







由于课程需要和工具限制,需要在mac上安装Hadoop,参考了网上的教程,总结了用terminal安装Hadoop3.2.1以及运行第一个Wordcount程序的过程。这里默认mac的terminal已经安装了homebrew软件管理工具、JDK环境,如果没安装homebrew、JDK环境的小伙伴请自行搜索mac终端安装homebrew、JDK教程。下面是安装Hadoop的具体流程,分三步:
一、设置ssh免密码登录
因为Hadoop是分布式平台,需要多个机器之间协作,设置ssh免密码登录可以减少每次登陆主机输入密码的繁琐流程。
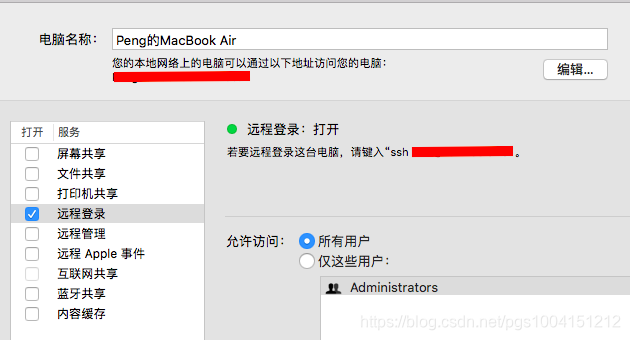
1)在mac的系统偏好设置-->共享中打开远程登录:
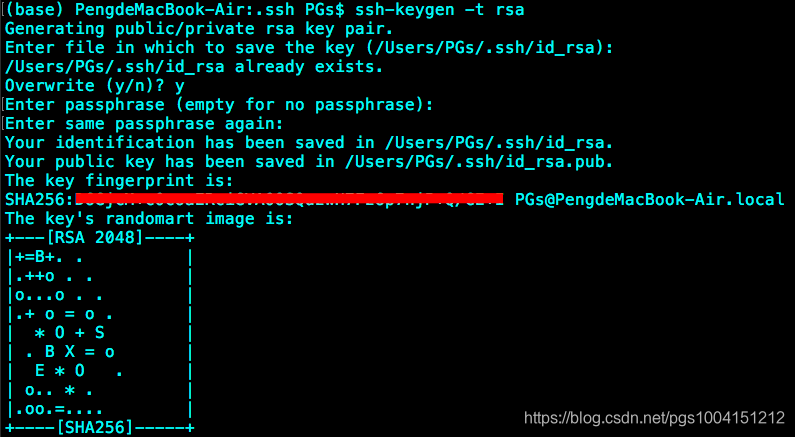
2)在terminal中输入 ssh-keygen -t rsa -P ,生成rsa公钥,接下来一路按回车键或者y就行了:
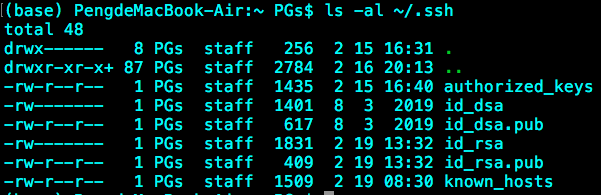
注释(大佬可以直接跳过):RSA和MD5是常用的加密算法,生成的RSA公钥和私钥放在了~/.ssh路径下面,id_rsa是私钥文件,id_rsa.pub是公钥文件,用cat命令可以查看文件里面的具体内容。
3)在terminal中输入 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ,将公钥的内容写入到authorized_keys文件中。
4)在terminal中输入 ssh localhost ,不需要密码也能登录,说明设置成功。

二、用brew下载Hadoop,并进行配置
1)在terminal中输入brew install hadoop,下载Hadoop:
注意:由于用homebrew下载软件时,它会默认先更新自己的软件包,而有时候更新会非常慢,甚至更换镜像源也不行。这时可以按一次组合键command+c先中断这次更新,然后开始直接下载Hadoop。具体参见https://learnku.com/articles/18908这篇文章。下载完成后,出现以下提示,说明安装成功:
🍺 /usr/l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4766
4766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









