







原项目地址:
https://github.com/ztz818/Automatic-generation-of-text-summaries
相关知识介绍:
Word2Vec理论知识:https://blog.csdn.net/Pit3369/article/details/96482304
中文文本关键词抽取的三种方法(TF-IDF、TextRank、word2vec):
https://blog.csdn.net/Pit3369/article/details/95594728
调用summarize(text, n)返回Top N个摘要
-
tokens = cut_sentences(text)按照。!?切分句子,返回给
tokens[[句子1],[句子2]] -
对句子
tokens分词、通用词,返回列表sents:[[句子1分词结果],[句子2分词结果]],分词结果空格隔开 -
sents = filter_model(sents)遍历列表,去除word2vec词向量里未出现的词。
-
graph = create_graph(sents)传入句子列表,返回句子间相似度的图board[n*n],句子个数为n,图元素为i、j句子的相似值
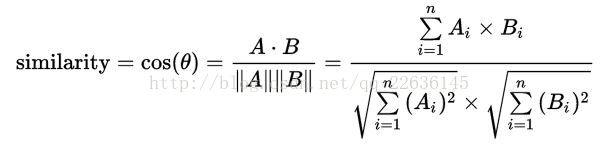
-
循环i、j:
board[i][j] = compute_similarity_by_avg(word_sent[i], word_sent[j])在
compute_similarity_by_avg(sents_1, sents_2)中,把句子中各个词词向量相加,除以句子长度作为句子平均得分,用来计算两个句子的相似度,返回给create_graph -
用句子i、j的
平均词向量进行相似度计算,相似值存储在board[i][j],返回给相似度图矩阵graph[][]
-
-
scores = weight_sentences_rank(graph)
输入相似度图矩阵graph[n*n],返回句子分数数组:scores[i],句子i的分值,初始值为0.5while循环迭代直至句子i分数变化稳定在0.0001:
-
scores[i] = calculate_score(weight_graph, scores, i)计算句子在图中分数,返回句子i的分数。参数j遍历所有句子:
- 计算分子:
fraction = weight_graph[j][i] * scores[j] - 计算分母:
denominator += weight_graph[j][k],参数k遍历句子j、k是否关联 - 分数累加:
added_score += fraction / denominator - 根据PageRank算法中PR值的计算方法,算出最终的分数,并返回:
weighted_score = (1 - d) + d * added_score
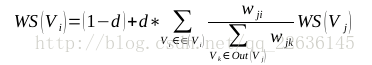
- 计算分子:
-
-
sent_selected = nlargest(n, zip(scores, count()))选取句子分数scores[],Top n的句子,作为摘要。
相似值计算:
使用的计算句子相似度的方式如下:
如计算句子A=[‘word’,‘you’,‘me’],与句子B=[‘sentence’,‘google’,‘python’]计算相似性,从word2vec模型中分别得到A中三个单词的词向量v1,v2,v3取其平均值Va(avg)=(v1+v2+v3)/3。对句子B做同样的处理得到Vb(avg),然后计算Va(avg)与Vb(avg)连个向量的夹角余弦值,Cosine Similarity视为句子A与B的相似度
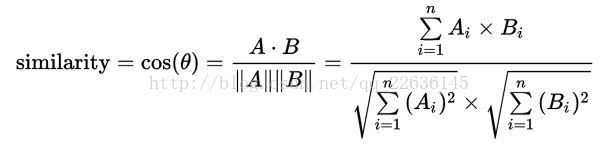
def cut_sentences(sentence):
puns = frozenset(u'。!?')#分隔句子
tmp = []
for ch in sentence:
tmp.append(ch)
if puns.__contains__(ch):
yield ''.join(tmp)
tmp = []
yield ''.join(tmp)
# 句子中的stopwords
def create_stopwords():
stop_list = [line.strip() for line in open("G:\1graduate\news_stopwords.txt", 'r', encoding='utf-8').readlines()]
return stop_list
def two_sentences_similarity(sents_1, sents_2):
'''
计算两个句子的相似性
:param sents_1:
:param sents_2:
:return:
'''
counter = 0
for sent in sents_1:
if sent in sents_2:
counter += 1
return counter / (math.log(len(sents_1)  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









