重命名为 ‘_3′这是因为namedtuple在重命名的时候使用了下划线 _ 加 元素所在索引数的方式进行重命名。
5. assert condition_item is not None
https://www.cnblogs.com/liuchunxiao83/p/5298016.html
一般的用法是:
assert condition
用来让程序测试这个condition,如果condition为false,那么raise一个AssertionError出来。逻辑上等同于:
if not condition: raise AssertionError()
6.类中的函数与普通函数的区别,第一个默认参数为self
7. from optparse import OptionParser
命令行参数
http://www.jb51.net/article/59296.htm
http://blog.csdn.net/hawkerou/article/details/53436052
http://blog.csdn.net/freeking101/article/details/52470744
8.class FPTree(object):
https://www.cnblogs.com/sesshoumaru/p/6042322.html
1. object类是Python中所有类的基类,如果定义一个类时没有指定继承哪个类,则默认继承object类。
>>> class A: pass
>>> issubclass(A,object) True
2. object类定义了所有类的一些公共方法。
>>> dir(object) ['__class__', '__delattr__',
'__dir__', '__doc__', '__eq__', '__format__',
'__ge__', '__getattribute__', '__gt__', '__hash__',
'__init__', '__le__', '__lt__', '__ne__',
'__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__']3. object类没有定义 __dict__,所以不能对object类实例对象尝试设置属性值。
>>> a = object() >>> a.name = 'kim' # 不能设置属性 Traceback (most recent call last): File "<pyshell#9>", line 1, in <module> a.name = 'kim' AttributeError: 'object' object has no attribute 'name' #定义一个类A >>> class A: pass >>> a = A() >>> >>> a.name = 'kim' # 能设置属性
- object是Python对数据的抽象,它是Python程序对数据的集中体现。
- 每个对象都有一个标识,一个类型和一个值。
- 对象的类型决定对象支持的操作。
- 某些对象的值可以更改。 其值可以改变的对象称为可变对象;对象的值在创建后不可更改的对象称为不可变对象。
https://www.cnblogs.com/attitudeY/p/6789370.html
#新式类是指继承object的类 class A(obect): ........... #经典类是指没有继承object的类 class A: ...........
Python中推荐大家使用新式类 :
1.新的肯定好哈,已经兼容经典类
2.修复了经典类中多继承出现的bug
http://blog.csdn.net/langb2014/article/details/54800203
9.from itertools import imap
imap和map不同的是,imap返回的是一个iteration对象,而map返回的是一个list对象。
10 for transaction in imap(clean_transaction, transactions):
master.add(transaction)
imap()
http://blog.csdn.net/hehe123456ZXC/article/details/52597448
11. for item in self._routes.iterkeys():
yield (item, self.nodes(item))
https://www.cnblogs.com/z-books/p/5316947.html
iterkeys返回一个迭代器,而keys返回一个list,迭代器用起来很灵巧,可以迭代不是序列但表现出序列行为的对象,例如字典的 key,一个文件的行等。迭代器就是有一个 next() 方法的对象,而不是通过索引来计数。当你或是一个循环机制(例如 for 语句)需要下一个项时,调用迭代器的 next() 方法就可以获得它。条目全部取出后,会引发一个 StopIteration 异常,这并不表示错误发生,只是告诉外部调用者,迭代完成.
Python 还引进了三个新的内建字典方法来定义迭代:
myDict.iterkeys() (通过 keys 迭代),myDict.itervalues() (通过 values 迭代),以及 myDicit.iteritems() (通过 key/value 对来迭代)。
12 def conditional_tree_from_paths(paths):
"""Build a conditional FP-tree from the given prefix paths."""
tree = FPTree()
condition_item = None
items = set()
https://www.cnblogs.com/tina-python/p/5468495.html
13.for itemset in find_with_suffix(master, []):
执行yield itemset 函数会返回到下面语句中的result.append((itemset,support))处,
for itemset, support in find_frequent_itemsets(myfault, 0.1, False):
result.append((itemset,support))
再次单步调试返回到for itemset, support in find_frequent_itemsets(myfault, 0.1, False):处,
进入 find_frequent_itemsets函数内部,会停留到 yield itemset位置,单步调试会返回到for itemset in find_with_suffix(master, []):处。此为《生成器yield》上面提到的“当你问他要下一个数时,他会从上次的状态”。
(当你问生成器要一个数时,生成器会执行,直至出现 yield 语句,生成器把yield 的参数给你,之后生成器就不会往下继续运行。 当你问他要下一个数时,他会从上次的状态。开始运行,直至出现yield语句,把参数给你,之后停下。如此反复直至退出函数。(以上关于yield的描述,在后面列举一个简单的例子来解释这段话))
注意下面程序:输出顺序(自己编:)注意:只能用gen.next()在交互行运行,不能用单步跟踪进入函数myprint()内部调试。
def fib(max):
a, b = 1, 1
while a < max:
yield a #generators return an iterator that returns a stream of values.
a, b = b, a+b
def myprint(max):
a=max
for itemset in fib(a):
print 'itemset:'
print itemset
print 'x:'
for x in range(itemset):
yield x
print x
gen=myprint(100)#####################################
#####################################
FP-Growth程序修改
原程序发现频繁项集是基于:《数据挖掘导论》,P227,发现一某一个特定项结尾的频繁项集的自底向上策略等价于基于后缀的方法:e de cde bcde abcde
改进方案①:
基于前缀的方法:a ab abc abcd abcde
改进方案2:基于父节点孩子节点链思想
2.1 基于《数据挖掘导论》节点链父节点孩子节点思想挖掘双项频繁与关联关系
2.2基于父节点孩子节点挖掘,参照matlab myFPGrowth.m程序
为了好看,暂且选取2.2方法。

















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









