










Elasticsearch简介
Elasticsearch为和何物?
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
Elasticsearch使用场景
**2013年初,GitHub抛弃了Solr,**采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”
**
维基百科:启动以elasticsearch为基础的核心搜索架构
SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
**
百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
**
新浪使用ES 分析处理32亿条实时日志
**
阿里使用ES 构建挖财自己的日志采集和分析体系
ElasticSearch对比Solr
Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
Elasticsearch的安装与启动
安装包下载
ElasticSearch分为Linux和Window版本,基于我们主要学习的是ElasticSearch的Java客户端的使用,所以我们课程中使用的是安装较为简便的Window版本,项目上线后,公司的运维人员会安装Linux版的ES供我们连接使用。
ElasticSearch的官方地址: https://www.elastic.co/products/elasticsearch




安装ES服务
Window版的ElasticSearch的安装很简单,类似Window版的Tomcat,解压开即安装完毕,解压后的ElasticSearch的目录结构如下:

修改elasticsearch配置文件:config/elasticsearch.yml,增加以下两句命令:
http.cors.enabled: true
http.cors.allow‐origin: "*"
此步为允许elasticsearch跨越访问,如果不安装后面的elasticsearch-head是可以不修改,直接启动
启动ES服务
点击ElasticSearch下的bin目录下的elasticsearch.bat启动,控制台显示的日志信息如下:


注意:9300是tcp通讯端口,集群间和TCPClient都执行该端口,9200是http协议的RESTful接口 。
通过浏览器访问ElasticSearch服务器,看到如下返回的json信息,代表服务启动成功:

注意:
ElasticSearch是使用java开发的,且本版本的es需要的jdk版本要是1.8以上,所以安装ElasticSearch之前保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败。
安装ES的图形化界面插件
ElasticSearch不同于Solr自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效果,完成索引数据的查看。安装插件的方式有两种,在线安装和本地安装。本文档采用本地安装方式进行head插件的安装。elasticsearch-5-*以上版本安装head需要安装node和grunt
1)下载head插件:https://github.com/mobz/elasticsearch-head

2)将elasticsearch-head-master压缩包解压到任意目录,但是要和elasticsearch的安装目录区别开
3)下载nodejs:https://nodejs.org/en/download/在资料中已经提供了nodejs安装程序:双击安装程序,步骤截图如下:





安装完毕,可以通过cmd控制台输入:node -v 查看版本号

5)将grunt安装为全局命令 ,Grunt是基于Node.js的项目构建工具
在cmd控制台中输入如下执行命令:
npm install ‐g grunt‐cli
执行结果如下图:

6)进入elasticsearch-head-master目录启动head,在命令提示符下输入命令:
nmp install
grunt server

7)打开浏览器,输入 http://localhost:9100,看到如下页面:

如果不能成功连接到es服务,需要修改ElasticSearch的config目录下的配置文件:config/elasticsearch.yml,增加以下两句命令:
http.cors.enabled: true
http.cors.allow-origin: "*"
然后重新启动ElasticSearch服务。

ElasticSearch相关概念
概述
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。Elasticsearch比传统关系型数据库如下:
Relational DB ‐> Databases ‐> Tables ‐> Rows ‐> Columns
Elasticsearch ‐> Indices ‐> Types ‐> Documents ‐> Fields
**
Elasticsearch核心概念
**
1.索引 index(相当于一个数据库)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
**
2. 类型 type(相当于数据库中的一张表)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
**
3. 字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
**
4. 映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
**
5. 文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
**
6. 接近实时 NRT
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
**
7. 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
**
8. 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
**
9. 分片和复制 shards&replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因: 1)允许你水平分割/扩展你的内容容量。 2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因
消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分
片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
ElasticSearch的客户端操作 Postman的安装与使用
实际开发中,主要有三种方式可以作为elasticsearch服务的客户端:
第一种,elasticsearch-head插件
第二种,使用elasticsearch提供的Restful接口直接访问
第三种,使用elasticsearch提供的API进行访问
什么是Postman?
一款简单的发送与接受请求的工具
具体步骤
1.安装Postman工具
2.下载Postman工具
3.注册Postman工具
4.使用Postman工具进行Restful接口访问
1.下载Postman工具
Postman官网:https://www.getpostman.com

2.注册Postman工具

3.使用Postman工具进行Restful接口访问

3.1ElasticSearch的接口语法
curl ‐X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' ‐d '<BODY>'
| 参数 | 解释 |
|---|---|
| VERB | 适当的 HTTP 方法 或 谓词 : GET 、 POST 、 PUT 、 HEAD 或者 DELETE 。 |
| PROTOCOL | http 或者 https (如果你在 Elasticsearch 前面有一个 https 代理) |
| HOST | Elasticsearch 集群中任意节点的主机名,或者用 |
| localhost 代表本地机器上的节点。 | |
| PORT | 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
| PATH | API 的终端路径(例如 _count 将返回集群中文档数量)。 |
Path 可能包含多个组件,例
如: _cluster/stats 和 _nodes/stats/jvm 。 |
| QUERY_STRING | 任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,
使其更容易阅读) |
| BODY | 一个 JSON 格式的请求体 (如果请求需要的话) |
**
3.2创建索引index与映射mapping
我们可以在创建索引时设置mapping信息,当然也可以先创建索引然后再设置mapping。
在上一个步骤中不设置maping信息,直接使用put方法创建一个索引,然后设置mapping信息。
请求的url:
语法
ip:port/要创建的index的名称
POST http://127.0.0.1:9200/blog2/_mapping
Properties内部相当于定义字段:
{
"mappings": {
"properties":{
"id": {
"type": "long",
"store": true
}
}
}
}

由图形化界面查看可知成功的创建了索引

3.3创建索引后设置Mapping
我们可以在创建索引时设置mapping信息,当然也可以先创建索引然后再设置mapping。
在上一个步骤中不设置maping信息,直接使用put方法创建一个索引,然后设置mapping信息。
请求的url:
语法
localhost:9200/test2/_mapping
_mapping:执行动作的字符串
http://127.0.0.1:9200/blog2/_mapping
{
"properties":{
"id4": {
"type": "long",
"store": true
}
}
}

3.4删除索引Mapping
只需将请求方法改成delete即可
语法:
ip:port/index
例:删除test2索引
localhost:9200/test2



3.5创建文档document
语法:
**
post请求
ip:9200/索引名/_doc/id值
例:
**
localhost:9200/test/_doc/2
请求体:
POST localhost:9200/blog1/_doce/1
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java
开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时
搜索,稳定,可靠,快速,安装使用方便。"
}
添加的字段名要和Elasticsearch中的字段名一致,否则找不到对应的字段名

成功添加

3.6修改文档
**
语法:
**
post请求
ip:9200/索引名/_doc/id值
案例修改刚刚id为1的document的内容


3.7删除文档document
语法:
**
delete请求
ip:9200/索引名/_doc/id值
案例删除刚刚id为1的document的
**

3.8查询文档-根据id查询
语法:
Get请求
ip:9200/索引名/_doc/id值
例:查询id为的docuemnt

3.9查询文档-querystring查询
**
语法
_search:执行动作的字符串
psot请求
ip:9200/索引名/_doc/_search
请求体:
**
该请求的意思是只要含有query后面语句中的一个字就返回对应document的字段
default_field为对应的字段名
{
"query":{
"query_string":{
"default_field": "title",
"query":"服务器"
}
}
}

3.10查询文档-term查询
语法
**
_search:执行动作的字符串
**
psot请求
ip:9200/索引名/_doc/_search
请求体
**
-term只可以一个汉字一个汉字的查询
{
"query":{
"term":{
"title":"服"
}
}
}
IK 分词器和ElasticSearch集成使用
上诉分词器存在的问题
在进行字符串查询时,我们发现去搜索"搜索服务器"和"钢索"都可以搜索到数据;
而在进行词条查询时,我们搜索"搜索"却没有搜索到数据;
究其原因是ElasticSearch的标准分词器导致的,当我们创建索引时,字段使用的是标准分词器:
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,例如对 "我是程序员" 进行分词
标准分词器分词效果测试:
分词结果:
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard" //标准分词器
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard" //标准分词器
}
}
}
}
}
例如对 “我是程序员” 进行分词
标准分词器分词效果测试:
http://127.0.0.1:9200/_analyze?analyzer=standard&pretty=true&text=我是程序员
分词结果:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "程",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "序",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
而我们需要的分词效果是:我、是、程序、程序员
这样的话就需要对中文支持良好的分析器的支持,支持中文分词的分词器有很多,word分词器、庖丁解牛、盘古分词、Ansj分词等,但我们常用的还是下面要介绍的IK分词器。
IK分词器简介
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
**1)**采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
**2)**采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
**3)**对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同时是支持个人词条的优化的词典存储,更小的内存占用。
**4)**支持用户词典扩展定义。
**5)**针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
分词器下载安装
1)下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
选择你对应ElasticSearch的版本进行下载安装

2)解压
将解压后的elasticsearch文件夹拷贝到elasticsearch-对应版本\plugins下,并重命名文件夹为analysis-ik

3)重新启动ElasticSearch,即可加载IK分词器

测试
IK提供了两个分词算法ik_smart 和 ik_max_word
其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
我们分别来试一下
1)最小切分:
在postman地址栏输入地址

输出结果
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "程序员",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}
2)最细切分:
在postman地址栏输入地址

输出结果
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "程序员",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "程序",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "员",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 4
}
]
}
修改索引映射mapping
删除原有blog1索引

创建blog1索引,此时分词器使用ik_max_word
{
"properties": {
"id": {
"type": "long",
"store": true
},
"title": {
"type": "text",
"store": true,
"index":"true",
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index":"true",
"analyzer":"ik_max_word"
}
}
}
创建文档

再次测试queryString查询
将请求体搜索字符串修改为"搜索服务器",查询


将请求体搜索字符串修改为"钢索",再次查询


ElasticSearch集群
概述
ES集群是一个 P2P类型(使用 gossip 协议)的分布式系统,除了集群状态管理以外,其他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信。所以,从网络架构及服务配置上来说,构建集群所需要的配置极其简单。在 Elasticsearch 2.0 之前,无阻碍的网络下,所有配置了相同 cluster.name 的节点都自动归属到一个集群中。2.0 版本之后,基于安全的考虑避免开发环境过于随便造成的麻烦,从 2.0 版本开始,默认的自动发现方式改为了单播(unicast)方式。配置里提供几台节点的地址,ES 将其视作gossip router 角色,借以完成集群的发现。由于这只是 ES 内一个很小的功能,所以 gossip router 角色并不需要单独配置,每个 ES 节点都可以担任。所以,采用单播方式的集群,各节点都配置相同的几个节点列表作为 router即可。集群中节点数量没有限制,一般大于等于2个节点就可以看做是集群了。一般处于高性能及高可用方面来考虑一般集群中的节点数量都是3个及3个以上。
Elasticsearch相关概念
1 .集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
2. 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
3. 分片和复制 shards&replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任
一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供
了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因:
1)允许你水平分割/扩展你的内容容量。
2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
集群的搭建
1.准备三台elasticsearch服务器
创建elasticsearch-cluster文件夹,在内部复制三个elasticsearch服务
2. 修改每台服务器配置
修改elasticsearch-cluster\node*\config\elasticsearch.yml配置文件
node1节点:
# es-7.3.0-node-1
cluster.name: search-7.3.2
node.name: node-1
node.master: true
node.data: false
node.ingest: false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
cluster.initial_master_nodes: ["node-1"]
node2节点:
# es-7.3.0-node-2
cluster.name: search-7.3.2
node.name: node-2
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9201
transport.port: 9301
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
node3节点:
# es-7.3.0-node-3
cluster.name: search-7.3.2
node.name: node-3
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9202
transport.port: 9302
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
3. 启动各个节点服务器
双击elasticsearch-cluster\node*\bin\elasticsearch.bat
启动节点1:
启动节点2:
启动节点3:

4.集群测试
添加索引和映射
PUT localhost:9200/blog1
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard"
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard"
}
}
}
}
}
添加文档
POST localhost:9200/blog1/article/1
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。"
}
使用elasticsearch-header查看集群情况

Java集合Elasticsearch

1. 简述
-
Elasticsearch是基于Lucene开发的一个分布式全文检索框架,向Elasticsearch中存储和从Elasticsearch中查询,格式是json。 -
向
Elasticsearch中存储数据,其实就是向es中的index下面的type中存储json类型的数据。 -
elasticsearch提供了很多语言的客户端用于操作elasticsearch服务,例如:java、python、.net、JavaScript、PHP等。本文主要介绍如何使用java语言来操作elasticsearch服务。在elasticsearch的官网上提供了两种java语言的API,一种是Java Transport Client,一种是Java REST Client。
Java Transport Client** 是基于 TCP 协议交互的,**在elasticsearch 7.0+版本后官方不再赞成使用,在Elasticsearch 8.0的版本中完全移除TransportClient
**Java REST Client是基于 HTTP 协议交互,**而Java REST Client又分为Java Low Level REST Client和Java High Level REST Client
Java High Level REST Client是在Java Low Level REST Client的基础上做了封装,使其以更加面向对象和操作更加便利的方式调用elasticsearch服务。
官方推荐使用
Java High Level REST Client,因为在实际使用中,Java Transport Client在大并发的情况下会出现连接不稳定的情况。
那接下来我们就来看看elasticsearch提供的Java High Level REST Client(以下简称高级REST客户端)的一些基础的操作,跟多的操作大家自行阅读elasticsearch的官方文档:[https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html](https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html)
2. 准备
- 环境:
Windows 10elasticsearch 7.91IDEAMavenJava 8
高级客户端需要
Java 1.8并依赖于Elasticsearch core项目
- 依赖:
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.9.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.9.1</version>
</dependency>
3. 初始化
- 实例需要构建 REST 低级客户端生成器,如下所示:
RestHighLevelClient
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
- 高级客户端将在内部创建用于基于提供的生成器执行请求的低级客户端。该低级客户端维护一个连接池并启动一些线程,因此,当您很好地完成高级客户端时,您应该关闭该高级客户端,然后关闭内部低级客户端以释放这些资源。这可以通过 以下时间完成:
close
client.close();
在有关 Java 高级客户端的本文档的其余部分中,实例将引用为 。
RestHighLevelClientclient
案例:
- 查询
index代码:
public static void main(String[] args) {
RestClientBuilder builder = RestClient.builder(
new HttpHost(
"127.0.0.1", //es主机 IP
9200 // es 端口http
)
);
RestHighLevelClient client = new RestHighLevelClient(builder);
GetRequest request = new GetRequest(
"blog1", //索引
"1" //文档ID
);
//当针对不存在的索引执行获取请求时,响应404状态码,将引发IOException,需要按如下方式处理:
GetResponse documentFields = null;
try {
documentFields = client.get(request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
处理因为索引不存在而抛出的异常情况
}
System.out.println(documentFields);
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
- 查询结果:
{
"_index": "blog1",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"age": 1,
"country": "fuzhou",
"date": "2020-09-10",
"name": "ngitvusercancel"
}
}
上述是一个案例的展示,让我们初步了解通过
Java的高级restful客户端来访问, 下面我们将进行相关Api的介绍
4. 索引 API (Index Api)
4.1 创建索引(Create Index API)
**
4.1.1 案例:
/*
* 创建索引.
* url:https://i-code.online/
*/
public static void main(String[] args) {
//创建链接信息
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
//创建索引请求 索引名称 student
CreateIndexRequest createIndexRequest = new CreateIndexRequest("student-1");
//创建索引时可以设置与之相关的 特定配置
createIndexRequest.settings(Settings.builder()
.put("index.number_of_shards",3) //分片数
.put("index.number_of_replicas",2) //备份数
);
//创建文档类型映射
createIndexRequest.mapping("{\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"long\",\n" +
" \"store\": true\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"text\",\n" +
" \"index\": true,\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"content\": {\n" +
" \"type\": \"text\",\n" +
" \"index\": true,\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
"}",
XContentType.JSON //类型映射,需要的是一个JSON字符串
);
//可选参数
//超时,等待所有节点被确认(使用TimeValue方式)
createIndexRequest.setTimeout(TimeValue.timeValueMinutes(1));
try {
//同步执行
CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
//返回的CreateIndexResponse允许检索有关执行的操作的信息,如下所示:
boolean acknowledged = createIndexResponse.isAcknowledged();//指示是否所有节点都已确认请求
boolean shardsAcknowledged = createIndexResponse.isShardsAcknowledged();//指示是否在超时之前为索引中的每个分片启动了必需的分片副本数
System.out.println("acknowledged:"+acknowledged);
System.out.println("shardsAcknowledged:"+shardsAcknowledged);
System.out.println(createIndexResponse.index());
} catch (IOException e) {
e.printStackTrace();
}
try {
//关闭客户端链接
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
上述是一个 index 创建的过程,具体的细节操作
api下面详解
4.1.2 创建索引请求
- 需要参数:
CreateIndexRequestindex
CreateIndexRequest request = new CreateIndexRequest("twitter");//<1>
<1>要创建索引
4.1.3 索引设置
- 创建的每个索引都可以具有与其关联的特定设置。
//此索引的设置
request.settings(Settings.builder()
.put("index.number_of_shards", 3) //分片数
.put("index.number_of_replicas", 2)//备份数
);
4.1.4 索引映射
- 可以创建索引,并创建其文档类型的映射
request.mapping(
"{\n" +
" "properties": {\n" +
" "message": {\n" +
" "type": "text"\n" +
" }\n" +
" }\n" +
"}", //<1> 要定义的类型
XContentType.JSON); //<2> 此类型的映射,作为 JSON 字符串提供
<1>要定义的类型
<2>此类型的映射,作为JSON字符串提供
- 除了上面显示的示例之外,还可以以不同的方式提供映射源:
String
Map<String, Object> message = new HashMap<>();
message.put("type", "text");
Map<String, Object> properties = new HashMap<>();
properties.put("message", message);
Map<String, Object> mapping = new HashMap<>();
mapping.put("properties", properties);
request.mapping(mapping); //接受map的映射集合,自动转为 json
提供自动转换为
JSON格式的映射源Map
这种方式多层嵌套,在使用过程中注意嵌套,上面标签嵌套:properties -> message -> type
XContentBuilder builder = XContentFactory.jsonBuilder(); // 使用XContentBuilder内容生成器
builder.startObject();
{
builder.startObject("properties");
{
builder.startObject("message");
{
builder.field("type", "text");
}
builder.endObject();
}
builder.endObject();
}
builder.endObject();
映射作为对象提供的源,弹性搜索内置帮助器,用于生成
JSON内容XContentBuilder
4.1.5 索引别名
- 可以在索引创建时设置别名
request.alias(new Alias("twitter_alias").filter(QueryBuilders.termQuery("user", "kimchy"))); //要定义的别名
4.1.6 提供整个源
- 前面我们都是一步一步的设置的,其实也可以提供整个源,包括其所有部分(映射、设置和别名):
request.source("{\n" +
" \"settings\" : {\n" +
" \"number_of_shards\" : 1,\n" +
" \"number_of_replicas\" : 0\n" +
" },\n" +
" \"mappings\" : {\n" +
" \"properties\" : {\n" +
" \"message\" : { \"type\" : \"text\" }\n" +
" }\n" +
" },\n" +
" \"aliases\" : {\n" +
" \"twitter_alias\" : {}\n" +
" }\n" +
"}", XContentType.JSON);
作为 JSON 字符串提供的源。它也可以作为 或 提供。MapXContentBuilder
4.1.7 可选参数
- 可以选择提供以下参数:
request.setTimeout(TimeValue.timeValueMinutes(2));
超时以等待所有节点将索引创建确认为
TimeValue
request.setMasterTimeout(TimeValue.timeValueMinutes(1));
以作为
TimeValue
request.waitForActiveShards(ActiveShardCount.from(2));
request.waitForActiveShards(ActiveShardCount.DEFAULT);
在创建索引
API返回响应之前等待的活动分片副本数,作为int
在创建索引API返回响应之前等待的活动分片副本数,作为ActiveShardCount
4.1.8 同步执行
- 以下列方式执行 时,客户端将等待 返回 ,然后再继续执行代码:
CreateIndexRequest CreateIndexResponse
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
同步调用可能会引发 在高级 REST 客户端中无法解析 REST 响应、请求会发出时间或类似情况下没有从服务器返回的响应的情况下。
IOException
在服务器返回 或 错误代码的情况下,高级客户端尝试分析响应正文错误详细信息,然后引发泛型,并将原始代码添加为抑制异常。4xx 5xx ElasticsearchExceptionResponseException
4.1.9 异步执行
- 也可以以异步方式执行 ,以便客户端可以直接返回。用户需要指定如何通过将请求和侦听器传递到异步创建索引方法来处理响应或潜在故障:
CreateIndexRequest
client.indices().createAsync(request, RequestOptions.DEFAULT, listener);
执行完成时要执行和要使用的
CreateIndexRequest ActionListener
- 异步方法不会阻止并立即返回。完成后,如果执行成功完成,则使用
onResponse方法调用 ,如果执行失败,则使用onFailure该方法。失败方案和预期异常与同步执行案例相同。ActionListener
典型的侦听器如下所示:
ActionListener<CreateIndexResponse> listener =
new ActionListener<CreateIndexResponse>() {
@Override
public void onResponse(CreateIndexResponse createIndexResponse) {
//成功执行时调用。
}
@Override
public void onFailure(Exception e) {
//当整个失败时调用
}
};
4.1.10 创建索引响应
- 返回的允许检索有关执行操作的信息,如下所示:
CreateIndexResponse
boolean acknowledged = createIndexResponse.isAcknowledged(); // <1>
boolean shardsAcknowledged = createIndexResponse.isShardsAcknowledged(); // <2>
<1> 指示所有节点是否都已确认请求
<2> 指示在计时之前是否为索引中的每个分片启动所需的分片副本数
4.2 删除索引(Delete Index Api)
4.2.1 案例:
/**
* 删除索引.
* url:https://i-code.online/
* @param args
*/
public static void main(String[] args) {
//1. 创建客户端
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
//2. 创建DeleteIndexRequest 接受 index(索引名) 参数
DeleteIndexRequest request = new DeleteIndexRequest("student");
//超时以等待所有节点确认索引删除 参数为 TimeValue 类型
request.timeout(TimeValue.timeValueMinutes(1));
//连接master节点的超时时间(使用TimeValue方式)
request.masterNodeTimeout(TimeValue.timeValueMinutes(1));
try {
// 调用delete
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.printf("isAcknowledged:%s", response.isAcknowledged());
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.2 删除索引请求
- 需要参数:
DeleteIndexRequestindex
DeleteIndexRequest request = new DeleteIndexRequest("posts");//<1> <1> 索引(index)名
<1> 索引(index)名
4.2.3 可选参数
- 可以选择提供以下参数:
request.timeout(TimeValue.timeValueMinutes(2));
request.timeout("2m");
超时以等待所有节点确认索引删除为
TimeValue类型
超时以等待所有节点确认索引删除为String类型
request.masterNodeTimeout(TimeValue.timeValueMinutes(1));//连接master节点的超时时间(使用TimeValue方式)
request.masterNodeTimeout("1m");//连接master节点的超时时间(使用字符串方式)
连接master节点的超时时间(使用TimeValue方式)
连接master节点的超时时间(使用字符串方式)
request.indicesOptions(IndicesOptions.lenientExpandOpen());
设置控制如何解析不可用的索引以及如何展开通配符表达式IndicesOptions
4.2.4 同步执行
- 以下列方式执行
DeleteIndexRequest时,客户端将等待DeleteIndexResponse返回 ,然后再继续执行代码:DeleteIndexRequestDeleteIndexResponse
AcknowledgedResponse deleteIndexResponse = client.indices().delete(request, RequestOptions.DEFAULT);
同步调用可能会引发 在高级
REST客户端中无法解析REST响应、请求会发出时间或类似情况下没有从服务器返回的响应的情况下。IOException
在服务器返回 或 错误代码的情况下,高级客户端尝试分析响应正文错误详细信息,然后引发泛型,并将原始代码添加为抑制异常。4xx 5xx ElasticsearchExceptionResponseException
4.2.5 异步执行
- 也可以以异步方式执行 ,以便客户端可以直接返回。用户需要指定如何通过将请求和侦听器传递到异步删除索引方法来处理响应或潜在故障:
DeleteIndexRequest
client.indices().deleteAsync(request, RequestOptions.DEFAULT, listener); //<1>
<1> 执行完成时要执行和要使用的DeleteIndexRequest ActionListener
异步方法不会阻止并立即返回。完成后,如果执行成功完成,则使用 ActionListener#onResponse 方法调用 ,如果执行失败,则使用 ActionListener# onFailure 该方法。失败方案和预期异常与同步执行案例相同。
典型的侦听器如下所示:delete-index
ActionListener<AcknowledgedResponse> listener =
new ActionListener<AcknowledgedResponse>() {
@Override
public void onResponse(AcknowledgedResponse deleteIndexResponse) {
//成功执行时调用。
}
@Override
public void onFailure(Exception e) {
//当整个失败时调用。DeleteIndexRequest
}
};
4.2.6 删除索引响应
- 返回的允许检索有关执行操作的信息,如下所示:
DeleteIndexResponse
boolean acknowledged = deleteIndexResponse.isAcknowledged(); //<1> 指示所有节点是否都已确认请求
<1> 指示所有节点是否都已确认请求
- 如果未找到索引,将引发 :
ElasticsearchException
try {
DeleteIndexRequest request = new DeleteIndexRequest("does_not_exist");
client.indices().delete(request, RequestOptions.DEFAULT);
} catch (ElasticsearchException exception) {
if (exception.status() == RestStatus.NOT_FOUND) {
//如果未找到要删除的索引,则进行""
}
}
如果未找到要删除的索引,则进行""
4.3 索引存在(Index Exists Api)
4.3.1 案例:
/**
* 索引是否存在Api
* url:www.i-code.online
* @param args
*/
public static void main(String[] args) {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
//创建请求
GetIndexRequest request = new GetIndexRequest("student");
//<1> 是返回本地信息还是从主节点检索状态
request.local(false);
//<2> 返回结果为适合人类的格式
request.humanReadable(true);
try {
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
} catch (IOException e) {
e.printStackTrace();
}
}
4.3.2 索引存在请求
- 高级 REST 客户端使用 “Index Exists API”。索引名称是必需的。
GetIndexRequest
GetIndexRequest request = new GetIndexRequest("twitter"); //<1> index 名称
<1> index 名称
4.3.3 可选参数
- 索引存在 API 还接受以下可选参数,通过 :
GetIndexRequest
request.local(false);//<1> 是返回本地信息还是从主节点检索状态
request.humanReadable(true); //<2> 返回结果为适合人类的格式
request.includeDefaults(false); //<3> 是否返回每个索引的所有默认设置
request.indicesOptions(indicesOptions); //<4> 控制如何解析不可用的索引以及如何展开通配符表达式
<1> 是返回本地信息还是从主节点检索状态
<2> 返回结果为适合人类的格式
<3> 是否返回每个索引的所有默认设置
<4> 控制如何解析不可用的索引以及如何展开通配符表达式
4.3.4 同步执行
- 以下列方式执行 时,客户端将等待 返回 ,然后再继续执行代码:
GetIndexRequestboolean
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
与其他同步的相同
4.3.5 异步执行
-
也可以以异步方式执行 ,以便客户端可以直接返回。用户需要指定如何通过将请求和侦听器传递到异步索引存在的方法来处理响应或潜在故障:
GetIndexRequest
client.indices().existsAsync(request, RequestOptions.DEFAULT, listener);//<1>执行完成时要执行和要使用的 GetIndexRequest ActionListener
<1>执行完成时要执行和要使用的
GetIndexRequestActionListener
异步的处理逻辑与其他异步的相同,都是实现ActionListener的方法
4.3.6 响应
- 响应是一个值,指示索引(或索引)是否存在。
boolean
5. 文档 Api (Document APIs)
5.1 索引 API (Index Api)
5.1.1 案例:
- 添加记录
private static void test02() {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
//创建请求, 参数index名称
IndexRequest request = new IndexRequest("student");
//请求的模式,CREATE: 创建模式,如果已经存在则报错 Index:存在则不再创建,也不报错
request.opType(DocWriteRequest.OpType.INDEX);
String json = "{\n" +
" \"id\": 12,\n" +
" \"name\": \"admin\",\n" +
" \"content\": \"步的处理逻辑与其他异步的相同,都是实现ActionListener 的方法\"\n" +
"}";
request.id("1").source(
json,
XContentType.JSON
);
IndexResponse indexResponse = null;
try {
//调用 index 方法
indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.getVersion());
System.out.println(indexResponse.getIndex());
System.out.println(indexResponse.getId());
System.out.println(indexResponse.status());
} catch (ElasticsearchStatusException | IOException e) {
e.printStackTrace();
}
}
5.1.2 索引请求
- 需要以下参数:
IndexRequest
//创建请求, 参数index名称
IndexRequest request = new IndexRequest("student"); //<1> index 名称
String json = "{\n" +
" \"id\": 12,\n" +
" \"name\": \"admin\",\n" +
" \"content\": \"步的处理逻辑与其他异步的相同,都是实现ActionListener 的方法\"\n" +
"}";
request
.id("1") // <2> 指定文档 ID
.source(
json,
XContentType.JSON // <3> 指定参数类型,json
);
<1> index 名称指数
<2> 请求的文档 ID
<3> 指定参数类型,json
提供文档源
- 除了上面显示的示例之外,还可以以不同的方式提供文档源:
String
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("id", 1);
jsonMap.put("name", "Admin);
jsonMap.put("content", "步的处理逻辑与其他异步的相同");
IndexRequest indexRequest = new IndexRequest("student").id("1").source(jsonMap);
文档源作为 自动转换为
JSON格式的Map
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("id", 1);
builder.field("name", "admin);
builder.field("content", "trying out Elasticsearch");
}
builder.endObject();
IndexRequest indexRequest = new IndexRequest("student").id("1").source(builder);
文档源作为对象提供,弹性搜索内置帮助器生成
JSON内容XContentBuilder
IndexRequest indexRequest = new IndexRequest("student")
.id("1")
.source("id", 1,
"name", "admin",
"content", "trying out Elasticsearch");
作为密钥对提供的文档源,该源将转换为 JSON 格式Object
5.1.3 可选参数
- 可以选择提供以下参数:
request.routing("routing"); //<1>
<1> 路由值
request.timeout(TimeValue.timeValueSeconds(1)); //<1>
request.timeout("1s"); // <2>
<1> 超时以等待主分片 作为 TimeValue
<2> 超时以等待主分片 作为 String
request.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL); //<1>
request.setRefreshPolicy("wait_for"); //<2>
<1> 将策略刷新 为实例
WriteRequest.RefreshPolicy
<2> 将策略刷新 为String
request.version(2);
版本
request.versionType(VersionType.EXTERNAL); //版本类型
版本类型
request.opType(DocWriteRequest.OpType.CREATE);//<1>
request.opType("create");//<2>
<1> 作为值提供的操作类型
DocWriteRequest.OpType
<2> 提供的操作类型可以是 或(默认)Stringcreateindex
request.setPipeline("pipeline");
在索引文档之前要执行的包含管道的名称
5.1.4 同步执行
- 以下列方式执行 时,客户端将等待 返回 ,然后再继续执行代码:
IndexRequestIndexResponse
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
- 同步调用可能会引发 在高级 REST 客户端中无法解析 REST 响应、请求会发出时间或类似情况下没有从服务器返回的响应的情况下。
IOException - 在服务器返回 或 错误代码的情况下,高级客户端尝试分析响应正文错误详细信息,然后引发泛型,并将原始代码添加为抑制异常。
4xx 5xx ElasticsearchExceptionResponseException
5.1.5 异步执行
- 也可以以异步方式执行 ,以便客户端可以直接返回。用户需要指定如何通过将请求和侦听器传递到异步索引方法来处理响应或潜在故障:
IndexRequest
client.indexAsync(request, RequestOptions.DEFAULT, listener); //<1>
<1> 执行完成时要执行和要使用的
IndexRequestActionListener
- 异步方法不会阻止并立即返回。完成后,如果执行成功完成,则使用 方法调用 ,如果执行失败,则使用 该方法。失败方案和预期异常与同步执行案例相同。
ActionListeneronResponseonFailure - 典型的侦听器如下所示:index
listener = new ActionListener<IndexResponse>() {
@Override
public void onResponse(IndexResponse indexResponse) {
//<1> 成功执行时调用。
}
@Override
public void onFailure(Exception e) {
//<2> 当整个失败时调用。IndexRequest
}
};
<1> 成功执行时调用。
<2> 当整个失败时调用。> IndexRequest
5.1.6 索引响应
- 返回的允许检索有关执行操作的信息,如下所示:
IndexResponse
String index = indexResponse.getIndex();
String id = indexResponse.getId();
if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) {
//<1>
} else if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) {
//<2>
}
ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo();
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
// <3>
}
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure :
shardInfo.getFailures()) {
String reason = failure.reason(); //<4>
}
}
<1> 处理(如果需要)首次创建文档的情况
<2> 处理(如果需要)文档被重写的情况,因为它已经存在
<3> 处理成功分片数少于总分片的情况
<4> 处理潜在的故障
- 如果存在版本冲突,将引发 :
ElasticsearchException
IndexRequest request = new IndexRequest("posts")
.id("1")
.source("field", "value")
.setIfSeqNo(10L)
.setIfPrimaryTerm(20);
try {
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
} catch(ElasticsearchException e) {
if (e.status() == RestStatus.CONFLICT) {
//<1>
}
}
<1> 引发异常指示返回版本冲突错误
- 在设置为且已存在具有相同索引和 ID 的文档的情况下,将发生相同的情况:
opTypecreate
IndexRequest request = new IndexRequest("posts")
.id("1")
.source("field", "value")
.opType(DocWriteRequest.OpType.CREATE);
try {
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
} catch(ElasticsearchException e) {
if (e.status() == RestStatus.CONFLICT) {
//<1>
}
}
<1>引发异常指示返回版本冲突错误
5.2 获取Api (Get API)
5.2.1 案例:
private static void test01(){
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
GetRequest request = new GetRequest("student");
// 为特定字段 配置 源包含
String[] includs = {"name","id","content"};
String[] excluds = {"id"};
FetchSourceContext context = new FetchSourceContext(true,includs,excluds);
request.id("1").version(2).fetchSourceContext(context);
try {
GetResponse documentFields = client.get(request, RequestOptions.DEFAULT);
if (documentFields.isExists()) {
//检索名称
System.out.println(documentFields.getIndex());
// 获取文档源的 Map 结果
System.out.println(documentFields.getSource());
// 获取源作为 Map
System.out.println(documentFields.getSourceAsMap());
// 获取源作为 bytes
System.out.println(documentFields.getSourceAsBytes());
}else {
System.out.println("不错在该数据");
}
} catch (IOException e) {
e.printStackTrace();
}
}
5.2.2 获取请求
- 需要以下参数:GetRequest
GetRequest getRequest = new GetRequest(
"posts", //<1>
"1"); //<1>
<1> 索引名称
<2> 文档 ID
5.2.3 可选参数
- 可以选择提供以下参数:
request.fetchSourceContext(FetchSourceContext.DO_NOT_FETCH_SOURCE);
禁用源检索,默认情况下启用
String[] includes = new String[]{"message", "*Date"};
String[] excludes = Strings.EMPTY_ARRAY;
FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes);
request.fetchSourceContext(fetchSourceContext);
为特定字段 配置 源包含
includes: 检索结果所包含的字段
excludes: 检索结果排除的字段
String[] includes = Strings.EMPTY_ARRAY;
String[] excludes = new String[]{"message"};
FetchSourceContext fetchSourceContext =
new FetchSourceContext(true, includes, excludes);
request.fetchSourceContext(fetchSourceContext);
为特定字段配置源排除
request.storedFields("message");
GetResponse getResponse = client.get(request, RequestOptions.DEFAULT);
String message = getResponse.getField("message").getValue();
为特定存储字段配置检索(要求字段单独存储在映射中)
检索存储的字段(要求该字段单独存储在映射中)message
request.routing("routing");
路由值
request.preference("preference");
首选项值
request.realtime(false);
将实时标志设置为(默认情况下)falsetrue
request.refresh(true);
在检索文档之前执行刷新(默认情况下)false
request.version(2);
版本
request.versionType(VersionType.EXTERNAL);
版本类型
5.2.4 同步执行
- 以下列方式执行 时,客户端将等待 返回 ,然后再继续执行代码:
GetRequestGetResponse
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
-
同步调用可能会引发 在高级 REST 客户端中无法解析 REST 响应、请求会发出时间或类似情况下没有从服务器返回的响应的情况下。IOException
-
在服务器返回 或 错误代码的情况下,高级客户端尝试分析响应正文错误详细信息,然后引发泛型,并将原始代码添加为抑制异常。4xx5xxElasticsearchExceptionResponseException
5.2.5 异步执行
- 也可以以异步方式执行 ,以便客户端可以直接返回。用户需要指定如何通过将请求和侦听器传递到异步获取方法来处理响应或潜在故障:
GetRequest
client.getAsync(request, RequestOptions.DEFAULT, listener);
执行完成时要执行和要使用的
GetRequestActionListener
-
异步方法不会阻止并立即返回。完成后,如果执行成功完成,则使用 方法调用 ,如果执行失败,则使用 该方法。失败方案和预期异常与同步执行案例相同。ActionListeneronResponseonFailure
-
典型的侦听器如下所示:
get
ActionListener<GetResponse> listener = new ActionListener<GetResponse>() {
@Override
public void onResponse(GetResponse getResponse) {
//成功执行时调用
}
@Override
public void onFailure(Exception e) {
//当整个失败时调用。GetRequest
}
};
5.2.6 获取响应
- 返回的允许检索请求的文档及其元数据和最终存储的字段。
GetResponse
String index = getResponse.getIndex();
String id = getResponse.getId();
if (getResponse.isExists()) {
long version = getResponse.getVersion();
String sourceAsString = getResponse.getSourceAsString(); // <1>
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap(); // <2>
byte[] sourceAsBytes = getResponse.getSourceAsBytes(); // <3>
} else {
// <4>
}
<1> 将文档检索为
String
<2> 将文档检索为Map<String, Object>
<3> 将文档检索为byte[]
<4> 处理找不到文档的方案。请注意,尽管返回的响应具有状态代码,但返回的是有效的,而不是引发异常。此类响应不保存任何源文档,其方法将返回。404 GetResponseisExistsfalse
- 当对不存在的索引执行 get 请求时,响应具有状态代码,即需要按如下方式处理的已引发请求:
404 ElasticsearchException
GetRequest request = new GetRequest("does_not_exist", "1");
try {
GetResponse getResponse = client.get(request, RequestOptions.DEFAULT);
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
//<1> 处理引发异常,因为索引不存在
}
}
<1> 处理引发异常,因为索引不存在
- 如果请求了特定的文档版本,并且现有文档具有不同的版本号,则引发版本冲突:
try {
GetRequest request = new GetRequest("posts", "1").version(2);
GetResponse getResponse = client.get(request, RequestOptions.DEFAULT);
} catch (ElasticsearchException exception) {
if (exception.status() == RestStatus.CONFLICT) {
// <1>
}
}
<1> 引发异常指示返回版本冲突错误
6. 结语
其实很多 Api 的使用都是类似相同的,这里我们不再对其他 Api 进行解析,需要了解的完全可以去光网文档查看,文档地址在问上涨上面有。
附录
Elasticsearch7.X为什么移除类型(type)
Elasticsearch7.X为什么移除类型(type)
Elasticsearch7.X为什么移除类型(type)在Elasticsearch7.0.0及以后版本不再接受_default_ 映射。在6.x里创建的索引依然像在Elasticsearch6.X之前一样起作用。Types在7.0的API里是被舍弃的,在创建索引,设置映射,获取映射,设置模板,获取模板,获取字段映射API有着不兼容的改变。
什么是类型(type)?
从Elasticsearch的第一个发布版本以来,每一个文档都被存储在一个单独的索引里,并被赋予了一个type,一个映射类型代表着一个被索引的文档或实体的类型,例如,一个twitter索引可能有一个user类型和tweet类型。
每种映射类型都有他自己的字段,所以user类型可能有一个full_name字段,一个user_name字段和一个email字段,而一个tweet类型可能有一个content字段,一个tweet_at字段,和user类型一样一个user_name字段。
每一个文档类型都有一个_type元字段来存储type名称,并且根据URL里指定的类型名称,查询(搜索)被限定在一个或多个类型(type)里:
GET twitter/user,tweet/_search
{
"query": {
"match": {
"user_name": "kimchy"
}
}
}
_type字段用来和文档的_id字段联合生成_uid字段,所以有着相同_id的不同类型的文档可以存在同一个索引里。类型也用来建立文档间的父子关系,所以question类型的文档可能是anser类型文档的父文档。
为什么类型被移除了?
起初,我们说"索引"和关系数据库的“库”是相似的,“类型”和“表”是对等的。
这是一个不正确的对比,导致了不正确的假设。在关系型数据库里,"表"是相互独立的,一个“表”里的列和另外一个“表”的同名列没有关系,互不影响。但在类型里字段不是这样的。
在一个Elasticsearch索引里,所有不同类型的同名字段内部使用的是同一个lucene字段存储。也就是说,上面例子中,user类型的user_name字段和tweet类型的user_name字段是存储在一个字段里的,两个类型里的user_name必须有一样的字段定义。
这可能导致一些问题,例如你希望同一个索引中"deleted"字段在一个类型里是存储日期值,在另外一个类型里存储布尔值。
最后,在同一个索引中,存储仅有小部分字段相同或者全部字段都不相同的文档,会导致数据稀疏,影响Lucene有效压缩数据的能力。
因为这些原因,我们决定从Elasticsearch中移除类型的概念。
Elasticsearch 移除 type 之后的新姿势
随着 7.0 版本的即将发布,type 的移除也是越来越近了,在 6.0 的时候,已经默认只能支持一个索引一个 type 了,7.0 版本新增了一个参数 include_type_name ,即让所有的 API 是 type 相关的,这个参数在 7.0 默认是 true,不过在 8.0 的时候,会默认改成 false,也就是不包含 type 信息了,这个是 type 用于移除的一个开关。
让我们看看最新的使用姿势吧,当 include_type_name 参数设置成 false 后:
- 索引操作:PUT {index}/{type}/{id}
需要修改成PUT {index}/_doc/{id} - Mapping 操作:
PUT {index}/{type}/_mapping则变成PUT {index}/_mapping - 所有增删改查搜索操作返回结果里面的关键字
_type都将被移除 - 父子关系使用
join字段来构建
#创建索引
PUT twitter
{
"mappings": {
"_doc": {
"properties": {
"type": { "type": "keyword" },
"name": { "type": "text" },
"user_name": { "type": "keyword" },
"email": { "type": "keyword" },
"content": { "type": "text" },
"tweeted_at": { "type": "date" }
}
}
}
}
#修改索引
PUT twitter/_doc/user-kimchy
{
"type": "user",
"name": "Shay Banon",
"user_name": "kimchy",
"email": "shay@kimchy.com"
}
#搜索
GET twitter/_search
{
"query": {
"bool": {
"must": {
"match": {
"user_name": "kimchy"
}
},
"filter": {
"match": {
"type": "tweet"
}
}
}
}
}
#重建索引
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
详尽的 Elasticsearch7.X 安装及集群搭建教程
简介
首先引用 Elasticsearch (下文简称 ES)官网的一段描述:
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
本文主要介绍 Elasticsearch 集群的搭建。通过在一台服务器上创建 3 个 ES 实例来创建一个建议的 ES 集群。
Elasticsearch/ES
官方的Elasticsearch Reference 提供了不同版本的文档连接,真是赞!
如果英文的不想看,还提供了中文版的 Elasticsearch 2.x: 权威指南,版本不是最新的,但是了解基本概念也是有帮助的。
Elasticsearch 7.x 包里自包含了 OpenJDK 的包。如果你想要使用你自己配置好的 Java 版本,需要设置 JAVA_HOME 环境变量 —— 参考
官方文档 Set up Elasticsearch 有各个 OS 的安装指导,页面 Installing Elasticsearch 中提供了多种安装包对应的指导链接!
本文选择绿色安装包的的方式(tar.gz)安装。
由于实验机器有限,可以在同一台机器上模拟出 3 个节点,安装 ES 集群。
安装 ES
准备工作
{% note warning %}
不能使用 root 用户启动 es,否则会报错:
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
{% endnote %}
如果需要新建用户的话可以运行 sudo adduser es,修改 es 用户的密码:sudo passwd es。
下载 ES 安装包
安装包下载地址:
- 官方-Past Releases 官网的下载速度龟速
- 华为镜像站 下载速度不错,推荐
下面的步骤参考 Set up Elasticsearch » Installing Elasticsearch » Install Elasticsearch from archive on Linux or MacOS,选择的安装包是 elasticsearch-7.3.0 版本。
下载安装包
wget https://mirrors.huaweicloud.com/elasticsearch/7.3.0/elasticsearch-7.3.0-linux-x86_64.tar.gz
wget https://mirrors.huaweicloud.com/elasticsearch/7.3.0/elasticsearch-7.3.0-linux-x86_64.tar.gz.sha512
# 验证安装包的完整性,如果没问题,会输出 OK
shasum -a 512 -c elasticsearch-7.3.0-linux-x86_64.tar.gz.sha512
tar -xzf elasticsearch-7.3.0-linux-x86_64.tar.gz
# 将目录复制三份,作为三个节点,后面配置 ES 集群时,对应了三个 ES 实例
cp -R elasticsearch-7.3.0 es-7.3.0-node-1
cp -R elasticsearch-7.3.0 es-7.3.0-node-2
mv elasticsearch-7.3.0 es-7.3.0-node-3
# 因为以 root 用户启动不了 ES
chown -R es es-7.3.0*
{% note info %}
如果是 Mac 平台,则下载包 elasticsearch-{version}-darwin-x86_64.tar.gz。
MacOS Catalina 在你第一次运行 ES 时,会弹出对话框阻止运行,你需要到设置-》安全隐私中允许才行。为了阻止这种告警,可以运行如下的命令:xattr -d -r com.apple.quarantine <$ES_HOME or archive-or-directory>
{% endnote %}
$ES_HOME 是指 ES 的安装包 tar 包解压后的文件夹目录。
解压后的目录组成:
.
├── bin # 二进制脚本存放目录,包括 elasticsearch 来指定运行一个 node,包括 elasticsearch-plugin 来安装 plugins
├── config # 包含了 elasticsearch.yml 配置文件
├── data # 节点上分配的每个 index/分片 的数据文件
├── lib
├── LICENSE.txt
├── logs
├── modules
├── NOTICE.txt
├── plugins # 插键文件存放的位置
└── README.textile
运行 Elasticsearch
我们先运行一个节点,创建 ES 单机版实例:
./bin/elasticsearch
如果要将 ES 作为守护程序运行,请在命令行中指定 -d,指定 -p 参数,将进程 ID 记录到 pid 文件:
./bin/elasticsearch -d -p pid
日志在 $ES_HOME/logs 目录中。
如果要停止 ES,运行如下的命令:
pkill -F pid
检查一下运行状态
curl -X GET "localhost:9200/?pretty"
或者在浏览器中访问 localhost:9200 都可以,会返回:
{
"name": "node-1",
"cluster_name": "appsearch-7.3.2",
"cluster_uuid": "GlzI_v__QJ2s9ewAgomOqg",
"version": {
"number": "7.3.0",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "de777fa",
"build_date": "2019-07-24T18:30:11.767338Z",
"build_snapshot": false,
"lucene_version": "8.1.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
如果你是在远端服务器上部署的 ES,那么,此时在你本地的工作机上还无法调通 :9200,需要对 ES 进行相关配置才能访问,下文会介绍。
ES 配置相关
官网关于配置的内容主要有两处:
Elasticsearch 主要有三个配置文件:
配置文件主要位于 $ES_HOME/config 目录下,也可以通过 ES_PATH_CONF 环境变量来修改
YAML 的配置形式参考:
path:
data: /var/lib/elasticsearch
logs: /var/log/elasticsearch
设置也可以按如下方式展平:
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
JVM 配置
JVM 参数设置可以通过 jvm.options 文件(推荐方式)或者 ES_JAVA_OPTS 环境变量来修改。
jvm.options 位于
$ES_HOME/config/jvm.options 当通过 tar or zip 包安装
/etc/elasticsearch/jvm.options 当通过 Debian or RPM packages
官网也介绍了如何设置堆大小。
默认情况,ES 告诉 JVM 使用一个最小和最大都为 1GB 的堆。但是到了生产环境,这个配置就比较重要了,确保 ES 有足够堆空间可用。
ES 使用 Xms(minimum heap size) 和 Xmx(maxmimum heap size) 设置堆大小。你应该将这两个值设为同样的大小。
Xms 和 Xmx 不能大于你物理机内存的 50%。
设置的示例:
-Xms2g
-Xmx2g
elasticsearch.yml 配置
ES 默认会加载位于 $ES_HOME/config/elasticsearch.yml 的配置文件。
备注:任何能够通过配置文件设置的内容,都可以通过命令行使用 -E 的语法进行指定,例如:
./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_1
cluster.name
cluster.name 设置集群名称。一个节点只能加入一个集群中,默认的集群名称是 elasticsearch。
cluster.name: search-7.3.2
{% note info %}
确保节点的集群名称要设置正确,这样才能加入到同一个集群中。上面示例就自定义了集群名称为 appsearch-7.3.2。
{% endnote %}
node.name
node.name:可以配置每个节点的名称。用来提供可读性高的 ES 实例名称,它默认名称是机器的 hostname,可以自定义:
node.name: node-1
同一集群中的节点名称不能相同
network.host
network.host:设置访问的地址。默认仅绑定在回环地址 127.0.0.1 和 [::1]。如果需要从其他服务器上访问以及多态机器搭建集群,我们需要设定 ES 运行绑定的 Host,节点需要绑定非回环的地址。建议设置为主机的公网 IP 或 0.0.0.0:
network.host: 0.0.0.0
更多的网络设置可以阅读 Network Settings
http.port
http.port 默认端口是 9200 :
http.port: 9200
{% note warning %}
注意:这是指 http 端口,如果采用 REST API 对接 ES,那么就是采用的 http 协议
{% endnote%}
transport.port
REST 客户端通过 HTTP 将请求发送到您的 Elasticsearch 集群,但是接收到客户端请求的节点不能总是单独处理它,通常必须将其传递给其他节点以进行进一步处理。它使用传输网络层(transport networking layer)执行此操作。传输层用于集群中节点之间的所有内部通信,与远程集群节点的所有通信,以及 Elasticsearch Java API 中的 TransportClient。
transport.port 绑定端口范围。默认为 9300-9400
transport.port: 9300
因为要在一台机器上创建是三个 ES 实例,这里明确指定每个实例的端口。
discovery.seed_hosts
discovery.seed_hosts:发现设置。有两种重要的发现和集群形成配置,以便集群中的节点能够彼此发现并且选择一个主节点。官网/Important discovery and cluster formation settings
discovery.seed_hosts 是组件集群时比较重要的配置,用于启动当前节点时,发现其他节点的初始列表。
开箱即用,无需任何网络配置, ES 将绑定到可用的环回地址,并将扫描本地端口 9300 - 9305,以尝试连接到同一服务器上运行的其他节点。 这无需任何配置即可提供自动群集的体验。
如果要与其他主机上的节点组成集群,则必须设置 discovery.seed_hosts,用来提供集群中的其他主机列表(它们是符合主机资格要求的master-eligible并且可能处于活动状态的且可达的,以便寻址发现过程)。此设置应该是群集中所有符合主机资格的节点的地址的列表。 每个地址可以是 IP 地址,也可以是通过 DNS 解析为一个或多个 IP 地址的主机名(hostname)。
当一个已经加入过集群的节点重启时,如果他无法与之前集群中的节点通信,很可能就会报这个错误 master not discovered or elected yet, an election requires at least 2 nodes with ids from。因此,我在一台服务器上模拟三个 ES 实例时,这个配置我明确指定了端口号。
配置集群的主机地址,配置之后集群的主机之间可以自动发现(可以带上端口,例如 127.0.0.1:9300):
discovery.seed_hosts: [“127.0.0.1:9300”,“127.0.0.1:9301”]
the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
必须至少配置 [discovery.seed_hosts,discovery.seed_providers,cluster.initial_master_nodes] 中的一个。
cluster.initial_master_nodes
cluster.initial_master_nodes: 初始的候选 master 节点列表。初始主节点应通过其 node.name 标识,默认为其主机名。确保 cluster.initial_master_nodes 中的值与 node.name 完全匹配。
首次启动全新的 ES 集群时,会出现一个集群引导/集群选举/cluster bootstrapping步骤,该步骤确定了在第一次选举中的符合主节点资格的节点集合。在开发模式下,如果没有进行发现设置,此步骤由节点本身自动执行。由于这种自动引导从本质上讲是不安全的,因此当您在生产模式下第一次启动全新的群集时,你必须显式列出符合资格的主节点。也就是说,需要使用 cluster.initial_master_nodes 设置来设置该主节点列表。重新启动集群或将新节点添加到现有集群时,你不应使用此设置
在新版 7.x 的 ES 中,对 ES 的集群发现系统做了调整,不再有 discovery.zen.minimum_master_nodes 这个控制集群脑裂的配置,转而由集群自主控制,并且新版在启动一个新的集群的时候需要有 cluster.initial_master_nodes 初始化集群主节点列表。如果一个集群一旦形成,你不该再设置该配置项,应该移除它。该配置项仅仅是集群第一次创建时设置的!集群形成之后,这个配置也会被忽略的!
{% note warning %}cluster.initial_master_nodes 该配置项并不是需要每个节点设置保持一致,设置需谨慎,如果其中的主节点关闭了,可能会导致其他主节点也会关闭。因为一旦节点初始启动时设置了这个参数,它下次启动时还是会尝试和当初指定的主节点链接,当链接失败时,自己也会关闭!
因此,为了保证可用性,预备做主节点的节点不用每个上面都配置该配置项!保证有的主节点上就不设置该配置项,这样当有主节点故障时,还有可用的主节点不会一定要去寻找初始节点中的主节点!
{% endnote%}
关于 cluster.initial_master_nodes 可以查看如下资料:
Bootstrapping a cluster
Discovery and cluster formation settings
其他
集群的主要配置项上面已经介绍的差不多了,同时也给出了一些文档拓展阅读。实际的生产环境中,配置稍微会复杂点,下面补充一些配置项的介绍。需要说明的是,下面的一些配置即使不配置,ES 的集群也可以成功启动的。
Elasticsearch 集群中节点角色的介绍 对上文中的 node.master 等配置做了介绍。如果本地仅是简单测试使用,上文中的 node.master/node.data/node.ingest 不用配置也没影响。
创建集群实验机器有限,我们在同一台机器上创建三个 ES 实例来创建集群,分别明确指定了这些实例的 http.port 和 transport.port。discovery.seed_hosts明确指定实例的端口对测试集群的高可用性很关键。
如果后期有新节点加入,新节点的 discovery.seed_hosts 没必要包含所有的节点,只要它里面包含集群中已有的节点信息,新节点就能发现整个集群了。
集群配置预览
分别进入es-7.3.0-node-1、es-7.3.0-node-2 和 es-7.3.0-node-3 的文件夹,config/elasticsearch.yml 设置如下:
# es-7.3.0-node-1
cluster.name: search-7.3.2
node.name: node-1
node.master: true
node.data: false
node.ingest: false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
cluster.initial_master_nodes: ["node-1"]
# es-7.3.0-node-2
cluster.name: search-7.3.2
node.name: node-2
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9201
transport.port: 9301
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
# es-7.3.0-node-3
cluster.name: search-7.3.2
node.name: node-3
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9202
transport.port: 9302
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
node-1 节点仅仅是一个 master 节点,它不是一个数据节点。
经过上面的配置,可以通过命令 egrep -v “#|$” config/elasticsearch.yml 检查配置项。
先启动 node-1 节点,因为它设置了初始主节点的列表。这时候就可以使用 http://:9200/ 看到结果了。然后逐一启动 node-2 和 node-3。通过访问 http://127.0.0.1:9200/_cat/nodes 查看集群是否 OK:
192.168.3.112 25 87 13 4.29 dm - node-3
192.168.3.112 26 87 16 4.29 dm - node-2
192.168.3.112 35 87 16 4.29 m * node-1
http://127.0.0.1:9200/_nodes 将会显示节点更多的详情信息
插键显示结果:

五角星表示该节点是主节点,圆圈表示该节点是数据节点
有没有发现,我并没有给 node-2 和 node-3 明确指定端口,为什么在一台机器上也成功启动了这两个节点?
因为 Elasticsearch 会取用 9200~9299 这个范围内的端口,如果 9200 被占用,就选择 9201,依次类推。
补充:其实,还有一个简单的方法模拟创建集群(该方法我未测试,仅供参考)。
我们首先将上面运行的三个节点停止掉,然后进入 es-7.3.0-node-1 文件夹下:
mkdir -p data/data{1,2,3}
./bin/elasticsearch -E node.name=node-1 -E cluster.name=appsearch-7.3.2 -E path.data=data/data1 -E path.logs=logs/logs1 -d -p pid1
./bin/elasticsearch -E node.name=node-2 -E cluster.name=appsearch-7.3.2 -E path.data=data/data2 -E path.logs=logs/logs2 -E http.port=9201 -d -p pid2
./bin/elasticsearch -E node.name=node-3 -E cluster.name=appsearch-7.3.2 -E path.data=data/data3 -E path.logs=logs/logs3 -E http.port=9202 -d -p pid3
安装插键
./bin/elasticsearch-plugin install analysis-icu
如果插键安装慢,可以先下载下来,再安装:
Q1:[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
echo "vm.max_map_count=262144" > /etc/sysctl.conf
sysctl -p
Q2:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
sudo vim /etc/security/limits.conf
加入以下内容
* soft nofile 300000
* hard nofile 300000
* soft nproc 102400
* soft memlock unlimited
* hard memlock unlimited
Q3:master_not_discovered_exception
主节点指定的名字要保证存在,别指定了不存在的节点名。
总结
本文是通过 tar 包方式安装的,安装目录相对集中、配置方便。用 RPM 包安装的话,可以直接用 systemctl 的命令查看 ES 状态、对其重启等。
参考
Elasticsearch基础语法
learnku/Elasticsearch中文文档-7.3版本 推荐
ES-CN 官网/Elasticsearch 集群协调迎来新时代 对于 ES7 的集群发现机制介绍较为详细,推荐
程序羊-CentOS7上ElasticSearch安装填坑记 FAQ 有帮助
搭建ELFK日志采集系统
静觅—Ubuntu 搭建 Elasticsearch 6 集群流程
ELK 架构之 Elasticsearch 和 Kibana 安装配置
使用 ELK(Elasticsearch + Logstash + Kibana) 搭建日志集中分析平台实践
手把手教你,在CentOS上安装ELK,进行服务器日志收集
本文基于Elasticsearch7.X及以上版本,7以下版本注意在操作索引和文档时或需要添加_doc字段
一、Rest语法概述
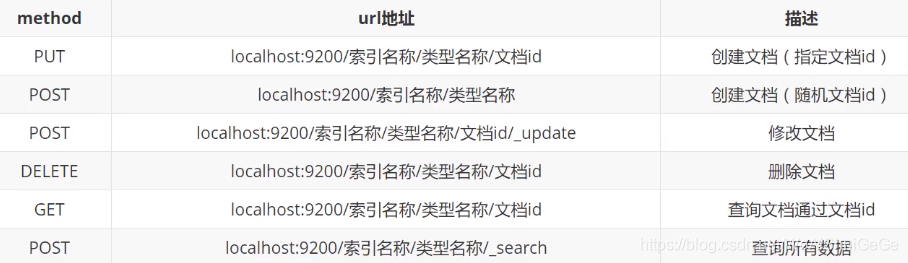
二、索引管理
1. 创建索引
PUT /index_name
{
"settings": {
"number_of_shards":2,
"number_of_replicas":1
},
"mappings": {
"properties": {
"id":{
"type": "integer"
},
"name":{
"type": "keyword"
},
"age":{
"type": "long"
},
"desc":{
"type": "text"
},
"birthday":{
"type": "date"
}
}
}
}
settings设置有好多,上面只写了分片和副本数量。
2. 修改索引字段
注:只能新增字段,不能删除字段
POST /index_name/_mapping
{
"properties": {
"title":{
"type": "text"
}
}
}
3. 删除索引
DELETE /index_name
4. 查看索引字段类型
GET /index_name/_mapping
5. 索引数据转移,旧索引数据复制到新索引
POST /_reindex
{
"source": {
"index": "index_name_old"
},
"dest": {
"index": "index_name_new",(提前创建好)
"version_type": "external"
}
}
6. 查看索引列表-健康状态
GET _cat/health
7. 查看索引列表-详细信息
GET _cat/indices?v
8. 查看ik分词情况
GET _analyze
{
"analyzer": "ik_smart",
"text": "支付就用支付宝"
}
9. 查看ik分词,最细粒度划分
GET _analyze
{
"analyzer": "ik_max_word",
"text": "支付就用支付宝"
}
三、文档管理
1. 创建文档PUT/POST
区别:put文档必须要指定文档_id;post可指定,可不指定,不指定则会随机生成一个_id
**情况1:**如果没有提前设定索引中字段类型而直接添加文档,es会对字段数据给自动数据类型,新字段会永久补充进去mapping。
**情况2:**如果添加的数据字段数量大于提前设定索引中字段数量,可成功,按情况1处理。
**情况3:**如果添加的数据字段数量小于提前设定索引中字段数量,更可成功。
put指定id
PUT /index_name/_doc/1
{
"id":1001,
"name":"张三",
"age":12,
"desc":"我的自我描述",
"birthday":"2020-02-02"
}
post指定id
POST /index_name/_doc/3
{
"id":1002,
"name":"张三",
"age":12,
"desc":"我的自我描述",
"birthday":"2020-02-02"
}
post不指定id,自动给_id
POST /index_name/_doc
{
"id":1003,
"name":"张三",
"age":12,
"desc":"我的自我描述",
"birthday":"2020-02-02"
}
2. 查询文档
查询所有文档
GET /index_name/_search
查询指定文档
GET /index_name/_doc/1
3. 修改文档
全修改:PUT和POST都可以,全部字段均会被修改更新
POST /index_name/_doc/1
{
"id":1005,
"name":"张三",
"age":12,
"desc":"我的自我描述",
"birthday":"2020-02-02"
}
部分修改:POST,只修改部分字段数据
POST /index_name/_doc/1/_update
{
"doc":{
"name":"李四"
}
}
4. 删除文档
根据id删除指定文档
DELETE /index_name/_doc/1
5.清空指定索引全部文档
POST index_name/_delete_by_query
{
"query": {"match_all": {}}
}
根据查询条件清理部分文档
POST index_name/_delete_by_query
{
"query":{
"bool":{
"filter":[
{
"range":{
"birthday":{
"gte":"2020-06-01 00:00:00",
"lt":"2020-07-01 00:00:00"
}
}
}
]
}
}
}
四、复杂查询
语句条件:match匹配查询、bool联合查询、term精确查询
约束条件:must、must_not、should、filter
1. match匹配查询
首先我拿match对desc查询,因为desc是text类型可以进行分词查询;name是keyword不分词,不支持分词查询。
实测,下面的查询结果会查询到desc中包含"%张%" 或 “%三%” 或 "%李%"的文档。
注:张三不是一个词,会被分词器给分开,哇。。。。这样岂不是能查很多,确实,尽量少用match查询text,不够精准。
GET /index_name/_search
{
"query":{
"match":{
"desc":"张三 李"
}
}
}
2. bool联合查询,通常搭配must,should,must_not,filter
(1)must、must_not 条件查询,必须满足,类似mysql中and的用法
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"desc":"三 四"
}
},
{
"match": {
"age": 12
}
}
]
}
}
}
(2)should 条件查询,需要满足,并且是或者的关系,类似mysql中or的用法
GET /index_name/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"desc":"三 四"
}
},
{
"match": {
"age": 12
}
}
]
}
}
}
(3)filter 过滤查询
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"desc":"三 四"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 10,
"lt": 13
}
}
}
]
}
}
}
3. term精确查询: 通过倒排索引进行精确查找,用的最多
·match原理是先分析文档,通过分词器进行解析,然后再去文档中查询。
·term直接进行精确查询,term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词拆解。
·match_phrase短语搜索,要求所有的分词必须同时出现在文档中,同时位置必须紧邻一致。
(1)简单查询
GET /index_name/_search
{
"query": {
"term": {
"desc":"三"
}
}
}
(2)多条件复合查询
注:term不会分词查询,只是精确查询!!!必须要查满足 “小三” 的文档
GET /index_name/_search
{
"query":{
"bool":{
"must": [
{
"term": {
"desc": "小三"
}
},
{
"term": {
"age": 11
}
}
]
}
}
}
terms表示多条件并列,用大括号 [ ] 涵盖所查内容,类似于MySql中in方法
GET /index_name/_search
{
"query":{
"bool":{
"must": [
{
"terms": {
"age": [
10,11,12
]
}
}
]
}
}
}
或者
GET /index_name/_search
{
"query":{
"bool":{
"must": [
{
"terms": {
"desc": [
"我","三"
]
}
}
]
}
}
}
多重混合,这个也是用到较多的
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"term":{
"desc":"三"
}
},
{
"terms":{
"age":[
10,
11,
12
]
}
}
]
}
}
}
must和must_not混合,这里面留意区别下term 和 match条件的不同含义
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"term":{
"name":"张三"
}
}
],
"must_not":[
{
"term":{
"age":"10"
}
},
{
"match":{
"desc":"描述"
}
}
]
}
}
}
尤其注意must和should并列的情况:must和should不可以直接并列,must和must_not可以直接并列
假如,要查姓名叫“张三”,年龄为12岁或者出生日期为2020-02-03的个人信息,一定要注意了。
就好比: name=张三 && age=15 || birthday=2020-02-03这种错误一样,这是不对的。逻辑上似乎说的过去,但在严谨的数学上可不行,并且就算在mysql中也不可以这么写,因为and优先级大于or,会先执行and并列条件,好在mysql中可以将条件括起来,改正为 where name=‘张三’ and (age=12 or birthday=‘2020-02-03’)。
错误的写法: 即便是把age和birthday都放在should里面,elasticsearch也不认。
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"张三"
}
}
],
"should":[
{
"match":{
"age":"12"
}
},
{
"match":{
"birthday":"2020-02-03"
}
}
]
}
}
}
正确的逻辑是:(name=张三 && age=15) || (name=张三 &&birthday=2020-02-03),
正确的写法:先对should分出情况,再给每一种情况进行must约束
GET /index_name/_search
{
"query":{
"bool":{
"should":[
{
"bool":{
"must":[
{
"term":{
"name":"张三"
}
},
{
"term":{
"age":12
}
}
]
}
},
{
"bool":{
"must":[
{
"term":{
"name":"张三"
}
},
{
"term":{
"birthday":"2020-02-03"
}
}
]
}
}
]
}
}
}
4. 聚合查询collapse和aggs,将重复内容进行折叠(去重)
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"term":{
"moduleAttr":6424
}
},
{
"terms":{
"sortId":[1,72,101]
}
}
],
"filter":[
{
"range":{
"pubTime":{
"gte":"2020-07-11 09:13:04"
}
}
}
]
}
},
"sort":[
{
"pubTime":{
"order":"desc"
}
}
],
"collapse":{
"field":"contentId"
},
"size":20
}
或者
GET index_name/_search
{
"query":{
"bool":{
"must":{
"terms":{
"websiteId":[
2141391797
]
}
},
"filter":{
"range":{
"pubTime":{
"gte":"2020-04-20 00:00:00",
"lte":"2020-07-31 23:59:59"
}
}
}
}
},
"aggs": {
"my_name(自定义名字)": {
"terms": {
"field": "contentId"
}
}
},
"size":10
}
5. 高亮查询
默认高亮格式查询
GET /index_name/_search
{
"query":{
"match":{
"desc":"自我描述"
}
},
"highlight": {
"fields": {
"desc": {}
}
}
}
自定义高亮代码
GET /index_name/_search
{
"query":{
"match":{
"desc":"自我描述"
}
},
"highlight": {
"pre_tags": "<p style='color:red'>" ,
"post_tags": "</p>",
"fields": {
"desc": {}
}
}
}
6. 最后说几个常用查询筛选条件:
从上到下,分别是只显示需要返回的字段、查询条件、排序规则、分页从0页开始size为2
GET /index_name/_search
{
"_source":{
"includes":[
"name",
"age",
"desc"
]
},
"query":{
"match":{
"name":"张三"
}
},
"sort":[
{
"age":{
"order":"desc"
}
}
],
"from": 0,
"size": 2
}
五、复杂条件修改/删除
1. 条件修改_update_by_query
将desc中含有“三”的数据,desc修改为“张3新的自我介绍”。
POST /index_name/_update_by_query
{
"script":{
"source":"ctx._source['desc']='张3新的自我介绍'"
},
"query":{
"bool":{
"must":[
{
"term":{
"desc":"三"
}
}
]
}
}
}
2. 条件删除_delete_by_query
将desc中含有“3”的数据删除
POST /index_name/_delete_by_query
{
"query":{
"bool":{
"must":[
{
"term":{
"desc":"3"
}
}
]
}
}
}
3.清空索引数据
POST /index_name/_delete_by_query
{
"query": {"match_all": {}}
}
六、Elasticsearch Painless Script
官网解释,自Elasticsearch 5.x 引入Painless,使得Elasticsearch拥有了安全、可靠、高性能脚本的解决方案。
简单来说就是支持通过Painless脚本语言的方式,对es进行查询、修改、删除等操作,为es提供了更强大的一种操作方式。
doc只可以在_search中访问到。如果是修改操作,使用的是ctx。
https://blog.csdn.net/u013613428/article/details/78134170#%E6%89%B9%E9%87%8F%E6%9B%B4%E6%96%B0
1. 条件修改
POST /index_name/_update_by_query
{
"script":{
"lang":"painless",
"source":"ctx._source.title=params.newTitile",
"params":{
"newTitile":"修改为新的titile"
}
},
"query":{
"bool":{
"filter":[
{
"range":{
"crawlTime":{
"gte":"2020-09-01 00:00:00",
"lt":"2020-09-03 00:00:00"
}
}
}
]
}
}
}
或者修改title,在titile后面加一句“加一个后缀”
POST /index_name/_update_by_query
{
"script":{
"lang":"painless",
"source":"ctx._source.title= ctx._source.title+'加一个后缀'"
},
"query":{
"bool":{
"filter":[
{
"range":{
"crawlTime":{
"gte":"2020-09-01 00:00:00",
"lt":"2020-09-03 00:00:00"
}
}
}
]
}
}
}
不过这里我也遇到个问题,根据官网文档,我想replace修改keyword字段,但报错,不知道有没有大神可以解释的。
七、集群管理
1. 查看集群的基本健康状态
GET /_cat/health?v
2. 查看集群详细状态
GET _cluster/health?pretty
3. 查看集群中所有的分片
GET /_cat/shards
** 4. 查看集群所有节点**
GET /_cat/nodes?v
5. 查看集群所有节点详细信息
GET _nodes/process?pretty
八、生命周期管理
生命周期也可以在kibana中可视化操作
1. 创建生命周期
#(自定义生命周期名称article_ilm_policy)
PUT /_ilm/policy/article_ilm_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_docs":"50000000"
}
}
},
"warm":{
"min_age":"15d",
"actions":{
"allocate":{
"include":{
"box_type":"warm"
},
"number_of_replicas":0
},
"forcemerge":{
"max_num_segments":1
}
}
},
"cold":{
"min_age":"30d",
"actions":{
"allocate":{
"include":{
"box_type":"cold"
}
}
}
},
"delete":{
"min_age":"60d",
"actions":{
"delete":{
}
}
}
}
}
}
2. 查看生命周期
GET /_ilm/policy/article_ilm_policy
3. 删除生命周期
DELETE /_ilm/policy/article_ilm_policy
4. 索引rollover操作
POST index_name/_rollover/
{
"conditions": {
"max_docs": 1000,
"max_age": "7d",
"max_size": "5gb"
}
}
九、索引模板管理
索引模板也可以在kibana中可视化操作
1. 查看当前所有模板
GET _template
2. 查看指定模板规则
GET _template/article_ilm_template
3. 创建模板,
当然模板中settings不仅下面这些属性配置,还可指定分词器analysis、过滤器等,下述为基础简单配置。
//设定索引模板
PUT /_template/article_ilm_template
{
"index_patterns":[
"article*"(索引匹配规则,满足article为前缀的索引以此模板创建,这个要写好,瞎写或者写复杂了容易导致索引找不到模板)
],
"aliases": {
"article": {}(规定新索引的别名,这里有bug,如果写上这个索引别名,但滚动索引会跟下面rollover_alias重复冲突,引起rollover失败,建议不写这个配置,第一个索引采用手动创建别名)
},
"settings":{
"number_of_shards":9,(主分片数)
"number_of_replicas":1,(副本数)
"index.lifecycle.name":"article_ilm_policy",(规定索引遵从哪个生命周期)
"index.lifecycle.rollover_alias":"article",(规定rollover索引别名)
"index.routing.allocation.include.box_type":"hot",(让所有符合命名规则索引的 Shard 都将被分配到 Hot Nodes 节点上)
},
"mappings":{
"properties":{
"title":{
"type":"text"
}
}
}
}
4. 别名
//写入和读取,都是根据共同的别名article进行的,他们别名一样
//设置别名,如果别名不对的话,就无法查询到此article-test索引
//设置允许写入写入"is_write_index":true ,否则无法写入数据,集群只能规定一个写入的索引
//创建索引,指定别名
PUT article-test(需要修改的索引)
{
"aliases":{
"article(别名)":{
"is_write_index":true
}
}
}
//另一种写法,修改别名,指定索引:
POST /_aliases
{
"actions":[
{
"add":{
"index":"article-test",(需要修改的索引)
"alias":"article",(别名)
"is_write_index":true
}
}
]
}
5.路由索引
路由决定如何分配文档到各个节点,默认路由是文档的_id,通过将_id算法取余保证平均散步数据。
shard_num = hash(_routing) % num_primary_shards
但是如果查很久之前比如1年前的数据,那就要从1年前时间开始查询所有节点至今的数据量,其实也没毛病,但消耗大。
这时候可以用路由进行优化,设定路由参数,如同给文档打标签一样,将带有相同路由的文档分配到同一节点,查询/修改这些文档的时候也带有路由参数去查,这样只查部分节点数据就能获取想要的数据。
具体用法,有时间再亲测写,先感谢粘一篇帖子
https://blog.csdn.net/u010454030/article/details/73554652
今天我就是在这遇到坑了,索引模板里面有路由必填的设置,索引mapping中有路由限制,搞得我无法写入文档到索引,报错
routing_missing_exception
将模板中这个去掉,重新生成索引解决















 3058
3058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









