






1. 基本原理
GAN 基础
生成对抗网络由两个主要部分组成:
- 生成器(Generator,G):生成逼真的数据样本,试图欺骗判别器。
- 判别器(Discriminator,D):区分真实数据和生成的数据。
半监督学习
半监督学习利用带标签数据和未带标签数据来训练模型,旨在减少对大量标注数据的需求。SS-GAN通过修改判别器的结构,使其能够同时处理分类任务和生成任务。
2. 结构
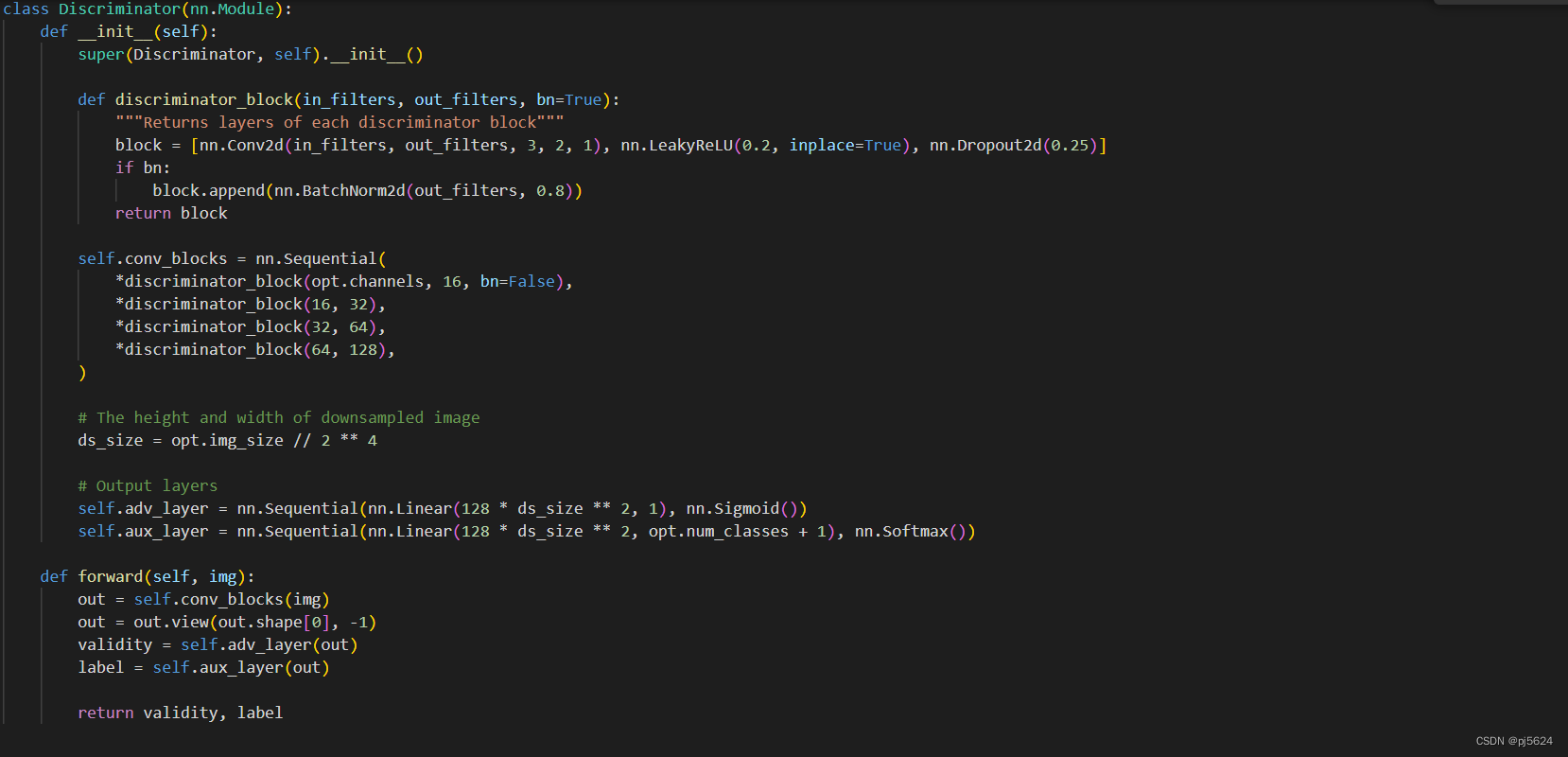
判别器(D)
在SS-GAN中,判别器不仅需要区分真实数据和生成数据,还需要对真实数据进行分类。因此,判别器的输出层通常设计成有𝐾+1K+1个节点,其中𝐾K是分类任务的类别数,额外的一个节点用于判断输入是否为生成数据。
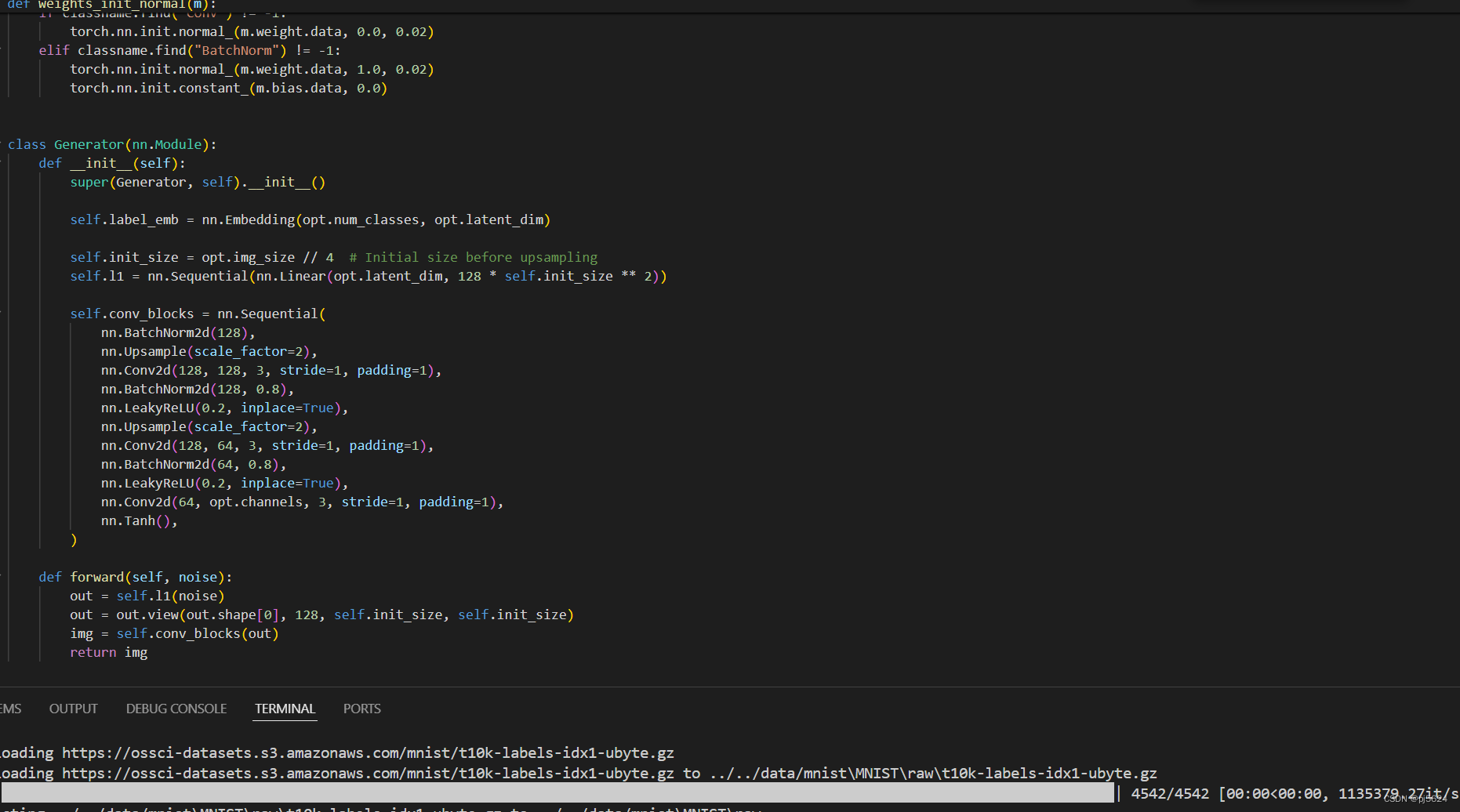
生成器(G)
生成器的目标保持不变,试图生成逼真的数据样本,以欺骗判别器。
3. 训练过程
带标签数据的训练
使用带标签的数据对判别器进行训练,使其能够准确分类不同类别的数据,同时区分真实数据和生成数据。具体步骤包括:
- 从带标签数据集中抽取一个小批量样本。
- 使用这些样本训练判别器,使其最大化区分真实数据的类别,同时区分真实数据和生成数据。
未带标签数据的训练
使用未带标签的数据对判别器进行训练,主要目的是增强判别器区分真实数据和生成数据的能力。具体步骤包括:
- 从未带标签数据集中抽取一个小批量样本。
- 生成器生成一个小批量的假样本。
- 使用这些未带标签的真实样本和生成样本训练判别器,使其最大化区分真实数据和生成数据。
生成器的训练
生成器的训练目标是最小化判别器将生成样本判定为假的概率。具体步骤包括:
- 生成器生成一个小批量的假样本。
- 使用这些假样本更新生成器的参数,使得判别器更难以区分这些生成样本和真实样本。
4. 应用
SS-GAN在各种任务中都有广泛应用,特别是在标注数据稀缺的场景中。常见应用包括:
- 图像分类:在只有少量标注数据的情况下,通过SS-GAN提升图像分类模型的性能。
- 图像生成:生成逼真的图像样本,同时利用少量标注数据提高生成质量。
- 语音识别:在语音数据标注成本高的情况下,利用SS-GAN提升语音识别模型的效果。
5. 优势
- 减少标注数据需求:SS-GAN利用大量未标注的数据,有效减少对标注数据的依赖。
- 提高分类性能:通过结合生成对抗网络的特性,SS-GAN能够提升分类任务的性能,特别是在标注数据不足的情况下。
- 生成高质量样本:生成器在训练过程中不断改进,能够生成高质量的假样本。
命令行参数:
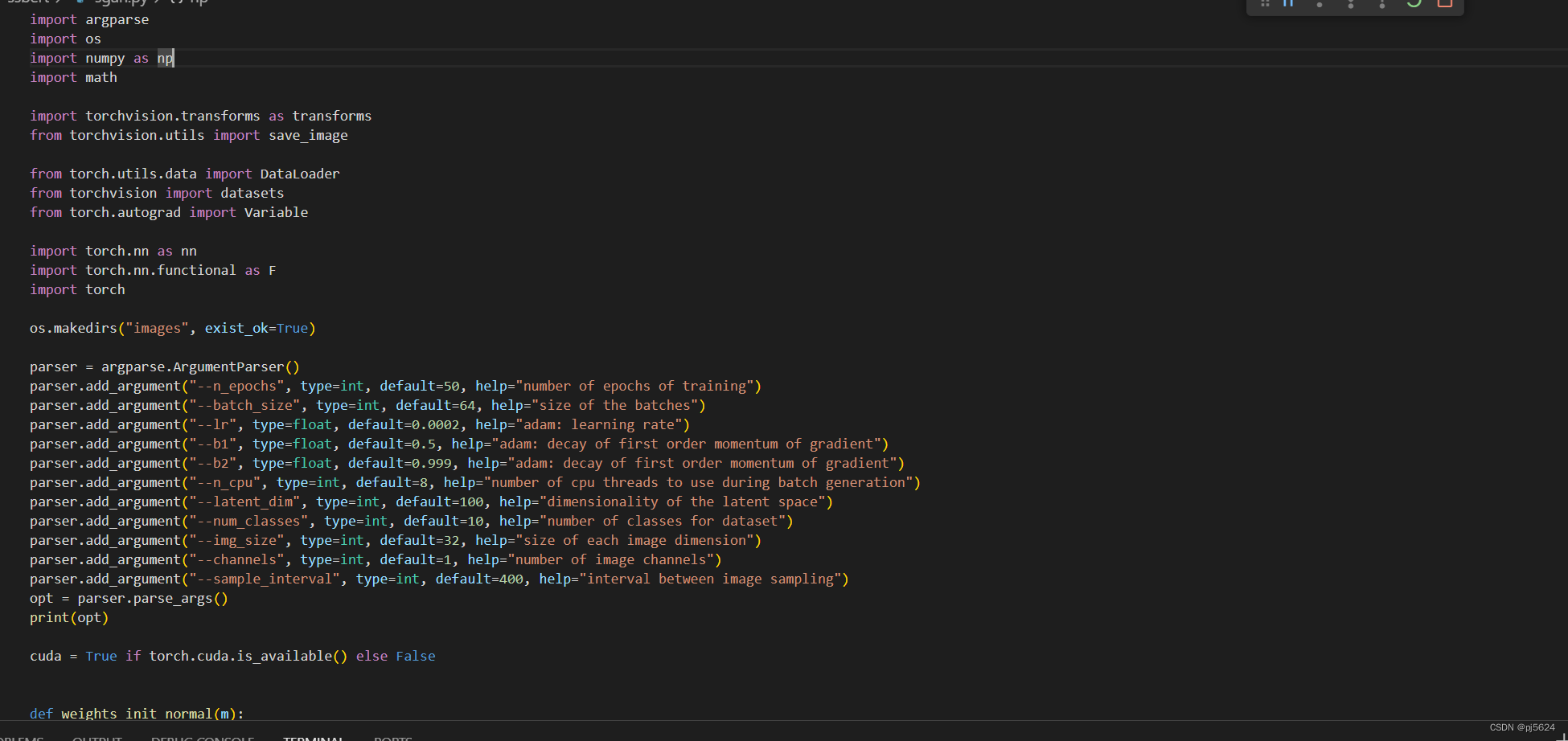
生成器:
判别器:
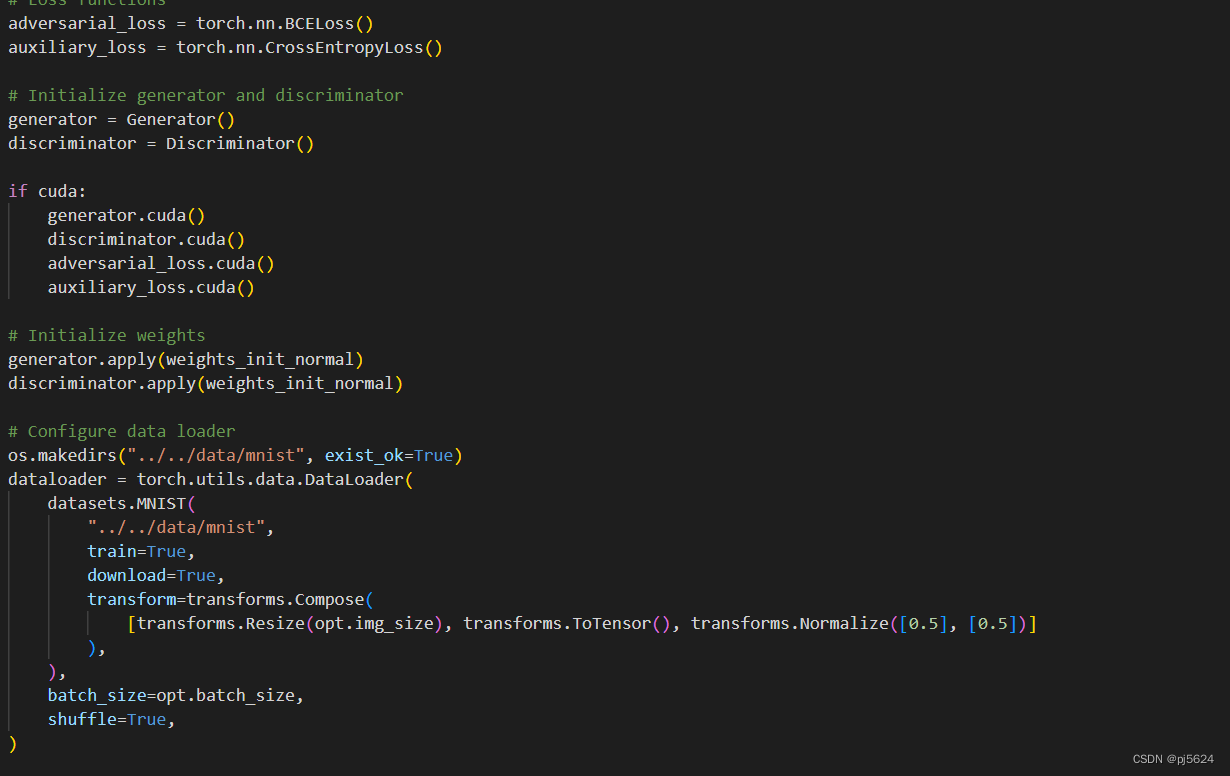
初始化,加载数据:
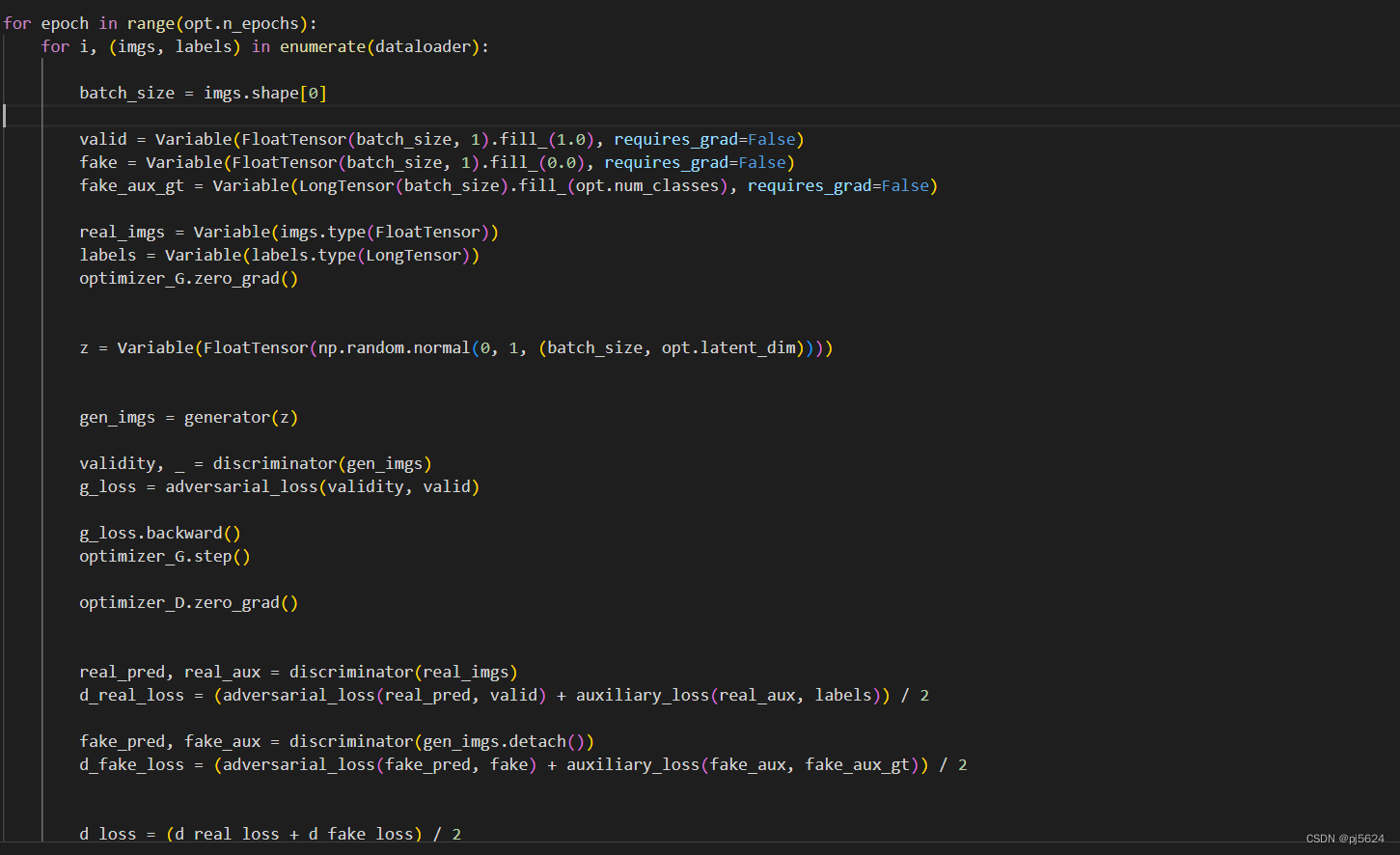
训练函数:















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









