






On Knowledge Distillation for Direct Speech Translation
1. 论文摘要
语音翻译任务同行利用knowledge transfer 从子任务:asr和Mt 任务来辅助,本文提出了利用knowledge distillation 来提升语音翻译任务的效果,同时分析了这种方法的缺点以及如何提升翻译质量。
2.ST与级联的优点缺点对比
优点:
(1)在翻译时可以获得语音的信息,而级联只能得到撰写的文本。
(2)防止了error propagation
(3)延迟更低。
(4)单模型更好管理,无需整合。
缺点:缺少有效训练数据。
主要工作:
- 对比了不同KD techniques, 例如 word level, sequence level ,sequence interpolation以及三者组合
- 结果时word level KD结果最好,并且在没有KD的语料finetune 结果更好。
三种level
word level 计算teacher 和student之间的kl 散度作为优化目标,在计算时预存了teacher output 的概率同时对分布做了截断。
sequece level: beam search 解码结果。
sequence interpolation: n best 结果的最好BLEU 分作为评判指标。
Model
ST和ASR用S-Transformer并且包含对数距离惩罚项(encoder 端)在训练libri speech的时候用了一个基础配置DI Gang
去除了2d 的attention layers 并且改变Transformer 的encoder decoder layers 为11 和4, Asr 为8和6
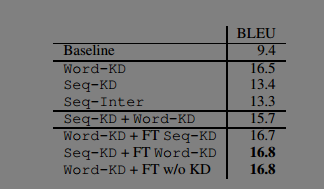
不同distill 方法对比
- 在没有kD 的数据上finetune blue 分有明显提升的原因。
(1) sampples with multiple sentences
MT 的训练语料一般是sentence level 的所以mt 模型在"dot"后倾向于产生eos, 这个特点被student model st 学到了,造成当有多句话时,直接阶段,解码不完整。finetune 解决了这个问题。
(2)verbal tenses 更准确。
(3) lexical choices
不好的地方:speaker related words that exacerbates the gender bias. (gender marked words 上表现不好,因为MT 无法获得性别信息。)
















 3372
3372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









