






1.论文摘要
Transformer 为基础的模型擅长捕捉content-based gloabl interactions;卷积更适合捕捉局部的local features. 本文将两者的优势结合起来,并且使用的参数更少,在Lbrispeech 上达到了SOTA with 2.1/4.3% 的wer.
2. 模型结构

- Multi-Headed Self-Attention Module
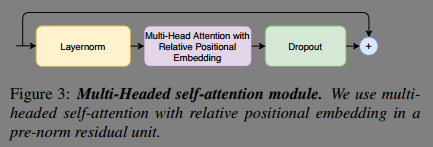
- Convolution Module
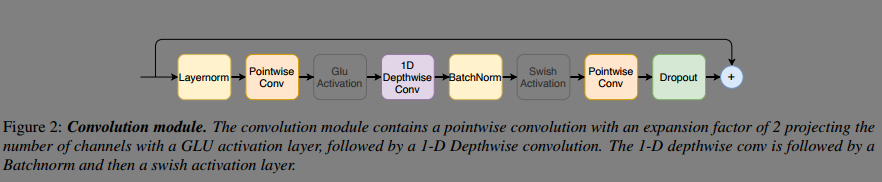
- Feed Forward Module

两个线性层中间加一个非线性激活函数, 并且采用residual connection 和layernorm。
- Conformer Block
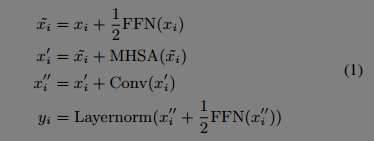
#3. 实验结果
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









