







RNN神经网络
1 RNN概念介绍
(1) 序列建模问题,如:语音问题,股票问题;
(2) RNN网络的记忆性,如:需要知道数据的当前状态,以及根据历史数据预测将来数据;
(3) 可利用任意长的序列信息(理论上);
(4) 存在梯度消失的问题,在实际中,只回溯利用与他接近的time steps上的信息。
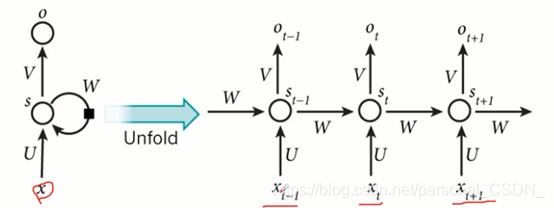
2 RNN VS CNN
(1) RNN 的假设—事物的发展是按照时间序列展开的,即前一时刻发生的事物会对未来的事物发展产生影响。
(2) CNN 的假设—人类的视觉总会关注视线内特征最明显的点,而CNN网络是模仿人类处理信息的过程。
(3) RNN具有记忆能力:上一时刻隐层的状态参与到了这个时刻的计算过程中。
(4) RNN主要用于序列问题的建模。
3 RNN应用场景
(1) 语音识别
(2) OCR识别
(3) 文本分类
(4) 序列标注
(5) 音乐发生器
(6) 情感分类
(7) DNA序列分析
(8) 机器翻译
(9) 视频动作识别
(10) 命名实体识别



4 常见的RNN结构
4.1 simple RNNS原理介绍
·举个例子
在一个订票系统上,我们的输入"Arrive Beijing on November 2nd"这样一个序列,希望算法能够将关键词‘Beijing’放入目的地
再次输入"Leave Beijing on November 2nd"希望将”Beijing”放在出发地
我们就希望能够让神经网络拥有“记忆”的能力,能够根据之前的信息(在这个例子中是Arrive或Leave)从而得到不同的输出
存在的问题:
1) 梯度消失
2) 梯度爆炸
3) constant error carrousel(cec)
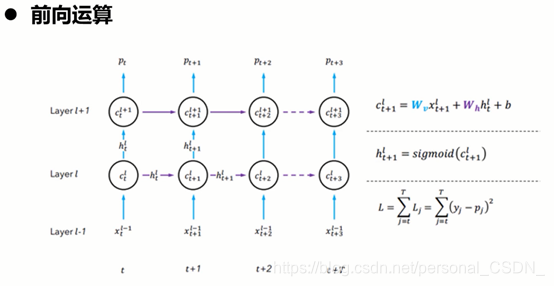

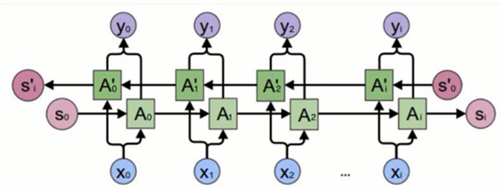
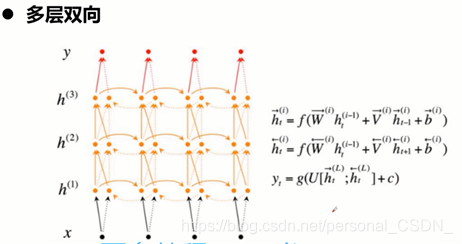
4.2 Bidirectional RNNs原理介绍
1)假设当前的输出不仅仅和之前的序列有关,而且还与之后的序列有关。
2)两个simple RNNS叠加在一起。

4.3 LSTM原理介绍
LSTM 是为了避免长依赖问题而精心设计的:
1) 记住较长的历史信息实际上是他们的默认行为,而不是他们努力学习的东西;
2) 一种特殊的RNN模型;
3) 为了解决RNN模型梯度弥散提出的
在传统的RNN中,训练算法使用的是BPTT, 当时间较长时,需要回传的残差会指数下降,导致网络权重更新缓慢,无法体现出RNN的长期记忆效果,因此需要一个存储单元来存储记忆。
在标准的RNN中该重复模块将具有非常简单的结构,例如:单个tanh层。
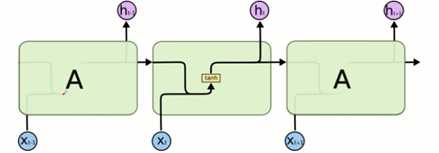
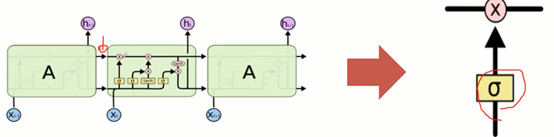
LSTM不同与单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
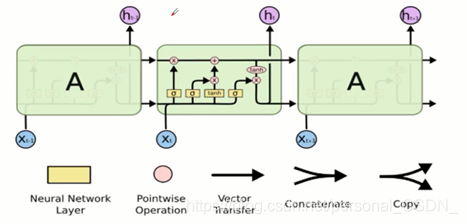
门结构(LSTM拥有三个门,来保护和控制细胞状态)
1) 去除或者增加信息到细胞状态的能力
2) 门是一种让信息选择式通过的方法,sigmoid+pointwise
- 忘记门
决定我们会从细胞状态中丢弃什么信息
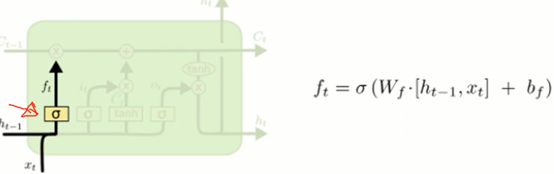
- 输入层门
确定什么样的新信息被存放在细胞状态中
Sigmoid决定备更新的值,tanh层创建一个新的候选值向量加入状态中。
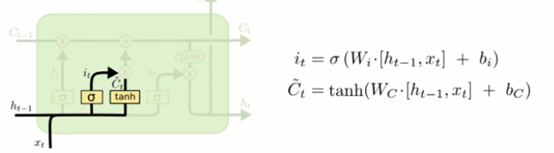
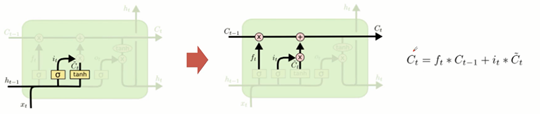
确定更新信息。
- 输出层门
我们需要确定输出什么值,这个输出将会给予我们的细胞状态,但是也是一个过滤后的版本。

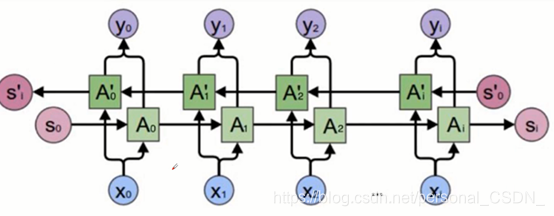
4.4 Bi-LSTM 原理介绍
4.5 LSTM网络结构变种

5 序列任务中的Attention机制
平常使用传统编码器-解码器的RNN模型
先用一些LSTM单元来对输入序列进行学习,编码为固定长度的向量表示;
再使用一些LSTM单元来读取这种向量表示并解码为输出序列。
对于序列到序列的任务,存在两个非常致命的问题就是:
输入序列不管长短都会被编码成一个固定长度的向量表示;但由于不同的时间片或者空间位置的信息量明显有差异,利用定长表示则会带来误差的损失。
当输入序列较长时,模型的性能就会变得很差。
两个问题的解决方式:
1) Attention机制则通过对输入信息进行选择性学习,来建立序列间的关联;
2) 这非常适合序列到序列间的任务,比如:机器翻译,自动问答,语音识别等;
3) Seq2seq+Attention模型
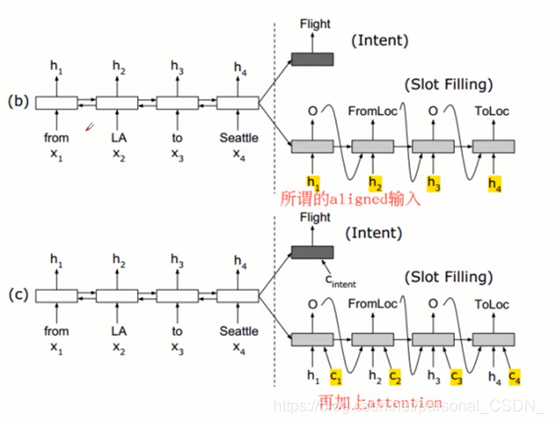
Seq2seq 模型
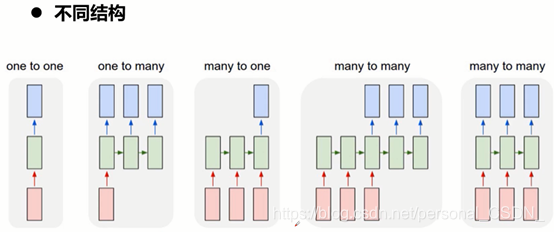
1) 从输入到输出,存在多种不同的RNN结构
2) Seq2seq实际就是many to many模型的一种
3) 从一个序列到另外一个的转换,
4) 翻译功能,聊天机器人对话模型等不同场景
5) Encoder—Decoder结构先将输入数据编码成一个上下文向量c
6) 可以将编码的最后一个隐藏态赋值给c,还可以对最后的隐藏态做一个变换得到c,也可以对所有的隐藏态做变换。
7) 另一个RNN网络对c进行解码,这部分RNN网络被称为Decoder.

8)将c当做每一步的输入

9)在每个时间输入不同的c来解决这个问题
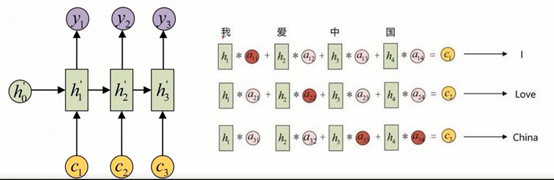
Seq2seq+Attention模型的应用领域
·机器翻译:Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出。
·文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列。
·阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
·语音识别:输入是语音信号序列,输出是文字序列。
·OCR识别:输入是图像数据,输出是识别后的单词或者句子
6 transformer
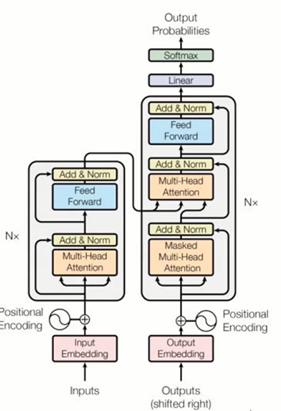
google提出《Attention is all you need》
·用全attention的结构代替了lstm
两个sub-layer组成
multi-head self-attention mechanism
fully connected feed-forward
network
residual connection&normalization
优点:
1) 计算复杂度降低
2) 并行计算
3) 计算一个序列长度为N的信息要经过的路径长度只需要一步矩阵计算
Cnn需要增加卷积层数,来扩大视野
Rnn需要从1到n逐个进行计算,所以也可以看出,self-attention可以比rnn更好的解决长时依赖问题
缺点:
实践上:有些rmn轻易可以解决的问题transformer没做到,比如复制string,或者推理时碰到的sequence长度比训练时更长(因为碰到了没见过的position embedding)
理论上:transformers非computationally universal(图灵完备)
7 BERT
·语言模型:通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示
使用了Transformer作为算法的主要框架,能更彻底的捕捉语句中的双向关系;
使用了Mask Language Model(MLM)和Next Sentence Prediction(NSP)的多任务训练目标;
使用更强大的机器训练更大规模的数据,使BERT的结果达到了全新的高度
Google开源了BERT模型,用户可以直接使用BERT作为Word2Vec的转换矩阵并高效的将其应用到自己的任务中。
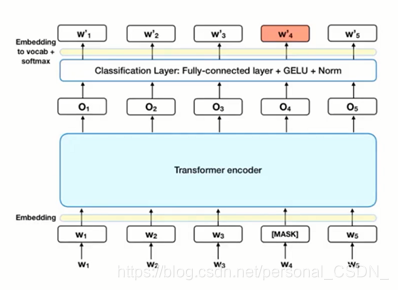
·Mask Language Model(MLM)
在将单词序列输入给BERT之前,每个序列中有15%的单词被[MASK]token替换。然后模型尝试基于序列中其他未被mask的单词的上下文来预测被掩盖的原单词。
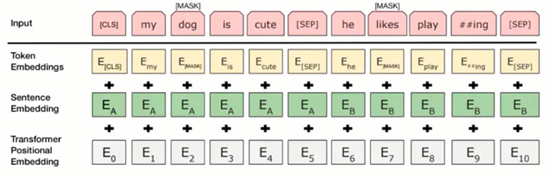
·Next Sentence Prediction(NSP)
模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。
在训练期间,50%的输入对在原始文档中是前后关系,另外50%中是从语料库中随机组成的,并且是与第一句断开的。
·Mask Language Model(MLM)+Next Sentence Prediction(NSP)
8 NLP基础概念
8.1 语言模型
·从机器学习的角度来看:语言模型是对语句的概率分布的建模
·标准定义:对于语言序列(w1,w2,w3…),语言模型就是计算该序列的概率,即P(w1,w2,w3.….)
统计语言模型(n-gram)
基于前馈神经网络的模型
基于循环神经网络的模型
8.1.1 n-gram
马尔可夫假设(Markov assumption),即假设当前词出现的概率只依赖于前n-1个词(共现词频)
给定一个序列的前提下,预测下一个词出现的概率
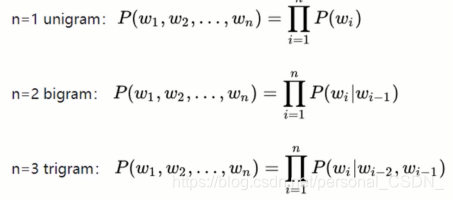
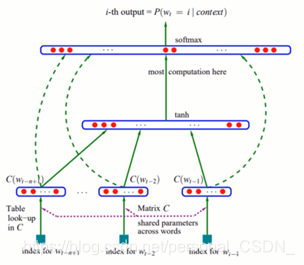
8.1.2 基于前馈神经网络模型
Bengio 在03年的这篇经典《A Neural Probabilistic Language Model》中,提出了如下图所示的前馈神经网络结构:
利用神经网络去建模当前词出现的概率与其前n-1个词之间的约束关系
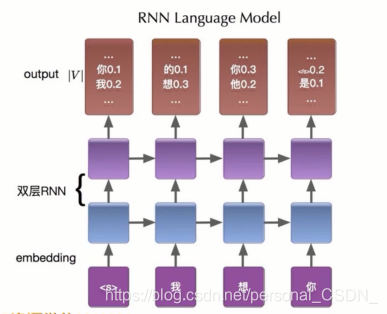
8.1.3 基于循环神经网络模型
为了解决定长信息的问题,Mikolov 于2010年发表的论文Recurrent neural network based language model正式揭开了循环神经网络(RNN)
在语言模型中的强大历程
预测当前序列的下一个词
8.2 语言模型评价
采用相对熵(relative entropy)来衡量两个分布之间的相近程度
困惑度(perplexity))
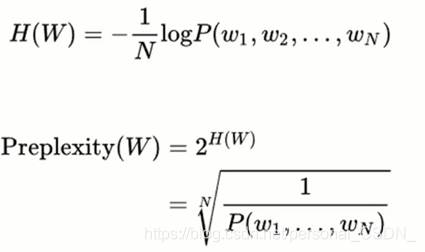
8.3 NLP研究方向和领域
·语言模型
·自动文摘与信息抽取
·自动分词
·机器翻译,问答系统
·词法分析句法分析
·信息检索,搜索引擎
·文本分类,情感分析
·等等
9 其他基础概念
词向量:将自然语言中的词符号数学化,[0.1,0.2,0.5.…]
中文分词
词性标注:词汇基本的语法属性
句法分析&语法分析(主从关系,主谓宾关系等等)等等














 3602
3602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









