







深度学习读书笔记之RBM
声明:
1)看到其他博客如@zouxy09都有个声明,老衲也抄袭一下这个东西
2)该博文是整理自网上很大牛和机器学习专家所无私奉献的资料的。具体引用的资料请看参考文献。具体的版本声明也参考原文献。
3)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应,更有些部分本来就是直接从其他博客复制过来的。如果某部分不小心侵犯了大家的利益,还望海涵,并联系老衲删除或修改,直到相关人士满意为止。
4)本人才疏学浅,整理总结的时候难免出错,还望各位前辈不吝指正,谢谢。
5)阅读本文需要机器学习、统计学、神经网络等等基础(如果没有也没关系了,没有就看看,当做跟同学们吹牛的本钱)。
6)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。请直接回帖,本人来想办法处理。
7)由于本人第一次发博客,连编辑工具都不会用,很多公式就走样了,只好截图,格式实在不堪入目,各位前辈有会用发帖工具的可以指点一下。
8)本人手上有word版的和pdf版的,不知道怎么上传,所以需要的话可以直接到DeepLearning高质量交流群里要,群号由于未取得群主同意不敢公布,需要的同学可以联系群主@tornadomeet
前言
本文较长,请注意要耐心读。
如果实在不愿意耐心读,起码看完红色标志的句子,不然还得很多问题不清楚。
本文组织的结构比较散,下面是大体过程:
RBM使用方法-->一般用途-->用能量模型的原因-->为什么要概率以及概率的定义-->求解目标和极大似然的关系-->怎么求解-->其他的一些补充
一.限制波尔兹曼机
1.1限制波尔兹曼机(RBM)使用方法
1.1.1 RBM的使用说明
一个普通的RBM网络结构如下。
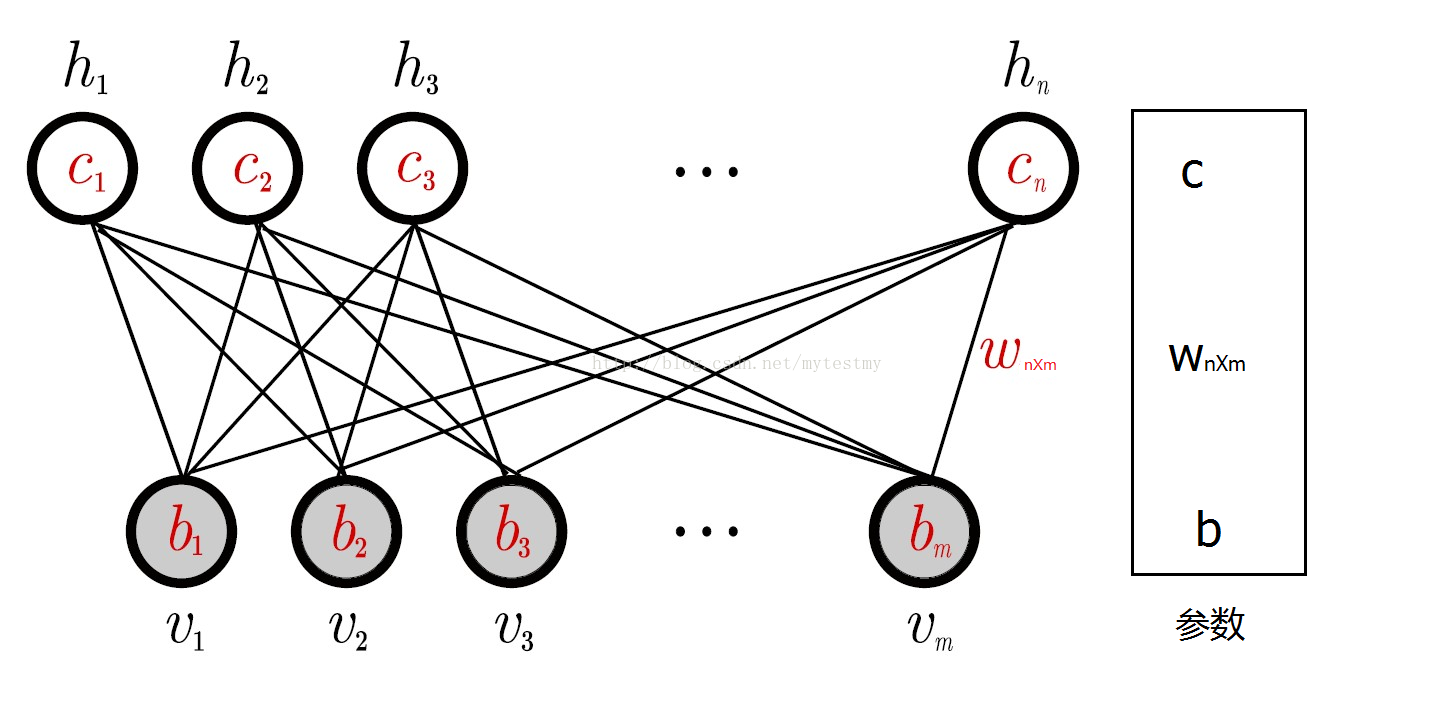
以上的RBM网络结构有m个可视节点和n个隐藏节点,其中每个可视节点只和n个隐藏节点相关,和其他可视节点是独立的,就是这个可视节点的状态只受n个隐藏节点的影响,对于每个隐藏节点也是,只受n个可视节点的影响,这个特点使得RBM的训练变得容易了。

对于(ii)的说明:不说别的——比如吧,你现在出去逛街,走到一个岔路口,你只想随便逛逛,所以你是有0.5的概率往左边的路,0.5的概率往右边的路;但是你不知道怎么选择哪个路,所以你选择了抛硬币,正面朝上你就向左,反面朝上就向右。现在你只抛一次,发现他是正面朝上的,你就向左走了。
——回到上面的问题,某节点A取值为1的概率是0.6(假如),也可以看做一个找不均匀的硬币,正面朝上的概率是0.6,反面朝上的概率是0.4;现在要给节点A取值,就拿这个硬币抛一下,正面朝上就取值1,反面朝上就取值0,这个就相当于抛硬币决定走哪个路的那个过程。
——现在假如找不到这样的不均匀的硬币,就拿随机数生成器来代替(生成的数是0-1之间的浮点数);因为随机数生成器取值小于0.6的概率也是0.6,大于0.6的概率是0.4。
1.1.2 RBM的用途
RBM的用途主要是两种,一是对数据进行编码,然后交给监督学习方法去进行分类或回归,二是得到了权重矩阵和偏移量,供BP神经网络初始化训练。
第一种可以说是把它当做一个降维的方法来使用。
第二种就用途比较奇怪。其中的原因就是神经网络也是要训练一个权重矩阵和偏移量,但是如果直接用BP神经网络,初始值选得不好的话,往往会陷入局部极小值。根据实际应用结果表明,直接把RBM训练得到的权重矩阵和偏移量作为BP神经网络初始值,得到的结果会非常地好。
这就类似爬山,如果一个风景点里面有很多个山峰,如果让你随便选个山就爬,希望你能爬上最高那个山的山顶,但是你的精力是有限的,只能爬一座山,而你也不知道哪座山最高,这样,你就很容易爬到一座不是最高的山上。但是,如果用直升机把你送到最高的那个山上的靠近山顶处,那你就能很容易地爬上最高的那座山。这个时候,RBM就的角色就是那个直升机。
其实还有两种用途的,下面说说。
第三种,RBM可以估计联合概率p(v,h),如果把v当做训练样本,h当成类别标签(隐藏节点只有一个的情况,能得到一个隐藏节点取值为1的概率),就可以利用利用贝叶斯公式求p(h|v),然后就可以进行分类,类似朴素贝叶斯、LDA、HMM。说得专业点,RBM可以作为一个生成模型(Generative model)使用。
第四种,RBM可以直接计算条件概率p(h|v),如果把v当做训练样本,h当成类别标签(隐藏节点只有一个的情况,能得到一个隐藏节点取值为1的概率),RBM就可以用来进行分类。说得专业点,RBM可以作为一个判别模型(Discriminative model)使用。
1.2限制波尔兹曼机(RBM)能量模型
1.2.1 能量模型定义
在说RBM之前,先来说点其他的,就是能量模型。
能量模型是个什么样的东西呢?直观上的理解就是,把一个表面粗糙又不太圆的小球,放到一个表面也比较粗糙的碗里,就随便往里面一扔,看看小球停在碗的哪个地方。一般来说停在碗底的可能性比较大,停在靠近碗底的其他地方也可能,甚至运气好还会停在碗口附近(这个碗是比较浅的一个碗);能量模型把小球停在哪个地方定义为一种状态,每种状态都对应着一个能量,这个能量由能量函数来定义,小球处在某种状态的概率(如停在碗底的概率跟停在碗口的概率当然不一样)可以通过这种状态下小球具有的能量来定义(换个说法,如小球停在了碗口附近,这是一种状态,这个状态对应着一个能量E,而发生“小球停在碗口附近”这种状态的概率p,可以用E来表示,表示成p=f(E),其中f是能量函数),这就是我认为的能量模型。
这样,就有了能量函数,概率之类的东西。
波尔兹曼网络是一种随机网络。描述一个随机网络,总结起来主要有两点。
第一,概率分布函数。由于网络节点的取值状态是随机的,从贝叶斯网的观点来看,要描述整个网络,需要用三种概率分布来描述系统。即联合概率分布,边缘概率分布和条件概率分布。要搞清楚这三种不同的概率分布,是理解随机网络的关键,这里向大家推荐的书籍是张连文所著的《贝叶斯网引论》。很多文献上说受限波尔兹曼是一个无向图,从贝叶斯网的观点看,受限波尔兹曼网络也可以看作一个双向的有向图,即从输入层节点可以计算隐层节点取某一种状态值的概率,反之亦然。
第二,能量函数。随机神经网络是根植于统计力学的。受统计力学中能量泛函的启发,引入了能量函数。能量函数是描述整个系统状态的一种测度。系统越有序或者概率分布越集中,系统的能量越小。反之,系统越无序或者概率分布越趋于均匀分布,则系统的能量越大。能量函数的最小值,对应于系统的最稳定状态。
1.2.2 能量模型作用
为什么要弄这个能量模型呢?原因有几个。
第一、RBM网络是一种无监督学习的方法,无监督学习的目的是最大可能的拟合输入数据,所以学习RBM网络的目的是让RBM网络最大可能地拟合输入数据。
第二、对于一组输入数据来说,现在还不知道它符合那个分布,那是非常难学的。例如,知道它符合高斯分布,那就可以写出似然函数,然后求解,就能求出这个是一个什么样个高斯分布;但是要是不知道它符合一个什么分布,那可是连似然函数都没法写的,问题都没有,根本就无从下手。
好在天无绝人之路——统计力学的结论表明,任何概率分布都可以转变成基于能量的模型,而且很多的分布都可以利用能量模型的特有的性质和学习过程,有些甚至从能量模型中找到了通用的学习方法。有这样一个好东西,当然要用了。
第三、在马尔科夫随机场(MRF)中能量模型主要扮演着两个作用:一、全局解的度量(目标函数);二、能量最小时的解(各种变量对应的配置)为目标解。也就是能量模型能为无监督学习方法提供两个东西:a)目标函数;b)目标解。
换句话说,就是——使用能量模型使得学习一个数据的分布变得容易可行了。
能否把最优解嵌入到能量函数中至关重要,决定着我们具体问题求解的好坏。统计模式识别主要工作之一就是捕获变量之间的相关性,同样能量模型也要捕获变量之间的相关性,变量之间的相关程度决定了能量的高低。把变量的相关关系用图表示出来,并引入概率测度方式就构成了概率图模型的能量模型。
RBM作为一种概率图模型,引入了概率就可以使用采样技术求解,在CD(contrastive divergence)算法中采样部分扮演着模拟求解梯度的角色。
能量模型需要一个定义能量函数,RBM的能量函数的定义如下
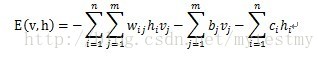
这个能量函数的意思就是,每个可视节点和隐藏节点之间的连接结构都有一个能量,通俗来说就是可视节点的每一组取值和隐藏节点的每一组取值都有一个能量,如果可视节点的一组取值(也就是一个训练样本的值)为(1,0,1,0,1,0),隐藏节点的一组取值(也就是这个训练样本编码后的值)为(1,0,1),然后分别代入上面的公式,就能得到这个连接结构之间的能量。
能量函数的意义是有一个解释的,叫做专家乘积系统(POE,product of expert),这个理论也是hinton发明的,他把每个隐藏节点看做一个“专家”,每个“专家”都能对可视节点的状态分布产生影响,可能单个“专家”对可视节点的状态分布不够强,但是所有的“专家”的观察结果连乘起来就够强了。具体我也看不太懂,各位有兴趣看hinton的论文吧,中文的也有,叫《专家乘积系统的原理及应用,孙征,李宁》。
另外的一个问题是:为什么要搞概率呢?下面就是解释。
能量模型需要两个东西,一个是能量函数,另一个是概率,有了概率才能跟要求解的问题联合起来。
下面就介绍从能量模型到概率吧。
1.3从能量模型到概率
1.3.1 从能量函数到概率
为了引入概率,需要定义概率分布。根据能量模型,有了能量函数,就可以定义一个可视节点和隐藏节点的联合概率
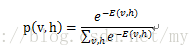
也就是一个可视节点的一组取值(一个状态)和一个隐藏节点的一组取值(一个状态)发生的概率p(v,h)是由能量函数来定义的。
这个概率不是随便定义的,而是有统计热力学的解释的——在统计热力学上,当系统和它周围的环境处于热平衡时,一个基本的结果是状态i发生的概率如下面的公式
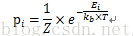
其中表示系统在状态i时的能量,T为开尔文绝对温度,为Boltzmann常数,Z为与状态无关的常数。
我们这里的变成了E(v,h),因为(v,h)也是一个状态,其他的参数T和由于跟求解无关,就都设置为1了,Z就是我们上面联合概率分布的分母,这个分母是为了让我们的概率的和为1,这样才能保证p(v,h)是一个概率。
现在我们得到了一个概率,其实也得到了一个分布,其实这个分布还有一个好听点的名字,可以叫做Gibbs分布,当然不是一个标准的Gibbs分布,而是一个特殊的Gibbs分布,这个分布是有一组参数的,就是能量函数的那几个参数w,b,c。
有了这个联合概率,就可以得到一些条件概率,是用积分去掉一些不想要的量得到的。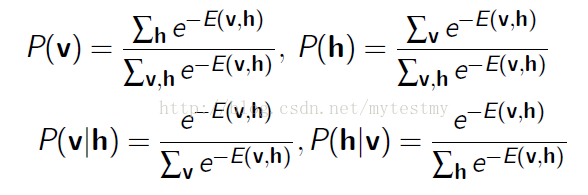
1.3.2 从概率到极大似然
上面得到了一个样本和其对应编码的联合概率,也就是得到了RBM网络的Gibbs分布的概率密度函数,引入能量模型的目的是为了方便求解的。
现在回到求解的目标——让RBM网络的表示Gibbs分布最大可能的拟合输入数据。
其实求解的目标也可以认为是让RBM网络表示的Gibbs分布与输入样本的分布尽可能地接近。
现在看看“最大可能的拟合输入数据”这怎么定义。
假设Ω表示样本空间,q是输入样本的分布,即q(x)表示训练样本x的概率, q其实就是要拟合的那个样本表示分布的概率;再假设p是RBM网络表示的Gibbs分布的边缘分布(只跟可视节点有关,隐藏节点是通过积分去掉了,可以理解为可视节点的各个状态的分布),输入样本的集合是S,那现在就可以定义样本表示的分布和RBM网络表示的边缘分布的KL距离
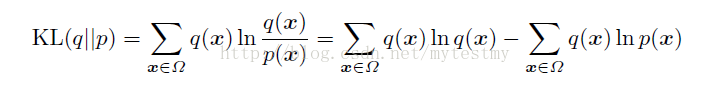
如果输入样本表示的分布与RBM表示的Gibbs分布完全符合,这个KL距离就是0,否则就是一个大于0的数。
第一项其实就是输入样本的熵(熵的定义),输入样本定了熵就定了;第二项没法直接求,但是如果用蒙特卡罗抽样(后面有章节会介绍),让抽中的样本是输入样本(输入样本肯定符合分布q(x)),第二项可以用
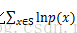
结论就是求解输入样本的极大似然,就能让RBM网络表示的Gibbs分布和样本本身表示的分布最接近。
这就是为什么RBM问题最终可以转化为极大似然来求解。
既然要用极大似然来求解,这个当然是有意义的——当RBM网络训练完成后,如果让这个RBM网络随机发生若干次状态(当然一个状态是由(v,h)组成的),这若干次状态中,可视节点部分(就是v)出现训练样本的概率要最大。
这样就保证了,在反编码(从隐藏节点到可视节点的编码过程)过程中,能使训练样本出现的概率最大,也就是使得反编码的误差尽最大的可能最小。
例如一个样本(1,0,1,0,1)编码到(0,1,1),那么,(0,1,1)从隐藏节点反编码到可视节点的时候也要大概率地编码到(1,0,1,0,1)。
到这,能量模型到极大似然的关系说清楚了,,可能有点不太对,大家看到有什么不对的提一下,我把它改了。
之前想过用似然函数最大的时候,RBM网络的能量最小这种思路去解释,结果看了很多的资料,都实在没有办法把那两个极值联系起来。这个冤枉路走了好久,希望大家在学习的时候多注意,尽量避免走这个路。
下面就说怎么求解了。求解的意思就是求RBM网络里面的几个参数w,b,c的值,这个就是解,而似然函数(对数似然函数)是目标函数。最优化问题里面的最优解和目标函数的关系大家务必先弄清楚。
1.4求解极大似然
既然是求解极大似然,就要对似然函数求最大值,
求解的过程就是对参数就导,然后用梯度上升法不断地把目标函数提升,最终到达停机条件(在这里看不懂的同学就去看参考文献中的《从极大似然到EM》),
设参数为(注意是参数是一组参数),则似然函数可以写为
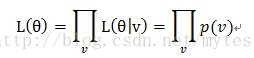
然后就可以对它的对数进行求导了(因为直接求一个连乘的导数太复杂,所以变成对数来求)
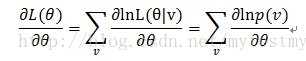
可以看到,是对每个p(v)求导后再加和,然后就有了下面的推导了。
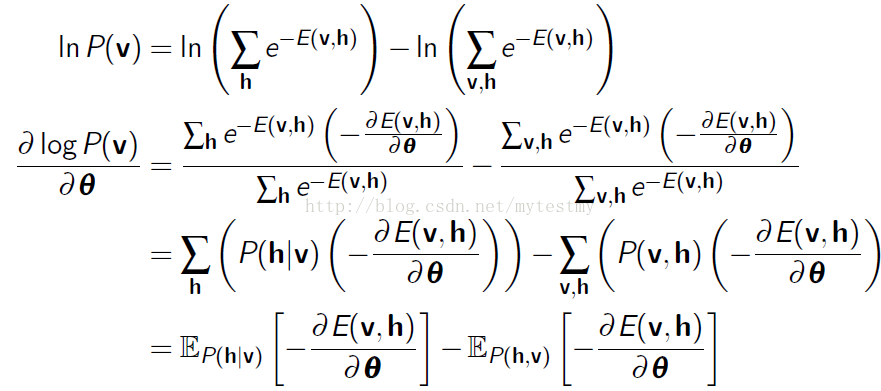

还有论文是这么解释的,上面的公式,对w求偏导,还可以再进一步转化
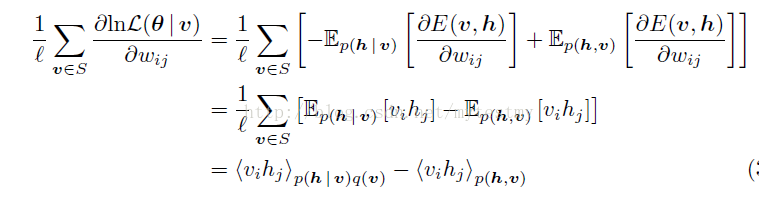
注意:从第二个“=”号到第三个“=”号的时候,第二个“=”号的方括号里面的第一项是把蒙特卡罗抽样的用法反过来了,从抽样回到了积分,所以得到了一个期望;第二项就是因为对每个训练样本,第二项的值算出来都一样,所以累加以后的结果除以l,相当于没有变化,还是那个期望,只是表达的形式换了。
这样的话,这个梯度还可以这么理解,第一项等于输入样本数据的自由能量函数偏导在样本本身的那个分布下的期望值(q(v,h)=p(h|v)q(v),q表示输入样本和他们对应的隐藏增状态表示的分布),而第二项是自由能量函数的偏导在RBM网络表示的Gibbs分布下的期望值。
第一项是可以求的,因为训练样本有了,也就是使用蒙特卡罗估算期望的时候需要的样本已经抽好了,只要求个均值就可以了。
第二项也是可以求的,但是要对v和h的组合的所有可能的取值都遍历一趟,这就可能没法算了;想偷懒的话,悲剧就在于,现在是没有RBM网络表示的Gibbs分布下的样本的(当然后面会介绍这些怎么抽)。
为了进行下面的讨论,把这个梯度再进一步化简,看看能得到什么。根据能量函数的公式,是有三个参数的w,b和c,就分别对这三个参数求导
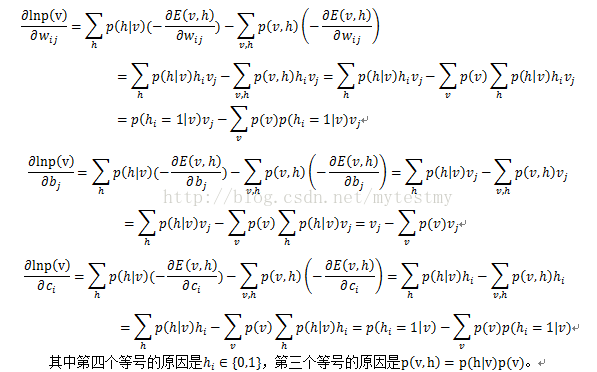
到了这一步,来分析一下,从上面的联合概率那一堆,我们可以得到下面的
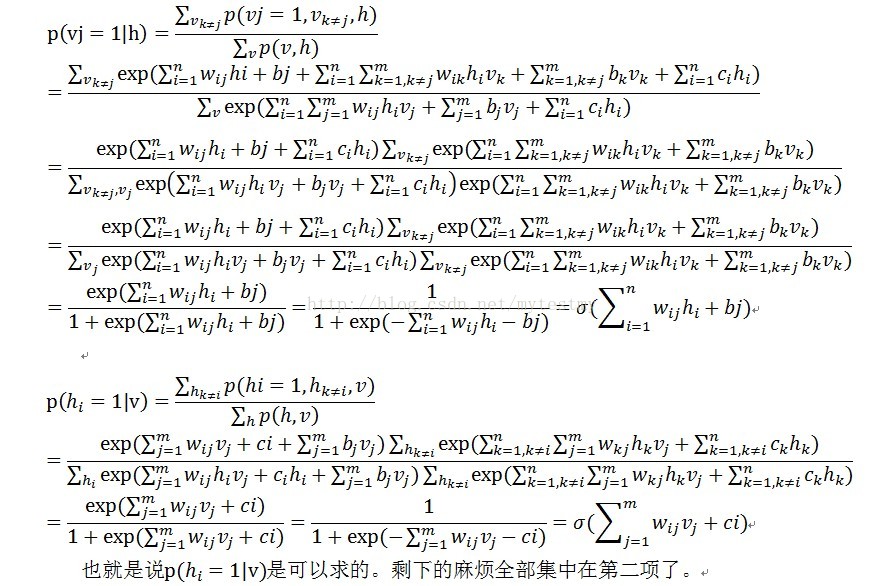
要求第二项,就要遍历所有可能的v的值,然后根据公式去计算几个梯度的值,那样够麻烦的了,还好蒙特卡罗给出了一个偷懒的方法,见后面的章。
只要抽取一堆样本,这些样本符合RBM网络表示的Gibbs分布的(也就是符合参数确定的Gibbs分布p(x)的),就可以把上面的三个偏导数估算出来。
对于上面的情况,是这么处理的,对每个训练样本x,都用某种抽样方法抽取一个它对应的符合RBM网络表示的Gibbs分布的样本(对应的意思就是符合参数确定的Gibbs分布p(x)的),假如叫y;那么,对于整个的训练集{x1,x2,…xl}来说,就得到了一组符合RBM网络表示的Gibbs分布的样本{y1,y2,…,yl},然后拿这组样本去估算第二项,那么梯度就可以用下面的公式来近似了
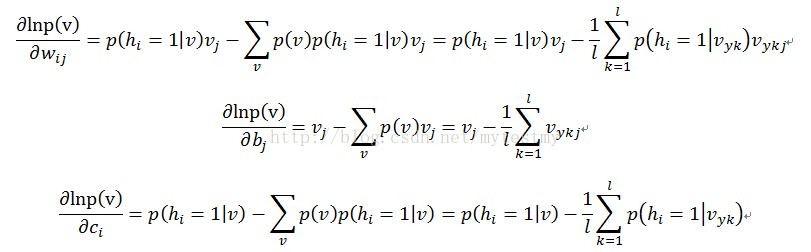
这样,梯度出来了,这个极大似然问题可以解了,最终经过若干论迭代,就能得到那几个参数w,b,c的解。
式子中的v是指{x1,x2,…xl}中的一个样本,因为,对样本进行累加时,第一项是对所有样本进行累加,而第二项都是一样的(是一个积分的结果,与被积变量无关,是一个标量),所以累加后1/l就没有了,只有对l项y进行累加,到了下面CD-k算法的时候,每次只对一个x和一个y进行处理,最外层对x做L次循环后得到的累加结果是一样的.
上面提到的“某种抽样方法”,现在一般就用Gibbs抽样,然后hinton教授还根据这个弄出了一个CD-k算法,就是用来解决RBM的抽样的。下面一章就介绍这个吧。
1.5用到的抽样方法
一般来说,在hinton教授还没弄出CD-k之前,解决RBM的抽样问题是用Gibbs抽样的。
Gibbs抽样是一种基于马尔科夫蒙特卡罗(Markov Chain Monte Carlo,MCMC)策略的抽样方法。具体就是,对于一个d维的随机向量x=(x1,x2,…xd),假设我们无法求得x的联合概率分布p(x),但我们知道给定x的其他分量是,其第i个分量xi的条件分布,即p(xi|xi-),xi-=(x1,x2,…xi-1,xi+1…xd)。那么,我们可以从x的一个任意状态(如(x1(0),x2(0),…,xd(0)))开始,利用条件分布p(xi|xi-),迭代地对这状态的每个分量进行抽样,随着抽样次数n的增加,随机变量(x1(n),x2(n),…,xd(n))的概率分布将以n的几何级数的速度收敛与x的联合概率分布p(v)。
Gibbs抽样其实就是可以让我们可以在位置联合概率分布p(v)的情况下对其进行抽样。
基于RBM模型的对称结构,以及其中节点的条件独立行,我们可以使用Gibbs抽样方法得到服从RBM定义的分布的随机样本。在RBM中进行k步Gibbs抽样的具体算法为:用一个训练样本(或者可视节点的一个随机初始状态)初始化可视节点的状态v0,交替进行下面的抽样:
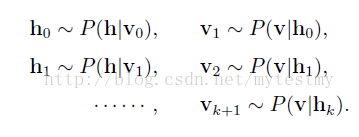
在抽样步数n足够大的情况下,就可以得到RBM所定义的分布的样本(即符合参数确定的Gibbs分布的样本)了,得到这些样本我们就可以拿去计算梯度的第二项了。
可以看到,上面进行了k步的抽样,这个k一般还要比较大,所以是比较费时间的,尤其是在训练样本的特征数比较多(可视节点数大)的时候,所以hinton教授就弄一个简化的版本,叫做CD-k,也就对比散度。
对比散度是英文ContrastiveDivergence(CD)的中文翻译。与Gibbs抽样不同,hinton教授指出当使用训练样本初始化v0的时候,仅需要较少的抽样步数(一般就一步)就可以得到足够好的近似了。
在CD算法一开始,可见单元的状态就被设置为一个训练样本,并用上面的几个条件概率来对隐藏节点的每个单元都从{0,1}中抽取到相应的值,然后再利用 来对可视节点的每个单元都从{0,1}中抽取相应的值,这样就得到了v1了,一般v1就够了,就可以拿来估算梯度了。
下面给出RBM的基于CD-k的快速学习的主要步骤。

其中,之所以第二项没有了那个1/l,就是因为这个梯度会对所有样本进行累加(极大似然是所有训练样本的梯度的和),最终加和的结果跟现在这样算是相等的(刚好是l个样本,l个第二项相加后,最终结果刚好等于每一个第二项的那个累加符号后面的那一项,而这里所有结果加和后,也能得到相同的值)。
1.6马尔科夫蒙特卡罗简介
下面简介一下马尔科夫蒙特卡罗(MCMC)方法。

然后剩下的就是怎么样能够采样到符合分布p(x)的样本了,这个简单来说就是一个随机的初始样本,通过马尔科夫链进行多次转移,最终就能得到符合分布p(x)的样本。上面介绍的Gibbs是一种比较常用的抽样算法。
有关Gibbs抽样的相关内容可以参看文献【12】。
致谢
Deep Learning高质量交流群里的多位同学:@zeonsunlight,@marvin,@tornadomeet,@好久不见,@zouxy09
他们在我写这个笔记的过程中提供了多方面的资料。
特别是:@ zeonsunlight,帮助我弄清楚了很多概念;@好久不见,帮我改正了博客中的符号的错误。
本人愚钝,多数问题都需要各位同学的多次点拨,在此向他们表示衷心的感谢。
这个笔记的其他方面介绍,我觉得都算清楚,唯独在说能量模型的时候,感觉是没把能量模型介绍清楚,有懂的前辈希望能指导一下。
最后,还是得说,本人才疏学浅,肯定有大量的错误,希望大家能多多包涵并且指出,让我能及时改正。
参考文献
[1] An Introduction to Restricted Boltzmann Machines.Asja Fischer andChristian Igel
[2] 受限波尔兹曼机简介 张春霞,姬楠楠,王冠伟
[3] LearningDeep Architectures for AI Yoshua Bengio
[4] http://blog.csdn.net/cuoqu/article/details/8886971 DeepLearning(深度学习)原理与实现(一)@marvin521
[5] http://blog.csdn.net/zouxy09/article/details/8775360 Deep Learning(深度学习)学习笔记整理系列 @zouxy09
[6] http://www.cnblogs.com/tornadomeet/archive/2013/03/27/2984725.html Deep learning:十九(RBM简单理解) @tornadomeet
[7] http://blog.csdn.net/celerychen2009/article/details/8984316 受限波尔兹曼机 @celerychen2009
[8] http://blog.csdn.net/zouxy09/article/details/8537620 从最大似然到EM算法浅解 @zouxy09
[9] http://www.sigvc.org/bbs/thread-513-1-3.html 《RBM 和DBN 的训练》 王颖
[10] 神经网络原理叶[M] 叶世伟,史忠植:机械工业出版社
[11] http://www.sigvc.org/bbs/thread-512-1-1.html 《Restricted BoltzmannMachine (RBM) 推导》朱飞云
[12] http://www.52nlp.cn/lda-math-mcmc-%E5%92%8C-gibbs-sampling1gibbs抽样相关















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









