







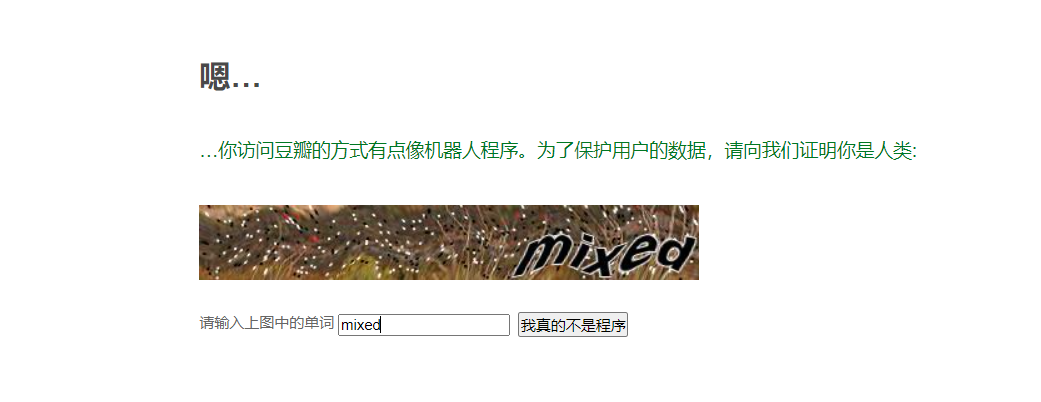
我采用的是爬完数据再一次性保存,列举了三种保存方式(excel、csv、MySQL)。豆瓣不会封IP,不用搞代理,异常就上豆瓣解一下即可。如下图
代码:
import time
import requests
import re
from lxml.etree import HTML
import threading
import csv
import pymysql
from openpyxl import Workbook
base_url = 'https://movie.douban.com/top250?start={}&filter='
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.'
'159 Safari/537.36',
'Cookie': '填自己的cookie',
}
content = [] # 用来存电影数据
def parse_page(url, i):
resp = requests.get(url, headers=headers)
html_re = resp.text
html_xpath = HTML(html_re)
detail_url_list = html_xpath.xpath("//div[@class='pic']/a/@href") # 获取详情页面url
for detail_url in detail_url_list:
# print(detail_url)
parse_detail(detail_url, int(i / 25))
def parse_detail(url, i):
resp = requests.get(url, headers=headers 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









