






ON-TRAC Consortium for End-to-End and Simultaneous Speech Translation Challenge Tasks at IWSLT 2020
1.方法总结
(1)模型方法
text-to-text subtask: transformer + wait-k models
Offline sppech translation Track
- speech features 80维 mel filterbank + 3 维 pitch features
数据增强方法:速度扰动 0.9-1.1+SpecAugment
文本预处理:去掉非speech 以及非german characters
offline speech translation Track
模型结构
- encoder
两层vgg-like block 每一层都是两个2d 卷积加上一层2d maxpooling 最后输入维度(TxD)->(T/4xD/4)
5 层双向lstm - decoder
两层lstm

超参设置
early stop 3 epoches max epoch = 20
dropout = 0.3
解码最大长度 = encoder hidden state length
多模型调整策略: 模型相似 不同:训练语料, tokenization units , finetuing 和 预训练策略。
online MT
常规做法是,wait-k decoding, 先读k个source token, 然后读一个token, 解一个token,这样交替进行,直到结束。
训练的时候最大化likelihood estimation, 只针对一个单一的wait-k 解码路径,
z
k
z^k
zk
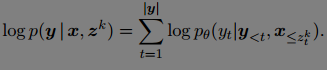
本文的做法是联合优化多条wait-k 路径,认为其他的loss项可以提供更多的训练信号。
具体做法是,在每一个训练epoch, 对source sequence 随机采用一条解码路径然后优化。
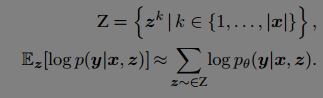
Cascaded ASR+MT
延迟大小通过asr系统的endpointing 来控制,MT 系统不做segment 中止的预测,只通过输出结束符来停止翻译,同时句子长度的最大值根据
α
∣
x
a
s
r
∣
+
β
\alpha|x_{asr}|+\beta
α∣xasr∣+β 来控制的。
















 8138
8138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









