






一、优化函数 - 随机梯度下降在深度学习中的应用——小批量随机梯度下降
- 模型参数初始化——如随机选择
- 随机均匀采样小批量样本
- 用小样本训练平均损失函数,同时求梯度(求偏导)
- 用梯度结果*学习率与模型参数相减得到新的参数
- ( w , b ) ← ( w , b ) − η ∣ B ∣ ∑ i ∈ B ∂ ( w , b ) l ( i ) ( w , b ) (\mathbf{w},b) \leftarrow (\mathbf{w},b) - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_{(\mathbf{w},b)} l^{(i)}(\mathbf{w},b) (w,b)←(w,b)−∣B∣ηi∈B∑∂(w,b)l(i)(w,b)
- 学习率: η \eta η代表在每次优化中,能够学习的步长的大小
- 批量大小: B \mathcal{B} B是小批量计算中的批量大小batch size
二、未知代码学习
import torch
torch.tensor() #tensor用于生成新的张量,张量概念是矢量概念的推广,矢量是一阶张量。
torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32) #二行一列的随机标准正态分布张量
index_select(0, j) #从第0维中挑选j位置上的数据
w.requires_grad_(requires_grad=True) #将权重w改成节点可导
torch.mm(a,b) #torch.mm(a, b)是矩阵a和b矩阵相乘
l.backward() #对损失函数求导
####################################################
#调用父类说明
class LinearNet(nn.Module):
def __init__(self, num_inputs, num_outputs):
#nn.Module是一个类是LinearNet的父类,super(LinearNet, self)将类LinearNet的对象转成nn.Module的对象,也就是说nn.Module的方法和属性,LinearNet也能用,
#.__init__() 开始构造属性和方法
super(LinearNet, self).__init__()
self.linear = nn.Linear(num_inputs, num_outputs)
def forward(self, x): # x 的形状: (batch, 1, 28, 28)
y = self.linear(x.view(x.shape[0], -1)) #将输出压缩成(batch,1*28*28)
return y
##################################
x_vals.detach().numpy() #detach()相当于复制,但是不能赋予梯度计算,再用numpy()将tensor类型转成numpy.ndarray矩阵
三、课后习题反思纠错

- 7是batch_size(批量大小)是每次取出的样本量;
- 8是num_outputs,是输入层单元数,相当于样本的属性数,也就是说每次给8个输入层单元喂入8个属性值,喂7次
- 1是输出层单元数(或者隐藏层单元数),输出层(隐藏层)形状是该层前面的神经数
- 线性层的权重参数w的形状是神经数,特定参数b是与输出层和隐藏层单元数相关
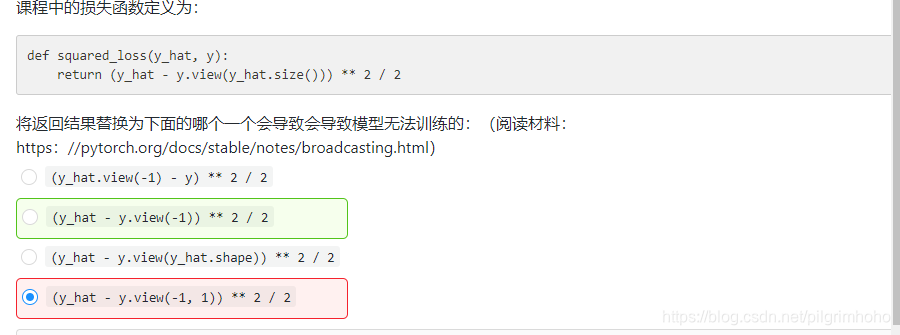
- 若a.shape=[1,2,3,4],a.view(shape[0],-1).shape=[1,24],.view()的作用是shape[0]在的位置保持不变,-1对应其余维度,把其余维度相乘合成一维,也就是压缩维度效果
- y_hat=net(X, w, b), y)得到的数据shape是[10,1],也就是10行一列;y的shape是[10],也就是一维,y_hat的大小和y是不一样的
- view()具体效果看下图
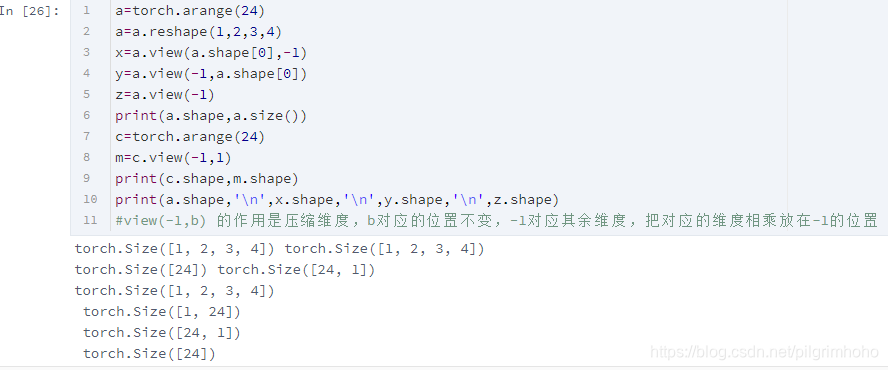

直接手算进行约分就行,e^100太大了,电脑无法计算出具体值,划为inf,无法进行计算
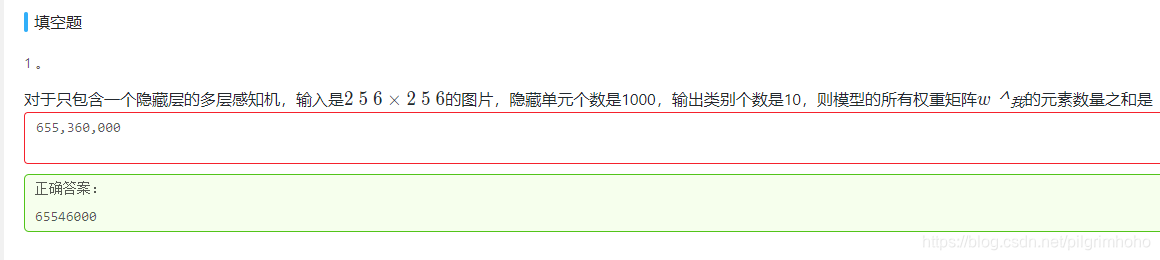
这个多层感知机为输入层单元数|隐藏层单元数|输出层单元数:
- 输入层和隐藏层,隐藏层和输出层之间各有一个权重矩阵,两个权重矩阵之间的关系是加法关系。
- 邻近两层之间的每条神经搭载一个权重,因此一个权重矩阵元素数是邻近两层单元数相乘














 2275
2275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









