










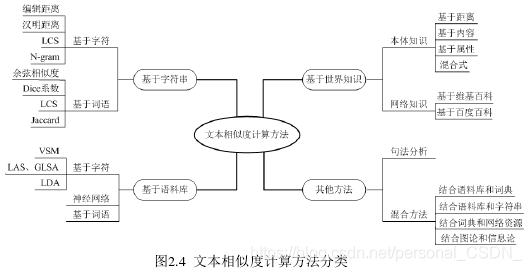
1 引言
文本自动摘要是利用计算机通过各种方法对文本或文本集中能够准确反映原文中心内容的重要信息进行抽取、总结。信息的快速增长使得人们面临信息过载的困扰,面对海量信息往往无法从中快速准确地获取所需信息,而文本自动摘要技术能有效地解决此类问题,利用它可以帮助人们快速有效地从网络上获取高质量的所需信息。目前的文本自动摘要技术生成的摘要质量还有所欠缺,因而如何有效地利用自动文摘技术提取文本摘要是本文的主要研究内容。
针对TextRank算法在自动提取中文文本摘要时忽略了词语间的语义相关信息及文本的重要全局信息的问题,提出了SW-TextRank算法。通过Word2Vec训练的词向量来计算句子之间的相似度,并综合考虑句子位置、句子与标题的相似度、关键词的覆盖率、关键句子以及线索词等影响句子权重的因素,从而优化句子权重;对得到的候选摘要句群进行冗余处理,选取适量排序靠前的句子并根据其在原文中的顺序重新排列得到最终的文本摘要,最后通过实验进行验证。
2 文本摘要相关技术介绍
2.1 文本向量化表示
- 词袋模型
BOW只考虑文本中所有词的权重,忽略了文本中词间的上下文关系,而权重与词在文本中出现的频率有关,所以基于BOW对文本向量化时需要统计文本中词出现的次数。 - 词频逆词频模型(TF-IDF)
词频逆词频模型(TF-IDF)的出现主要是为了解决BOW仅考虑了词频而忽略了词的重要性的问题。TF-IDF是基于统计来评估文本中词对于语料库中的一份文本的重要程度的方法。
TF-IDF使得文本内的高频率词语及其在整个文件集合中的低频率文件可以得到高权重的TF-IDF。在TF-IDF中,词语的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降,这从侧面反映TF-IDF倾向于保留重要的词语,过滤掉常见的词语。 - 浅语义分析模型
LSA的基本原理是通过对大量文本集进行统计分析,从中提取词语的上下文语义利用奇异值分解来实现映射,这样可以消除同义词、多义词的影响,从而进一步提高文本向量化的准确度。其处理流程可以划分为四步:首先,分析文本集构建文本矩阵,接着对文本矩阵进行奇异值分解,然后对奇异值分解后的文本矩阵进行降维处理,最后基于降维后的矩阵建立潜在语义空间。
4… 神经网络语言模型
NNLM基于语言模型,将优化模型的过程转换为实现更优词向量表示的过程。基于神经网络语言模型生成的词向量可以自定义维度,且维度不会受到新扩展词的影响,生成的词向量也可以很好的根据特征距离度量词与词之间的相似性。基于低维紧凑的词向量表示,NNLM解决了BOW文本向量化时存在的数据稀疏、语义鸿沟等问题;在上下文语境相似的情况下,NNLM也可以很好地预测出相似的目标词,这是传统文本向量化模型无法做到。 - Word2Vec模型
Word2Vec通过训练模型便捷地将给定的语料库中的所有词语表达成向量形式,其主要有CBOW和Skip-gram 两种训练模型。CBOW模型使用上下文信息来预测当前词语的概率,而Skip-gram模型反转了目标和上下文信息的使用,则是使用当前词语预测上下文信息的概率。
对比上述的五种词向量表示模型,Word2vec模型存在一定优势,其不仅简单易于实现,而且通过Word2Vec模型训练的词向量可以准确地区分每个词语之间的语义关系。因而,本文采用Word2Vec模型来训练的词向量。
2.2 文本相似度计算
TextRank文本网络图中,词语之间的相似度可以通过两个词语在空间模型中的余弦相似度衡量,其计算方法公式如下:
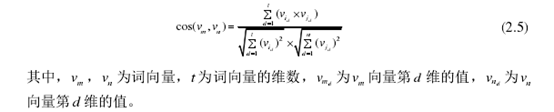
计算两句子相似度时,先要分别计算出每个句子中词语相似度的均值,然后将得到的均值求和再取均数,从而得到两句子的相似度,则句子相似度的计算公式公示如下所示。本文采用先求和再取均数的方法计算句子中词语相似度的均值,以此来规避长句子相似度过高的情形。

图中各节点权重可按照如下公式计算:

2.3 TextRank算法
TextRank算法是一种基于图排序的无监督方法,它起源于Google公司的PageRank算法,被广泛应用于文本自动摘要和关键词生成领域。PageRank算法基于网页链接的数量和质量来衡量网页的重要程度,鉴于此,TextRank算法将所要获取摘要的文本拆分成句子作为文本网络图中的节点,句子间的相似度用节点间的相似度来表示,从而构建基于句子结构关系的文本网络图。通过对文本网络图的迭代计算可以实现对文本中句子重要性进行排序,筛选出几个最重要的句子作为文本的摘要。
2.4 自动文摘评价方法
- 人工评价
- 自动评价
自动评价的方式中,通常分为两大类:内部评价标准(Intrinsic Methods)和外部评价标准(Extrinsic Methods)。在实际应用中大多采用内部评价标准,使用内部评价标准时需要借助标准摘要来进行参考,将模型自动生成的文本摘要与标准摘要进行不同粒度上的对比,越吻合则越表明文本摘要的生成质量高。外部评价标准则会将生成的摘要投入到实际的某项任务中,依据生成摘要对这项任务完成度的贡献大小来考量其生成质量。
3 基于SW-TextRank的文本自动化摘要方法
通过Word2Vec训练的词向量来计算句子之间的相似度,并综合考虑句子位置、句子与标题的相似度、关键词的覆盖率、关键句子以及线索词等影响句子权重的因素,从而优化句子权重;对得到的候选摘要句群进行冗余处理,选取适量排序靠前的句子并根据其在原文中的顺序重新排列得到最终的文本摘要,最后通过实验进行验证。
3.1 句子相似度计算优化
每个句子都是由一个个词语组合而成的,因此句子相似度的计算可以归结为句中词语相似度的计算。词语之间的相似度可以通过两个词语在空间模型中的余弦相似度衡量,其计算式如下。
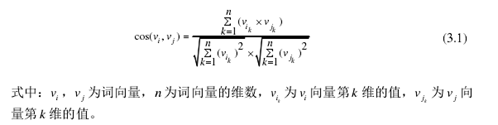
当两个句子中相似的词语越多时其相似度越高,完全相同时其相似度为1。
本文通过计算句子中词语相似度的平均值来计算句子的相似度。计算两句子相似度时,先要分别计算出每个句子中词语相似度的均值,然后将得到的均值求和再取均数,从而得到两句子的相似度,则句子相似度的计算公式表示为

3.2 句子权重计算优化
目前TextRank算法在句子权重计算的准确度方面尚有较大的提升空间,SW.TextRank综合考虑文本中句子的位置、句子与标题的相似度、关键词的覆盖率、关键句子以及线索词等因素,由于这些因素对句子权重的准确计算都能起到很大的影响,从而优化句子权重计算。
1) 句子位置

2) 标题的相似度
标题是标明文章的简短语句,它反映了文章的主旨和主要内容。文章中句子与标题的相似度越高,则句子越贴近文章的主旨,其重要程度越高,应给予该句子更高的权重。

3) 关键词的覆盖率
关键词可以表达文章的主题内容,越多的关键词出现在句子中,则该句子的重要程度就越高。

4) 关键句子
在中文文章中,自成一段的一个句子往往在文章中起着承上启下或过渡的作用。文章中包含时间、地点、人物的句子,以及可能存在一些自成一段的小标题。这些通常具有高概括性、精炼性的关键句子比一般句子更符合摘要本身的要求,被提取为摘要的可能性更大。本文对此类句子给予更高的权重,其计算式表示为
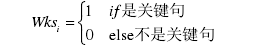
5) 线索词
线索词是指“综上所述”、“总而言之”、“总之”、“总的来说”等概括性的指示词语,包含线索词的句子通常是对文章或者段落的总结,则此类句子的重要程度更高。对于包含线索词的句子应给予更高的权重,其权重计算式表示为

为了平衡各部分权重影响因子所占的比重,为每部分引入了权重系数。该权重系数由两部分组成:归一化系数和加权系数,计算式表示
其中a是对各部分权重进行归一化后得到的系数,B是根据实验分析,调优后的加权系数。
综合考虑各部分权重影响因子,从而构建最终的句子权重计算公式:
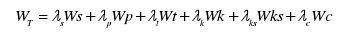
式中:入为各部分权重影响因子的权重系数,Ws为句子相似度,W,为句子最终的权重值。权重系数大小表示其对应的权重影响因子对句子权重的影响力大小,权重系数越大则影响力越大,反之亦然。其取值均在0-1之间,且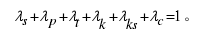
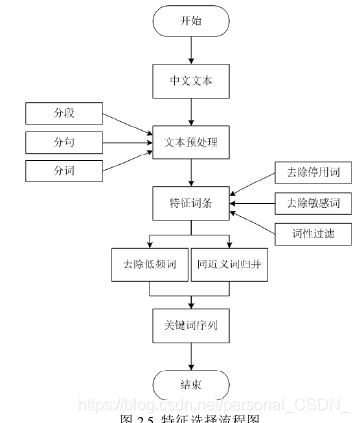
3.3 改进算法实现
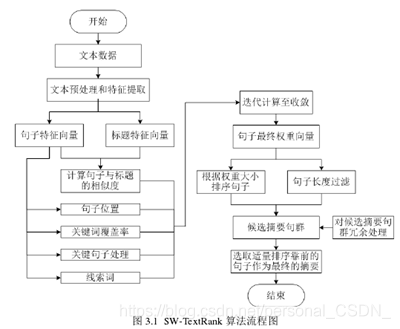
SW-TextRank算法的实现过程如表3.1所示。


SW-TextRank算法的流程图如图3.1所示。
4 实验结果与分析
4.1 实验数据与评价标准
本文选取当前最新的中文维基百科数据作为提供学习训练的文本数据集,先对数据集进行清洗,过滤掉其中无用的内容,使用目前最好的Python中文分词组件——jieba进行分词,然后基于Word2Vec中的CBOW模型对该文本数据集进行训练从而得到实验所需的词向量模型文件,其中维度大小设置为200,窗口大小为默认值5。从采集自新浪微博的中文数据集LCSTS的第三部分中随机选取100篇短文本(评分为5)作为本文的测试文本数据集。
本文采用Rouge指标来对算法生成的摘要进行评估,Rouge基于摘要中n元词的共现信息来评价摘要,是一种面向n元词召回率的自动摘要评价方法。其基本思想是将算法自动生成的摘要与测试数据集的标准摘要进行对比,通过统计二者之间重叠的基本单元的数量来评价摘要的质量。本文选取Rouge-1、Rouge-2、Rouge-L三种评价指标来评价算法生成摘要的质量.
4.2 实验结果与分析
本文选取Rouge-1、Rouge-2、Rouge-L三种评价指标来合理地评价自动摘要的质量,并计算出影响句子权重的各个影响因子的加权系数。综合考虑所有加权系数
设置不同的加权系数组合并进行大量实验,本文选取了具有代表性的9组参数组合如表3.2所示,针对每种组合计算其生成文本摘要的质量,实验结果如图3.2所示。
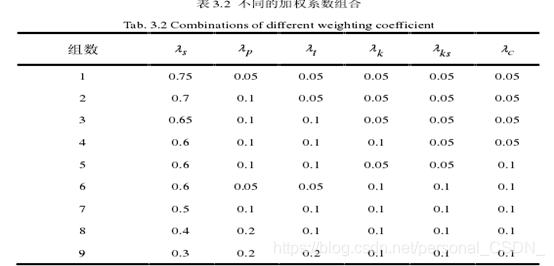
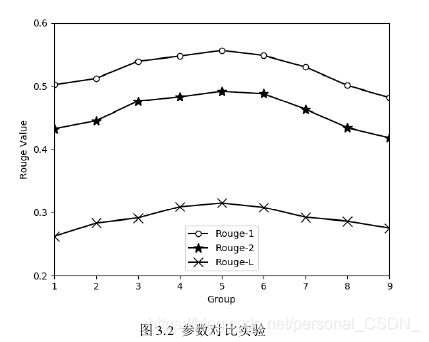
从图3.2中可以看出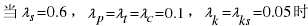
生成摘要质量最好。
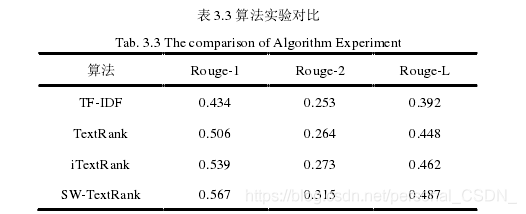
对比表3.3中的实验数据可知,本文提出的SW-TextRank算法在Rouge-1、Rouge-2和Rouge-L三种评价指标上均有明显的提高,SW-TextRank算法生成摘要的质量更好。整体而言:TF-IDF算法生成的摘要效果最差,改进算法iTextRank
相对于TF-IDF和TextRank有一定的优势,SW-TextRank算法在整体上都明显优于其余的三种算法,实验结果表明根据中文文本的特点,综合考虑文本中句子位置、句子与标题的相似度、关键词的覆盖率、关键句子以及线索词等影响句子权重的因素,并把它们应用到摘要的提取过程中,可以明显提高生成摘要的质量。
5 总结
本章针对目前TextRank算法自动提取中文文本摘要的效果不佳,提出了SW-TextRank算法。该算法融合Word2Vec模型和TextRank算法,综合考虑文本中句子的位置、句子与标题的相似度、关键词的覆盖率、关键句子以及线索词等因素对句子权重的影响,结合次模函数方法来保证摘要多样性和覆盖度,并且对得到的候选摘要句群进行冗余处理,使得生成的摘要更具简明性和概括性。最后通过实验验证了SW-TextRank算法生成摘要的准确性比TextRank算法更高,摘要生成质量更好。














 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









