






目录
基于sqlzoo的mysql数据库引擎,只学习SQL语句的查询语句部分
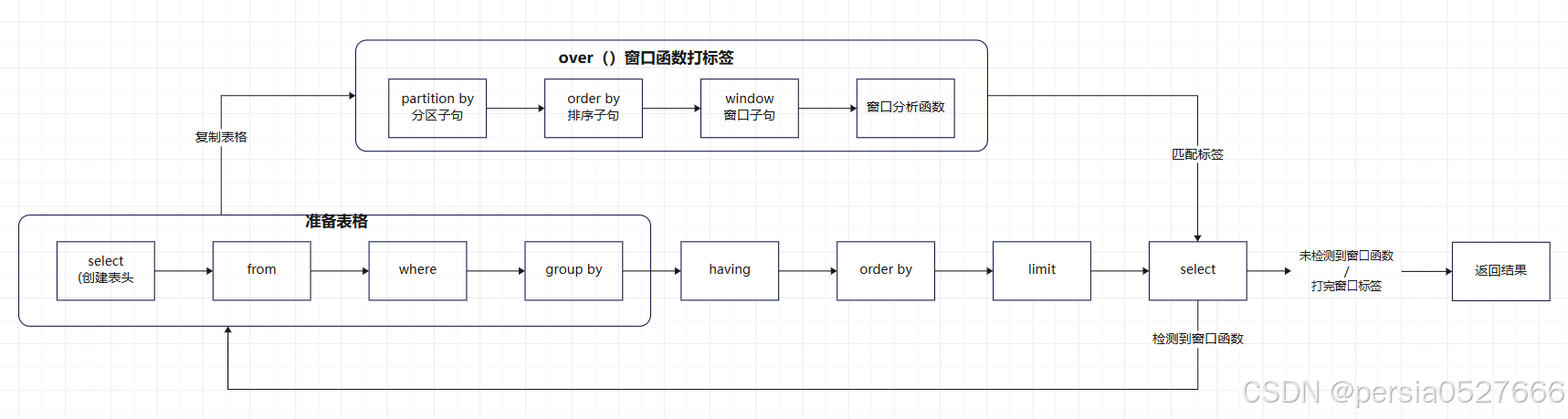
SQL查询语句语法结构和运行顺序
- 语法结构:select--from--where--group by--having--order by--limit
- 运行顺序:from--where--group by--having--order by--limit--select
【基础语句】
主知识点一:SELECT & FROM
【标准语法】
- 基础语法
SELECT 字段名 决定这一段查询最后展示的字段
FROM 表名 指定这段查询语句设计的数据来源
这是一段查询语句中必不可少的两个核心语句,SELECT 和 FROM 分别十两个核心语句中的关键字
- 查询所有列
SELECT *
FROM 表名
- 别名语法
SELECT 字段名 as(可省略) 别名
FROM 表名
【SELECT中使用DISTINCT 进行去重】
但是是对完全相同的行数据进行去重,不能指定字段名
注明是对SELECT出来的字段进行完全相同的行数据进行去重 不是原表
【SELECT中计算字段的运用】
字段名可以是表中有的字段名的简单计算式
主知识点二:WHERE
标准语法
SELECT 字段名
FROM 表名
[WHERE 表达式] 限定查询行必须满足的条件 进行筛选 是可选项
【运算符一览】
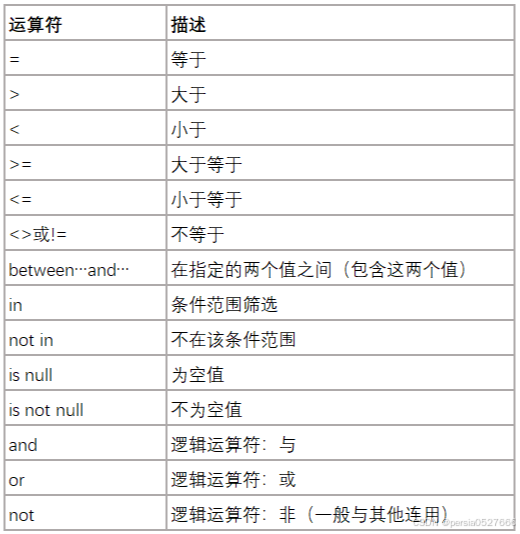
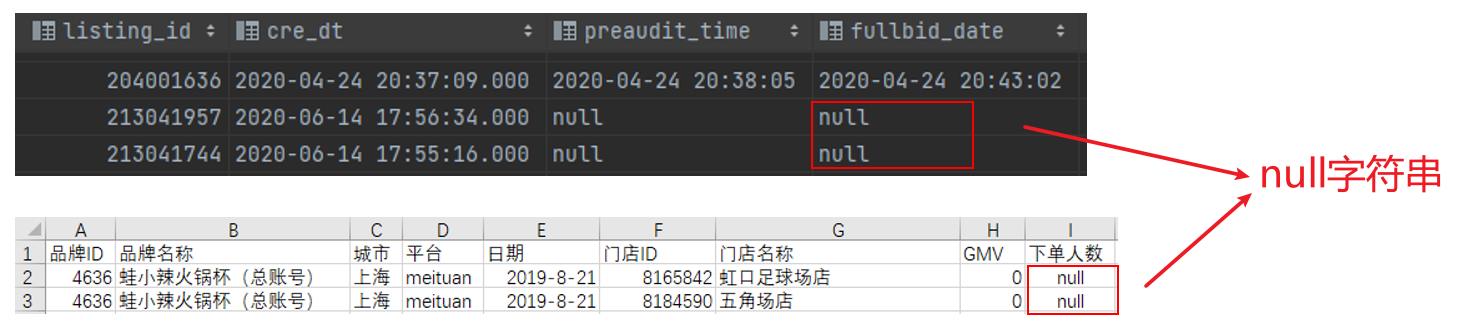
其中' is null ',用于查询空值(NULL),空值不同于0,也不同于null字符串
- 空值

- null字符串
【模糊查询like】

【多条件查询】
and且 or或 and的优先级大于or
补充:
u.pay_method IS NULL 和 u.pay_method 是空字符串不一样吗?
u.pay_method IS NULL 和 u.pay_method = ''(或 u.pay_method <> '' 中所涉及的空字符串判断)不一样,它们代表了不同的情况,下面从概念、判断方式和实际应用等方面进行详细解释:
概念区别
u.pay_method IS NULL:NULL在 SQL 里表示 “未知” 或 “缺失的值”,意味着该字段没有被赋予任何值。它并不是一个具体的值,而是一种特殊的状态,表示数据的缺失。u.pay_method = '':这里的''代表空字符串,是一个明确的值,即该字段被赋予了一个长度为 0 的字符串。u.pay_method <> ''是一个条件表达式,用于筛选出pay_method字段的值不为空字符串的记录。<>:这是 SQL 中的比较运算符,意思是 “不等于”。不同的数据库系统可能有不同的表示方式,例如在某些数据库中也可以用!=来表示 “不等于”。'':表示空字符串。
主知识点三:ORDER BY
SELECT 字段名
FROM 表名
[WHERE 表达式]
[ORDER BY 字段名 ASC/DESC] 对被查询出的结果集,指定依据字段排序 asc升序 desc降序 不写则默认升序排序 是可选项
主知识点四:LIMIT
SELECT 字段名
FROM 表名
[WHERE 表达式]
[ORDER BY 字段名 ASC/DESC]
[LIMIT [位置偏移量] 行数] 限制查询结果集显示的行数,是可选项,行数是子句中的必选参数,参数位置偏移量是可选参数
【查询结果返回前n行】
SELECT 字段名
FROM 表名
[WHERE 表达式]
[ORDER BY 字段名 ASC/DESC]
[LIMIT n]
【查询结果返回第x + 1行开始的 n 行到 x + n 行】
SELECT 字段名
FROM 表名
[WHERE 表达式]
[ORDER BY 字段名 ASC/DESC]
[LIMIT x, n]
主知识点五:聚合函数 & GROUP BY
标准语法:
SELECT 字段名
FROM 表名
[WHERE 表达式]
[GROUP BY 字段名1] 是可选项,使用该子句可依据相同字段值分组后进行聚合运算,常和聚合函数连用
[ORDER BY 字段名 ASC/DESC]
[LIMIT [位置偏移量] 行数]
-
【聚合函数】
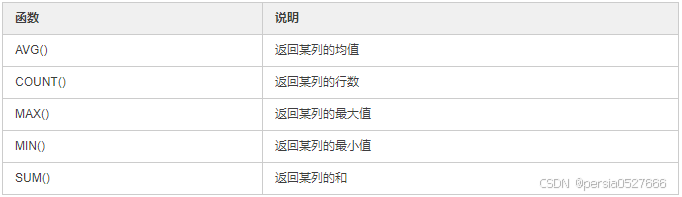
聚合函数适用于需要获取数据的汇总信息,例如某字段行数,某字段平均值,某字段中最大最小数等
-
【GROUP BY 单独使用】
可以实现单独对字段continent进行去重的效果
world(name, continent, area, population, gdp)
SELECT continent
FROM world
GROUP BY continent;注明:对于continent中的每一组,由于 SELECT 子句中没有使用聚合函数(如 COUNT、SUM、AVG 等),数据库只会从每组中选取一个 continent 值作为结果,从而实现了去重的效果
但是如果有使用聚合函数,是不去重的, 如果这里是COUNT(continent) 那么会显示每个大洲出现的次数总和,如果要输出大洲数需要添加DISTINCT :COUNT( DISTINCT continent)
-
【聚合函数和GROUP BY联用1】
[例题24] 查询每个大洲(continent)和大洲内的国家(name)数量
SELECT continent, COUNT(name)
FROM world
GROUP BY continent-
【聚合函数和GROUP BY联用2】
nobel( yr, subject, winner)
[例题25] 查询2013至2015年每年每个科目的获奖人数,结果按年份从大到小,人数从大到小排序
SELECT yr, subject, COUNT(winner)
FROM nobel
WHERE yr between 2013 and 2015
GROUP BY yr, subject
ORDER BY yr DESC, COUNT(winner) DESC使用GROUP BY子句时,SELECT只能使用GROUP BY 和 聚合函数引用过字段
GROUP BY中的字段要考虑窗口函数和所有查询语段中的PARTITION BY ORDER BY字段
主知识点六:HAVING & 简单运行原理
标准语法:
SELECT 字段名
FROM 表名
[WHERE 表达式]
[GROUP BY 字段名1]
[HAVING 表达式] 是可选项,限定分组聚合后(即group by分组后)的查询行进行筛选
[ORDER BY 字段名 ASC/DESC]
[LIMIT [位置偏移量] 行数]
只有使用了 GROUP BY 子句后才会使用HAVING子句,HAVING子句不能脱离GROUP BY 子句单独使用,因为HAVING子句本质上是对GROUP BY分组的筛选
HAVING的表达式和WHERE的表达式基本相同,但是HAVING的表达式中可以使用聚合函数,WHERE的表达式中不可以,因为WHERE是对原表的行数据进行筛选,HAVING是对GROUP BY 分组后的数据进行筛选
主知识点七:部分常见函数
【数学函数】
1. round(x, y)——四舍五入函数
- round函数对x值进行四舍五入,精确到小数点后y位
- y为负值时,保留小数点左边相应的位数为0,不进行四舍五入
- 例如:round(3.15,1)返回3.2,round(14.15,-1)返回10
2.TRUNCATE(x,y)截断函数,只保留小数x的y位小数
TRUNCATE(3.1415926, 3)返回3.141
3. 取整函数
- CEILING 函数向上取整,返回大于或等于输入值的最小整数CEILING(3.14)返回4
- FLOOR 函数向下取整,返回小于或等于输入值的最大整数FLOOR(3.14)返回3
【字符串函数】
1. concat(s1,s2,...)——连接字符串函数
- concat函数返回连接参数s1、s2等产生的字符串
- 任一参数为null时,则返回null
- 例如:concat('My',' ','SQL')返回My SQL,concat('My',null,'SQL')返回null
2. replace(s,s1,s2)——替换函数
- replace函数使用字符串s2代替s中所有的s1
- 例如:replace('MySQLMySQL','SQL','sql')返回MysqlMysql
3. left(s,n)——从左截取字符串一部分的函数
- 返回字符串s最左边n个字符
4. right(s,n)——从右截取字符串一部分的函数
- 返回字符串s最右边n个字符
5. substring(s,n,len)——从指定位置截取字符串一部分的函数
- 返回字符串s从第n个字符起取长度为len的子字符串,n也可以为负值,则从倒数第n个字符起取长度为len的子字符串,没有len值则取从第n个字符起到最后一位
- 例如:left('abcdefg',3)返回abc,right('abcdefg',3)返回efg,substring('abcdefg',2,3)返回bcd,substring('abcdefg',-2,3)返回fg,substring('abcdefg',2)返回bcdefg
6. UPPER() 全取大写字母
【数据类型转换函数】
1. cast(x as type)——转换数据类型的函数
- cast函数将一个类型的x值转换为另一个类型的值
- type参数可以填写char(n)、date、time、datetime、decimal等转换为对应的数据类型
【日期时间函数】
1. year(date)——获取年的函数
2. month(date)——获取月的函数
3. day(date)——获取日的函数
- year('2021-08-03')返回2021,month('2021-08-03')返回8,day('2021-08-03')返回3
- 注意
YEAR()和MONTH()这类日期提取函数,需要传入标准的日期类型值才能正常发挥作用,而像2025-01这种格式并非标准日期类型,直接使用这些函数处理它会出现问题。
CURDATE() 函数主要用于返回当前系统日期,通常以 YYYY-MM-DD 格式输出。该函数无需传入参数,调用时直接使用函数名即可
4. date_add(date,interval expr type)——对指定起始时间进行加操作
5. date_sub(date,interval expr type)——对指定起始时间进行减操作
- 例如:date_add('2021-08-03 23:59:59',interval 1 second)返回2021-08-04 24:00:00,date_sub('2021-08-03 23:59:59',interval 2 month)返回2021-06-03 23:59:59
6. datediff(date1,date2)——计算两个日期之间间隔的天数
- datediff函数由date1-date2计算出间隔的时间,只有date的日期部分参与计算,时间不参与
- 例如:datediff('2021-06-08','2021-06-01')返回7,datediff('2021-06-08 23:59:59','2021-06-01 21:00:00')返回7,datediff('2021-06-01','2021-06-08')返回-7
7.TIMESTAMPDIFF(unit, start_datetime, end_datetime)
unit可以是SECOND、MINUTE、HOUR、DAY等,表示时间差的单位。这里我们使用SECOND计算秒数差,然后通过一系列的数学运算和字符串拼接得到时分秒格式。
8. date_format(date,format)——将日期和时间格式化
根据format指定的格式显示date值
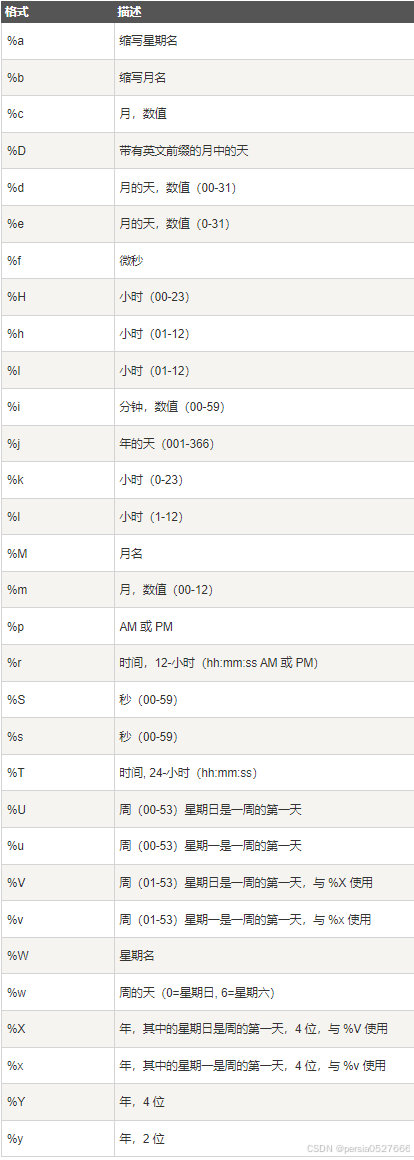
例如:
- date_format('2018-06-01 16:23:12','%b %d %Y %h:%i %p')返回Jun 01 2018 04:23 PM
- date_format('2018-06-01 16:23:12','%Y/%d/%m')返回2018/01/06
【条件判断函数】——根据满足不同条件,执行相应流程
1. if(expr,v1,v2)
- 如果表达式expr是true返回值v1,否则返回v2
- 例如:if(1<2,'Y','N')返回Y,if(1>2,'Y','N')返回N
在 MySQL 中可以使用 IFNULL 函数替代 if 函数,代码可能会写成
sum(IFNULL(order_price, 0)) as
即如果order_price列中有空值即替换成0
2. case when
case expr when v1 then r1 [when v2 then r2] ...[else rn]
end
case 2
when 1
then 'one'
when 2
then 'two'
else 'more'
end
/返回twocase when v1 then r1 [when v2 then r2]...[else rn]
end
case
when 1<0
then 'T'
else 'F'
end
/返回F【高级语句】
主知识点八:窗口函数(从原来的表中提出一个新的临时表)
partition by指定分区依据,order by指定排序依据
【排序窗口函数语法】
- rank()over([partition by 字段名] order by 字段名 asc|desc)
跳跃式排序——若数值为99,99,90,89 则排名1,1,3,4
- dense_rank()over([partition by 字段名] order by 字段名 asc|desc)
并列连续性排序——若数值为99,99,90,89 则排名1,1,2,3
- row_number()over([partition by 字段名] order by 字段名 asc|desc)
连续性排序——若数值为99,99,90,89 则排名1,2,3,4
若数值不重复则这三个函数可以通用
[例题29] 查询每一年S14000021选区中所有候选人所在的团体(party)和得票数(votes),并对每一年中的所有候选人根据选票数的高低赋予名次,选票数最高则为1,第二名则为2,后续以此类推,最后根据团体(party)和年份(yr)排序
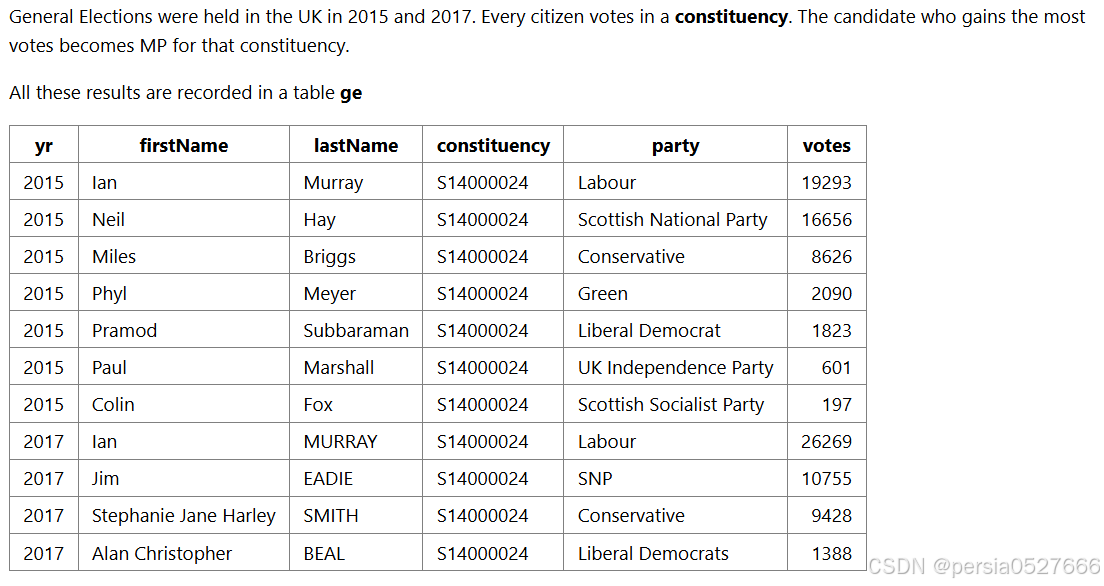
SELECT
yr,
party,
votes,
RANK() OVER (PARTITION BY yr ORDER BY votes DESC) AS posn
FROM
ge
WHERE
constituency = 'S14000021'
ORDER BY
party,
yr;【偏移分析函数语法】
- lag(字段名,偏移量[,默认值])over([partition by 字段名] order by 字段名 asc|desc)
用于在查询结果集中访问当前行之前的某一行的数据。
- lead(字段名,偏移量[,默认值])over([partition by 字段名] order by 字段名 asc|desc)
LEAD() 函数与 LAG() 函数相反,它用于访问当前行之后的某一行的数据。
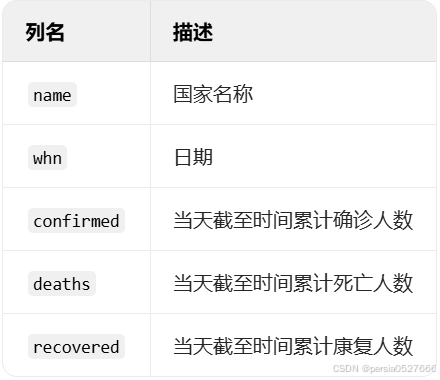
[例题] You can filter the data to view only Monday's figures WHERE WEEKDAY(whn) = 0.
Show the number of new cases in Italy for each week in 2020 - show Monday only.
SELECT
name,
DATE_FORMAT(whn, '%Y-%m-%d') AS date,
(confirmed - LAG(confirmed, 1) OVER (PARTITION BY name ORDER BY whn)) AS New
FROM
covid
WHERE
name = 'Italy'
AND WEEKDAY(whn) = 0
ORDER BY
whn;- 在 MySQL 中,
WEEKDAY()函数用于返回日期对应的星期索引。这个索引是从 0 开始的,其中 0 代表星期一,1 代表星期二,依此类推,6 代表星期日。
注:
- 窗口函数只能写在SELECT子句中
- 窗口函数中的partition by 子句可以指定数据的分区,和GROUP BY 要去重分组不同的是,PARTITION BY只分区不去重
- 窗口函数中没有PARTITION BY 子句是,即不对数据分区,直接整个表为一个区
- 排序窗口函数中ORDER BY 子句是必选项,窗口函数中ORDER BY 子句在分区内依据指定字段和排序方法对数据进行行排序
另外还有其他的窗口函数如SUM()用于求累计和,FIRST_VALUE()和LAST_VALUE(),用于获取数据集中的第一个或最后一个值,PERCENT_RANK()计算当前行在结果集中的百分比排名,排名范围从 0 到 1。
主知识点九:表连接
【JOIN】 列连接
【内连接】(连不上的不保留)
select 字段名
from 表名1
inner join 表名2
on 表名1.字段名 = 表名2.字段名
注意内连接inner可以省略,直接使用join默认为内连接
【左连接】(保留左边表格内容)
select 字段名
from 表名1
left join 表名2
on 表名1.字段名 = 表名2.字段名
【右连接】(保留右边表格内容)
select 字段名
from 表名1
right join 表名2
on 表名1.字段名 = 表名2.字段名
左连接和右连接统称外连接(OUTER JOIN)
【UNION】行连接
join---连接表,对列操作
union--连接表,对行操作。
union--将两个表做行拼接,同时自动删除重复的行。
union all---将两个表做行拼接,保留重复的行。
- 使用union组合查询时,只能使用一条order by字句,他必须位于最后一条select语句之后,因为对于结果集不存在对于一部分数据进行排序,而另一部分用另一种排序规则的情况。
[例题]
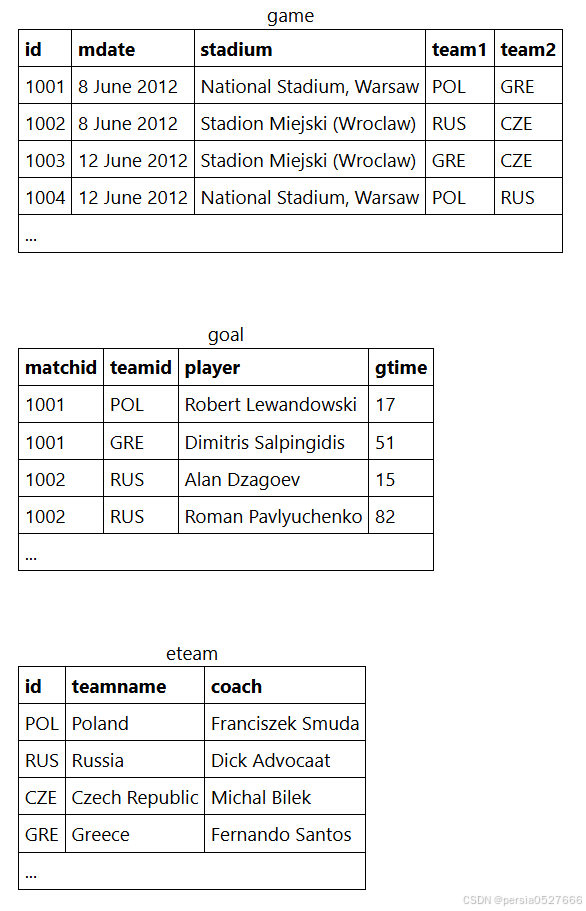
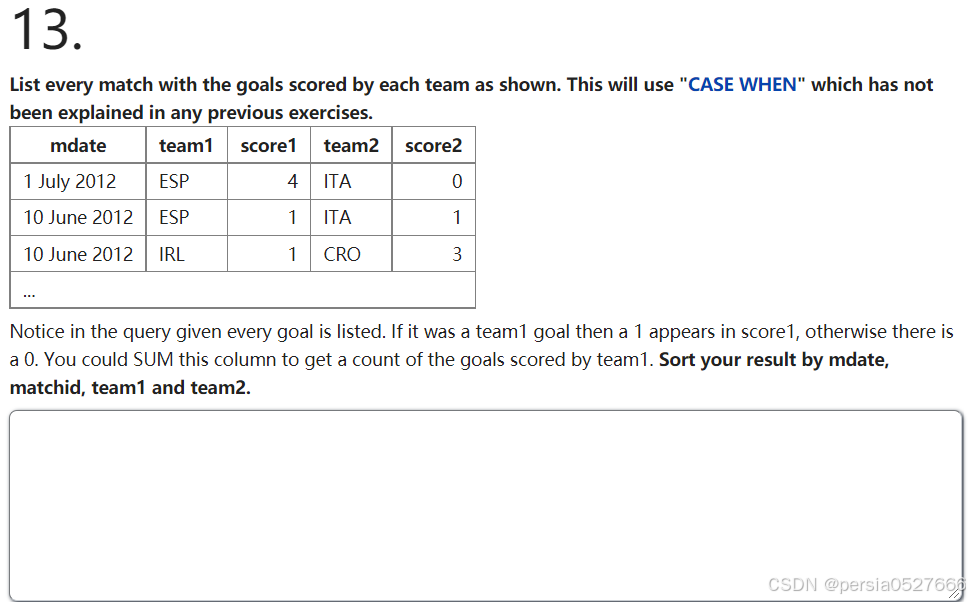
SELECT
ga.mdate,
ga.team1,
SUM(CASE WHEN ga.team1 = go.teamid THEN 1 ELSE 0 END) AS score1,
ga.team2,
SUM(CASE WHEN ga.team2 = go.teamid THEN 1 ELSE 0 END) AS score2
FROM
game ga
LEFT JOIN
goal go ON ga.id = go.matchid
GROUP BY
ga.mdate, ga.team1, ga.team2
ORDER BY
ga.mdate, go.matchid, ga.team1, ga.team2;主知识点十:子查询
- 子查询本身就是一段完整的查询语句,然后用括号英文括号()包裹嵌套在主查询语句中,子查询可以多层嵌套
- 最常用的子查询运用在from和where子句中
[例题] 查询德国和意大利每天新增治愈人数并从高到低排名,查询结果按国家名,截至日期(输出格式为'xxxx年xx月xx日'),新增治愈人数,按排名排序
select
name,
日期,
lrecovered,
rank() over(partition by name order by lrecovered desc) 排名
from
(
select name,
date_format(whn,'%Y年%m月%d日') 日期,
recovered-lag(recovered,1)over(partition by name order by whn) lrecovered
from covid
where name in ('Germany','Italy')
order by lrecovered desc
) re
order by 排名;
















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









