






>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rbOOmire8OocQ90QM78DRA) 中的学习记录博客**
>- **🍖 原作者:[K同学啊 | 接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**
词嵌入是一种用于自然语言处理 (NLP) 的技术,用于将单词表示为数字
one-hot编码就是最早期的词嵌入方法。
Embedding和EmbeddingBag则是PyTorch中的用来处理文本数据中词嵌入(word embedding)的工具,它们将离散的词汇映射到低维的连续向量空间中,使得词汇之间的语义关系能够在向量空间中得到体现。
整数张量是一个包含整数值的张量,张量是一种多维数组。在深度学习中,通常使用整数张量来表示离散的信息,比如词汇表中的词汇索引。每个整数代表一个特定的词汇或类别,通过这些整数,可以将离散的符号信息编码成神经网络能够处理的形式。
举个例子,假设有一个词汇表,其中包含三个词:"apple","banana",和"orange",它们分别被编码为整数张量0,1,20,1,2。在神经网络中,这些整数张量可以经过Embedding层,将它们映射成对应的词嵌入向量,从而在网络中进行进一步的处理。
EmbeddingBag 层中的 mode 参数用于指定如何对每个序列中的嵌入向量进行汇总,常用的模式有三种
-
'sum':此模式计算每个序列的嵌入向量之和。当您想要捕获序列中包含的整体信息时,它非常有用。
-
'mean':在此模式下,计算每个序列的嵌入向量的平均值。它通常用于获取考虑序列不同长度的代表性向量。
-
'max':'max' 模式计算每个序列的嵌入向量每个维度的最大值。当您想要关注序列中最重要的特征时,它非常有用。
Embedding 专注于将整数索引映射到固定的嵌入向量,而 EmbeddingBag 进一步支持变长序列,并提供了灵活的池化操作。
让我们以自然语言处理(NLP)任务为例,比如文本分类。假设你有一个词汇表,其中每个单词都有一个唯一的整数索引。你想将一个文本序列转换为神经网络可以处理的形式。
使用 Embedding:
-
创建词嵌入层:
embedding_layer = nn.Embedding(vocab_size, embedding_dim)这里,
vocab_size是词汇表的大小,embedding_dim是每个单词嵌入向量的维度。 -
输入文本序列:
input_sequence = torch.LongTensor([index1, index2, index3, ...])这里,
index1,index2,index3是文本序列中单词对应的整数索引。 -
应用嵌入层:
embedded_sequence= embedding_layer(input_sequence) -
embedded_sequence是一个包含嵌入向量的张量,每行对应一个单词的嵌入。
使用 EmbeddingBag:
-
创建嵌入包层:
embedding_bag_layer = nn.EmbeddingBag(vocab_size, embedding_dim, sparse=True)与
Embedding不同,EmbeddingBag可以处理变长序列,同时支持稀疏张量。 -
输入文本序列:
input_sequence = torch.LongTensor([index1, index2, index3, ...])offsets = torch.LongTensor([0, len1, len1+len2, ...]) -
offsets表示每个文本的起始位置,可以用于区分不同文本的边界。 -
应用嵌入包层:
embedded_sequence = embedding_bag_layer(input_sequence, offsets)embedded_sequence -
是一个包含嵌入向量的张量,根据
offsets进行池化操作,以适应变长序列的输入。
这两者都是为了将离散的整数索引映射到密集的嵌入向量,但 EmbeddingBag 在处理变长序列时更加灵活。
Embedding:
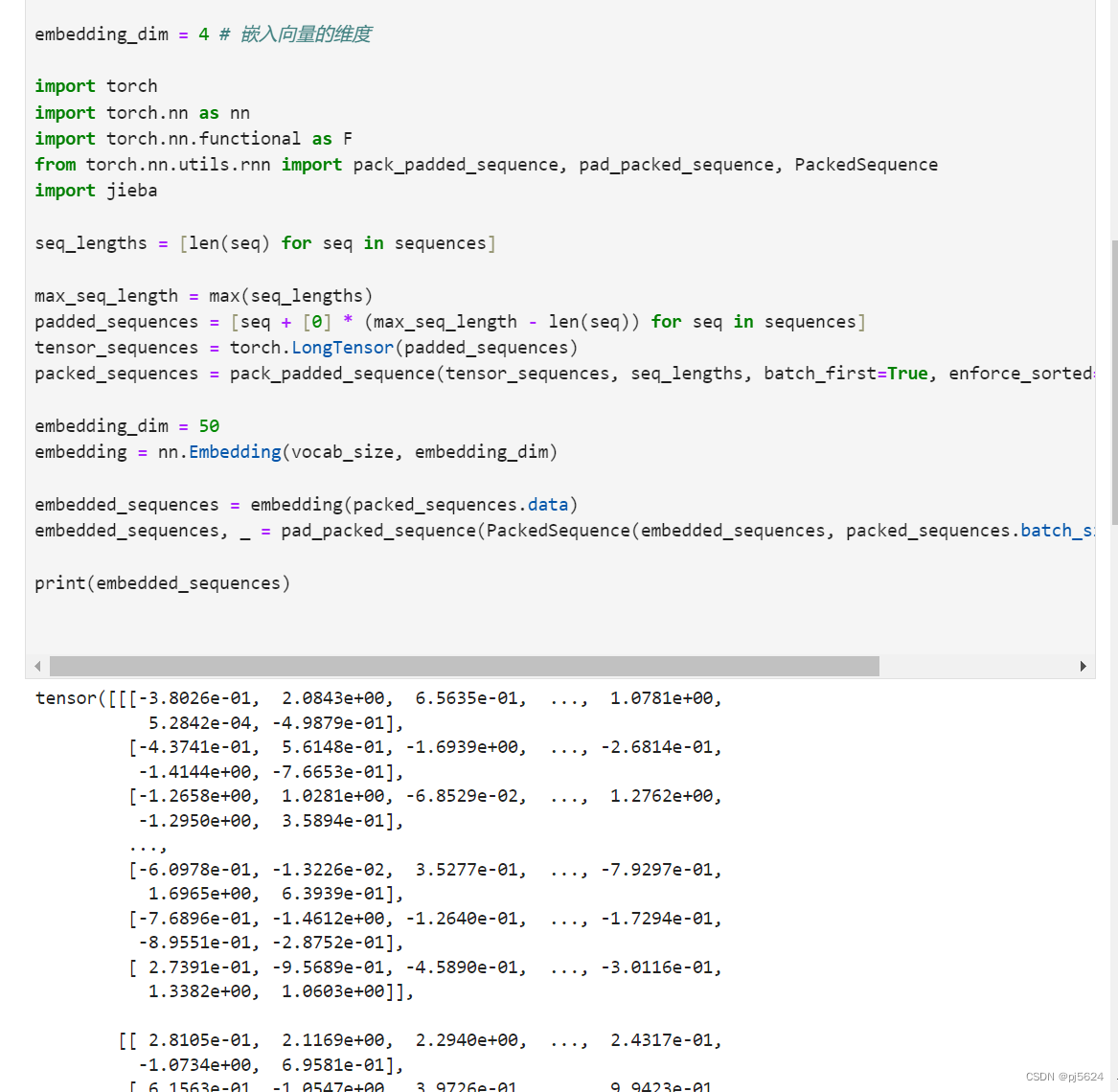
Embeddingbag:
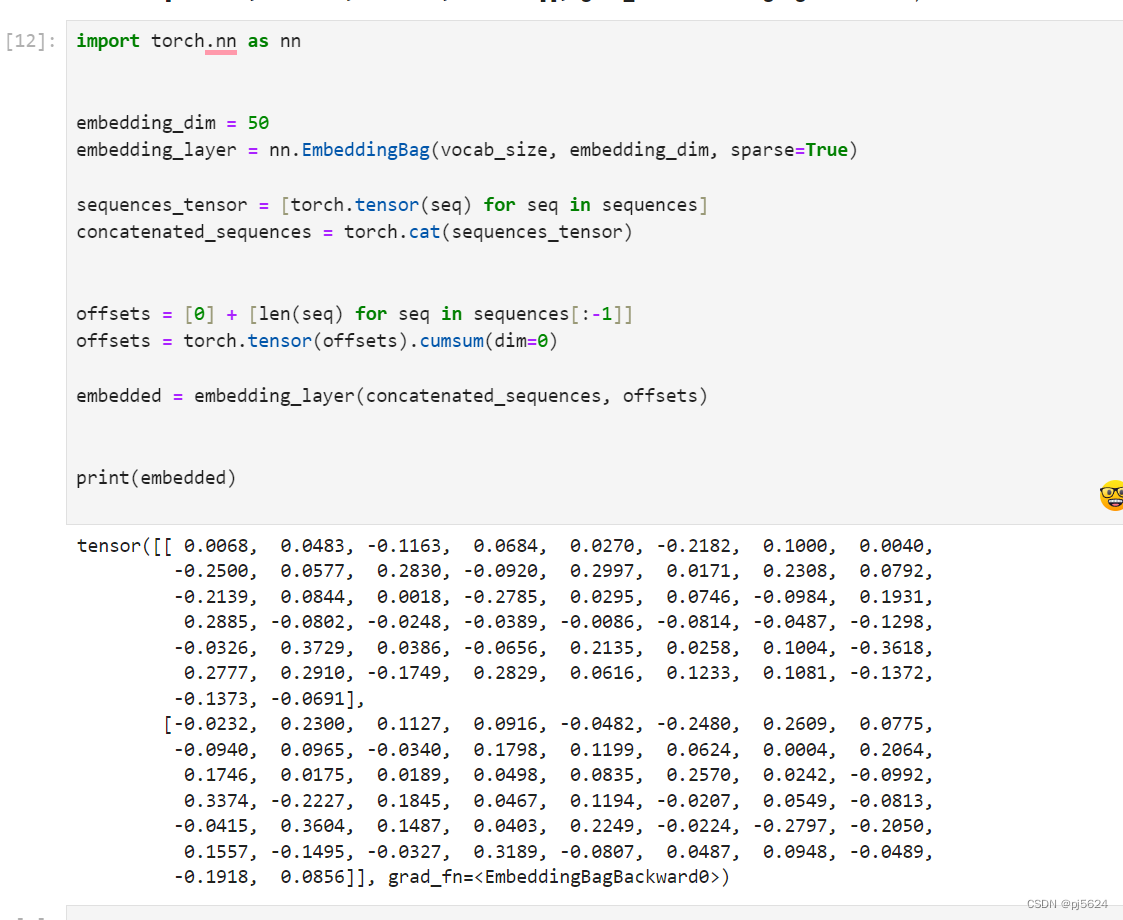














 5068
5068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









