







 本文深入探讨了列式存储格式ORC与Parquet的特点与应用场景,对比了二者在压缩比、查询性能及对嵌套数据的支持等方面的优劣。分析了在Hive与Spark环境下,ORC与Parquet的不同表现,为大数据存储格式的选择提供了指导。
本文深入探讨了列式存储格式ORC与Parquet的特点与应用场景,对比了二者在压缩比、查询性能及对嵌套数据的支持等方面的优劣。分析了在Hive与Spark环境下,ORC与Parquet的不同表现,为大数据存储格式的选择提供了指导。
列式存储 ORC VS Parquet
关于列式数据库的一些说明
列式存储格式的适用场景
列式存储,顾名思义就是按照列进行存储数据,把某一列的数据连续的存储,每一行中的不同列的值离散分布。列式存储技术并不新鲜,在关系数据库中都已经在使用,尤其是在针对OLAP场景下的数据存储,由于OLAP场景下的数据大部分情况下都是批量导入,基本上不需要支持单条记录的增删改操作,而查询的时候大多数都是只使用部分列进行过滤、聚合,对少数列进行计算(基本不需要select * from xx之类的查询)。
下图展示了行和列的区别:
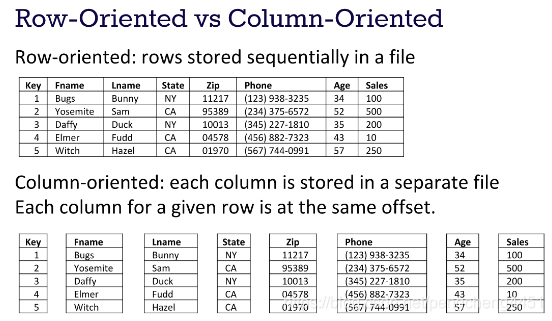
列式存储:
- 只需查询某些列
- 需要大量数据做聚合操作
- 对存储空间较敏感
行式存储:
- 只需查询某些行
- 对数据经常有增删改的要求,俗称的OLTP
行列存储的优缺点
列式存储主要优点表现在三块:压缩(列类型一样,更好的压缩比,省空间)、投影下推(只需读取某些列,不需要读取整行)、谓词下推(过滤条件)
| 项目 | 行式存储 | 行式存储 |
|---|---|---|
| 优点 | 数据被保存在一起 INSERT/UPDATE容易 | 查询时只有涉及到的列会被读取 投影(projection)很高效 任何列都能作为索引 |
| 缺点 | 选择(Selection)时即使只涉及某几列,所有数据也都会被读取 | 选择完成时,被选择的列要重新组装 INSERT/UPDATE比较麻烦 |
ORC VS Parquet
二者的文件结构图
慢慢再添加二者的详细区别和源码
Parquet
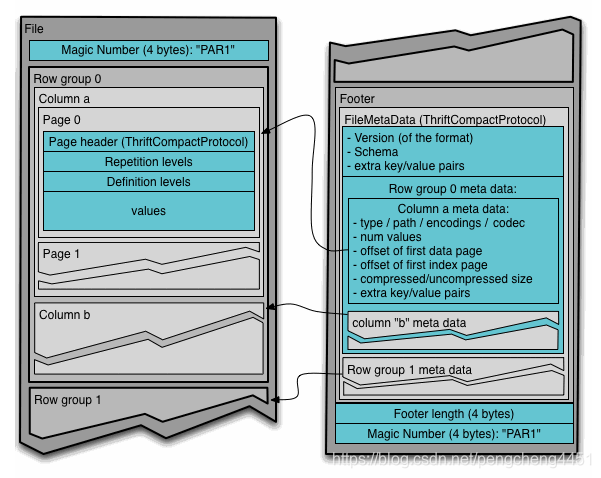
Parquet的一个独特的特点是它也可以以列式结构存储嵌套结构的数据。这意味着在Parquet文件格式中,即使是嵌套的字段也可以单独读取,而不需要读取嵌套结构中的所有字段。Parquet格式底层使用record shredding和assembly algorithm(Google Dremel论文)来实现列式存储。其文件结构主要由三块信息构成:
- Row group:多行数据的在逻辑水平方向上的分区。Row group是由数据集里每个列的列块(column chunk)构成;
- Column chunk:某个特定列的数据块。这些列块位于特定的行组中,并且保证在文件中是连续的;
- Page:列块(Column chunk)被划分为连续、紧凑的页面。这些页面共享一个共同的标题(header),在读取数据的时候可以跳过他们不感兴趣的页。
Parquet整体架构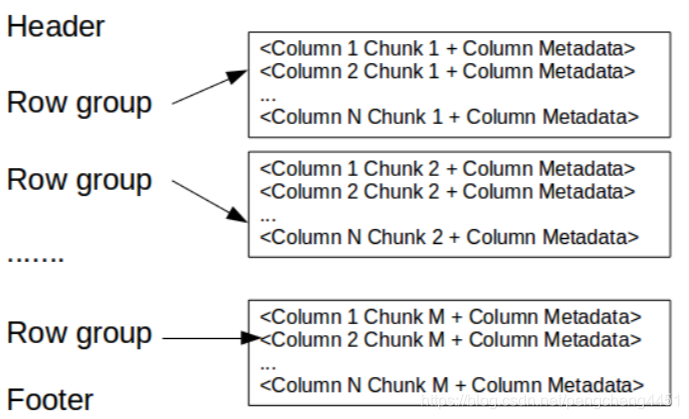
从这里可以看到,Header里面仅仅只包含一个魔术数,指明这是一个Parquet格式的文件。中间是一到多个Row group,包含了真正的文件数据信息,最后是Footer,包含了元数据信息。
Footer中有以下几项:
- 文件元数据:文件元数据包含所有列的元数据起始位置信息。当读取文件时,首先应该读取文件的元数据,从而找到感兴趣的所有列块,然后应该按顺序读取列块。另外,它还包括格式的版本版本、数据结构和一些额外的键-值对信息
- 文件元数据的大小
- 魔术数
ORC
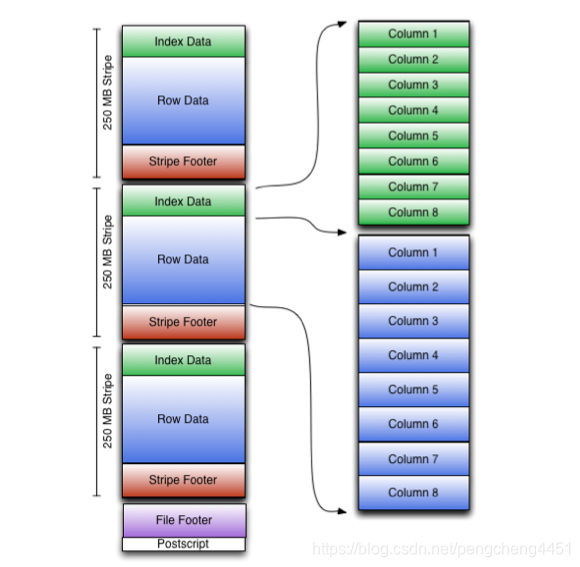
ORC文件包含称为Stripe的行数据组,File Footer的辅助信息,以及在文件的末尾,一个Postscript保存压缩参数和压缩页脚的大小。
默认的stripe大小是250mb。stripe设置的越大,则允许从HDFS读取的数据规模也越大、越高效。
- File Footer包含文件中的stripe列表、每个stripe的行数和每个列的数据类型。它还包含列级聚合计数、最小值、最大值和总和。
- Stripe Footer包含一个目录的流位置。
- Row Data是真正的数据所在位置,扫描表的过程就是在发生在这里。
- Index Data包括每个列的最小值和最大值以及行在每个列中的位置。ORC stripe data仅用于stripes和row groups的选择,而不用于应答查询。
关于ORC更详细的介绍,请到该博客。
选择哪一种列式存储较好
我自己也查找了很多资料,根据目前收集到的信息,综合比较来说,建议选择orc,尤其是在使用Hive做数仓的时候。如果只是单纯的使用Spark,建议用Parquet。理由如下:
- ORC有更好的压缩比,占有的空间相对较少。下图是从cloudera社区找到的,可以看出压缩比还是挺可观的,最起码可以得到一个结论:无论是使用哪一种列式存储都是比使用textfile这种格式要好,尤其是在使用Hive的时候。

- Hive和Spark的向量化读取都是支持orc的,但是Hive却不支持Parquet格式。Spark在2.3的版本之后,提供了对orc的向量化读取的支持(小声哔哔:jira上面有个issue显示hive支持对Parquet格式的vectorized reader,可是官网却说必须使用orc格式的才能使得Hive的Vectorized Query Execution生效,有点疑惑,希望有大佬回答下)。
- Hive的CBO优化器对orc支持的更好。hive的cbo优化器能够获取orc的列级别元数据信息,从而能够生成更好的执行计划。
- 嵌套格式很复杂的数据就选择Parquet,普通格式的数据多就选择orc。Parquet格式实现了Google Dremel,把数据像树一样存储,对嵌套格式的数据支持的好。
- ORC提供了ACID事务性支持。请记住,尽管orc提供事务性的功能,但是并不是为了满足OLTP的需求,主要是为了解决流式数据在Hive中的一致性问题。(注意:Spark 2系列的版本是不支持读取Hive的内部事务表,但是Hive 3的事务表又是默认的,因此需要改参数关闭事务性。目前的Spark 3系列,正在处理这个问题)
- Parquet查询性能略好于ORC。
- 在长时间任务执行中,当Hive查询ORC表时,GC调用频率降低了10倍。
参考资料
- https://medium.com/@dhareshwarganesh/benchmarking-parquet-vs-orc-d52c39849aef
- https://blog.csdn.net/dc_726/article/details/41143175
- https://mp.weixin.qq.com/s/r0N8LOTmONAgoqFklznhgg
- https://developer.aliyun.com/article/226990
- https://community.cloudera.com/t5/Support-Questions/ORC-vs-Parquet-When-to-use-one-over-the-other/td-p/95942
- https://medium.com/@oswin.rh/parquet-avro-or-orc-47b4802b4bcb
- http://leelaprasadhadoop.blogspot.com/2017/05/difference-between-orc-and-parquet.html
- https://www.datanami.com/2018/05/16/big-data-file-formats-demystified/
- https://towardsdatascience.com/demystify-hadoop-data-formats-avro-orc-and-parquet-e428709cf3bb
- Parquet官网https://parquet.apache.org/documentation/latest/
- https://blog.clairvoyantsoft.com/big-data-file-formats-3fb659903271

















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









