







 本文详细介绍了开源项目kcws的分词原理,基于深度学习的字嵌入+Bi-LSTM+CRF模型。通过处理语料,使用word2vec进行字嵌入,然后在双向LSTM中加入CRF,优化模型以提高分词准确性。文中还讨论了训练过程中的问题,如TensorFlow版本和Python编译设置。
本文详细介绍了开源项目kcws的分词原理,基于深度学习的字嵌入+Bi-LSTM+CRF模型。通过处理语料,使用word2vec进行字嵌入,然后在双向LSTM中加入CRF,优化模型以提高分词准确性。文中还讨论了训练过程中的问题,如TensorFlow版本和Python编译设置。
分词原理
本小节内容参考待字闺中的两篇博文:
简单的说,kcws的分词原理就是:
- 对语料进行处理,使用word2vec对语料的字进行嵌入,每个字特征为50维。
- 得到字嵌入后,用字嵌入特征喂给双向LSTM, 对输出的隐层加一个线性层,然后加一个CRF就得到本文实现的模型。
- 于最优化方法,文本语言模型类的貌似Adam效果更好, 对于分类之类的,貌似AdaDelta效果更好。
另外,字符嵌入的表示可以是纯预训练的,但也可以在训练模型的时候再fine-tune,一般而言后者效果更好。对于fine-tune的情形,可以在字符嵌入后,输入双向LSTM之前加入dropout进一步提升模型效果。
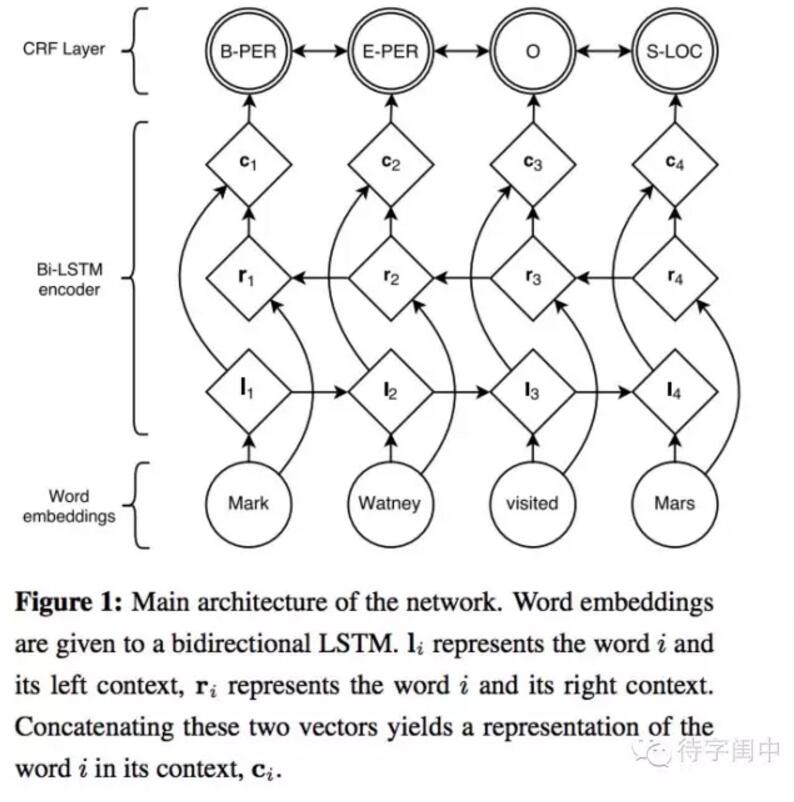
具体的解决方案,基于双向LSTM与CRF的神经网络结构:
如上图所示,单层圆圈代表的word embedding输入层,菱形代表学习输入的决定性方程,双层圆圈代表随机变量。信息流将输入层的word embedding送到双向LSTM, l(i)代表word(i)和从左边传入的历史信号,r(i)代表word(i)以及从右边传入的未来的信号,用c(i)连接这两个向量的信息,代表词word(i)。
先说Bi-LSTM这个双向模型,LSTM的变种有很多,基本流程都是一样的,文献中同样采用上一节说明的三个门,控制送入memory cell的输入信息,以及遗忘之前阶段信息的比例,再对细胞状态进行更新,最后用tanh方程对更新后的细胞状态再做处理,与sigmoid叠加相乘作为最终输出。具体的模型公式见下图,经过上一节的解释,这些符号应该不太陌生了。
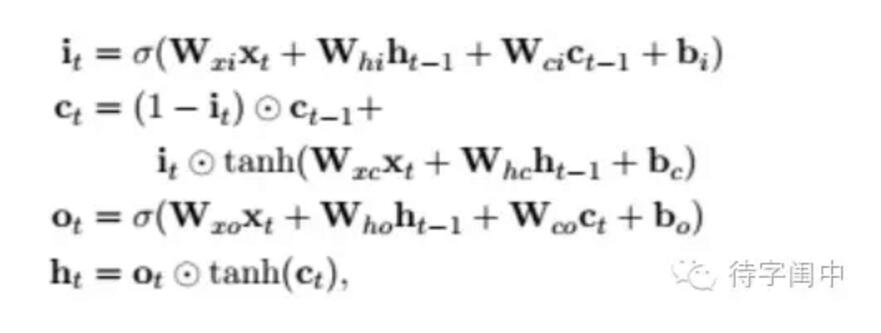
双向LSTM说白了,就是先从左至右,顺序学习输入词序列的历史信息,再从右至左,学习输入词序列未来影响现在的信息,结合这两种方式的最终表示有效地描述了词的内容,在多种标注应用上取得了好效果。
如果说双向LSTM并不特殊,这个结构中另一个新的尝试,就是将深度神经网络最后学出来的结果,作为特征,用CRF模型连接起来,用P来表示双向LSTM神经网络学习出来的打分输出矩阵,它是一个 nxk 的矩阵,n是输入词序列个数,k是标记类型的数目, P(ij)指的是在一个输入句子中,第i个词在第j个tag标记上的可能性(打分)。另外一个特征函数是状态转移矩阵 A,A(ij) 代表从tag i转移到tag j的可能性(打分),但这个转移矩阵实际上有k+2维,其中包括句子的开始和结束两个状态,用公式表示如下图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3705
3705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









