







由于打算用深度学习做一下电影评论等级分析预测,所以打算去豆瓣采集信息,但是每一个电影内部评论数量只能让你采集600条,为此采集250个电影,共计150000条评论,150000条标签。
第一步:分析页面并导包
1.1 分析主页
进入豆瓣电影TOP 250,发现页面很好解析;
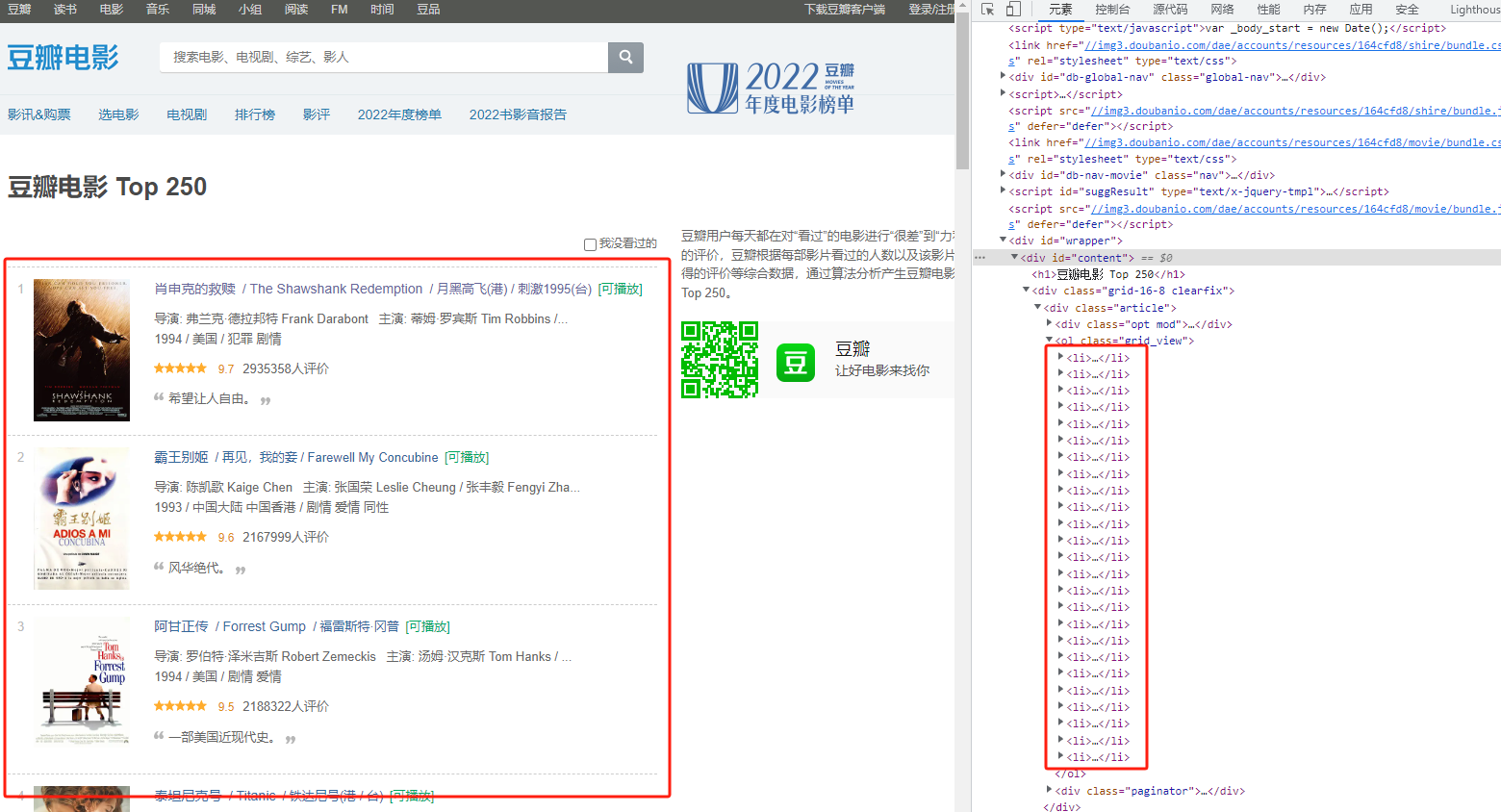
接着观察请求,是document请求,获取到页面直接解析页面就好;
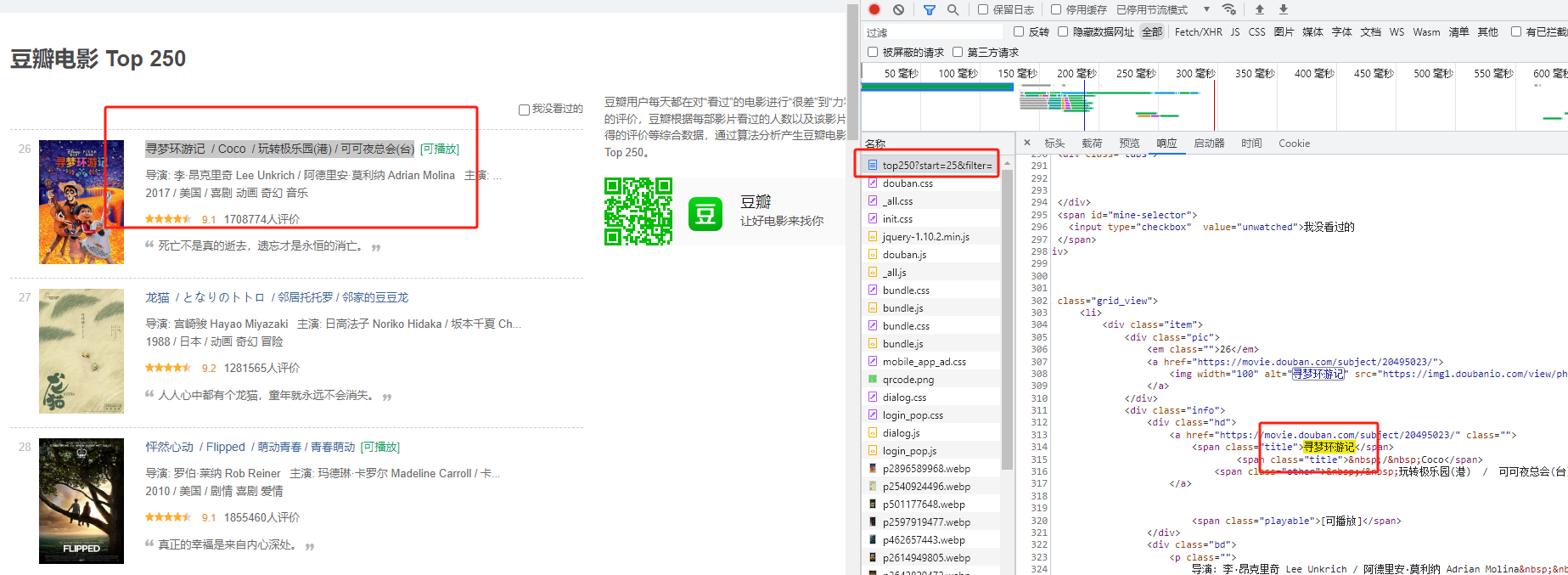
1.2 分析详细页
可以发现详细页得到的请求是json数据,其中也是以html形式返回的,其中request是get;
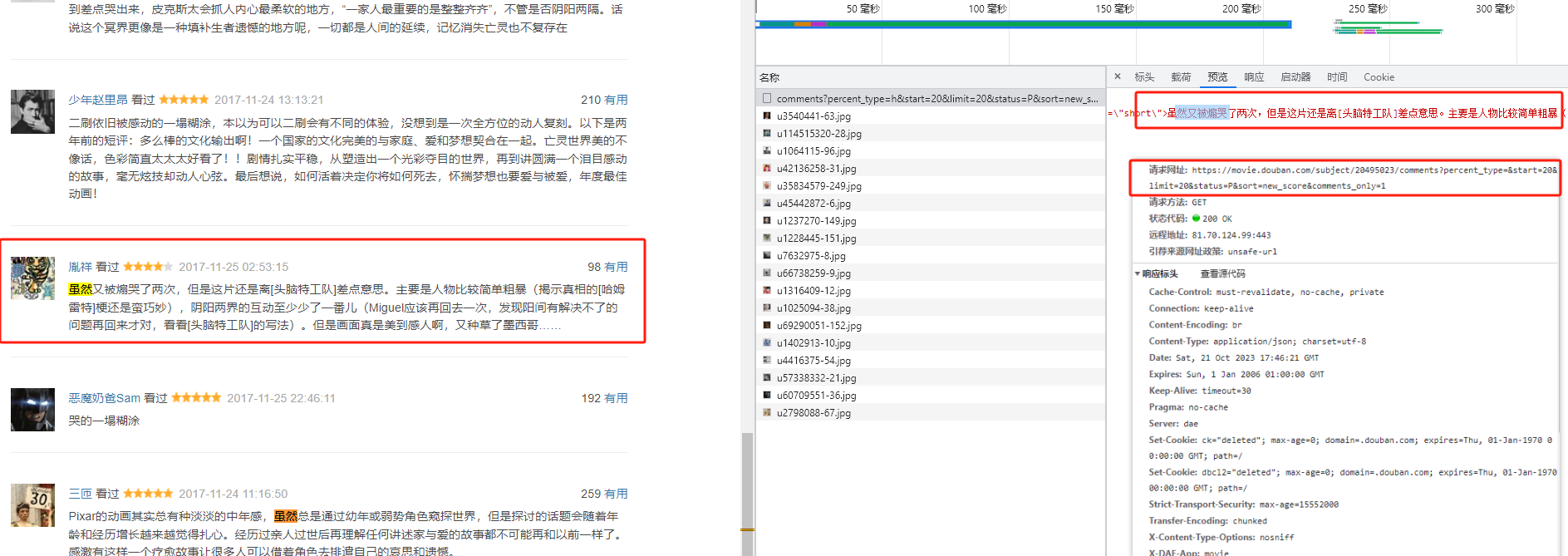
再仔细观察得我们需要的参数只是20495023这个url上的数字便可;
1.3 导包
过于简单,直接开干;
import requests
import pandas as pd
from lxml import etree
from tqdm import tqdm
第二步:获取主体页
注意一下params中start是起始位置就好;
def get_one_page_main(i):
cookies = {
'bid': 'asdasdHCbhjQP-hEA',
'douban-fav-remind': '1',
'll': '"108288"',
'__utma': '30149280.1821312323600836.1695311253.1695311253.1697908544.2',
'__utmz': '30149280.1123123697908544.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic',
'__utmc': '30149280',
'_pk_ref.100001.4cf6': '%5B%22%22%2C%2B%22%22%2C%22%22%2C1697909564%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D',
'_pk_id.100001.4cf6': '5297d41fasdasde661c808.1697909564.',
'_pk_ses.100001.4cf6': '1',
'__utma': '223692131235111.913176241.1697909564.1697909564.1697909564.1',
'__utmb': '2234612395111.0.10.1697909564',
'__utmc': '22312213695111',
'__utmz': '22344121695111.1697909564.1.1.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/',
'ap_v': '0,6.0',
'__yadk_uid': '7PaqoT912312t04umospiOnlEejjbFuTNekhD',
'_vwo_uuid_v2': 'D583asdas944E3411069A4B9BF52AD0B361FCE|b5c3386c83dfa1760f26f9801cf87ce0',
'Hm_lvt_16a14f3002af3zxc2bf3a75dfe352478639': '1697909616',
'Hm_lpvt_16a14f3002afzxc32bf3a75dfe352478639': '1697909620',
'ct': 'y',
'__utmb': '3014921a80.12.10.1697908544',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Referer': f'https://movie.douban.com/top250?start={25*i}&filter=',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="101"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
params = {
'start': f'{25*i}',
'filter': '',
}
response = requests.get('https://movie.douban.com/top250', params=params, cookies=cookies, headers=headers)
html = etree.HTML(response.text)
titles = html.xpath('//ol/li/div/div[2]/div[1]/a/span[1]/text()')
hrefs = html.xpath('//ol/li/div/div[2]/div[1]/a/@href')
ratings = html.xpath('//ol/li/div/div[2]/div[2]/div/span[2]/text()')
df = pd.DataFrame([titles, hrefs, ratings], index=['title', 'href', 'rating']).T
return df
if __name__ == '__main__':
df_list = []
for i in range(11):
df = get_one_page_main(i)
df_list.append(df)
df = pd.concat(df_list)
df['id'] = df['href'].map(lambda x: x.split('/')[-2])
df.to_excel('主体数据.xlsx', index=False)
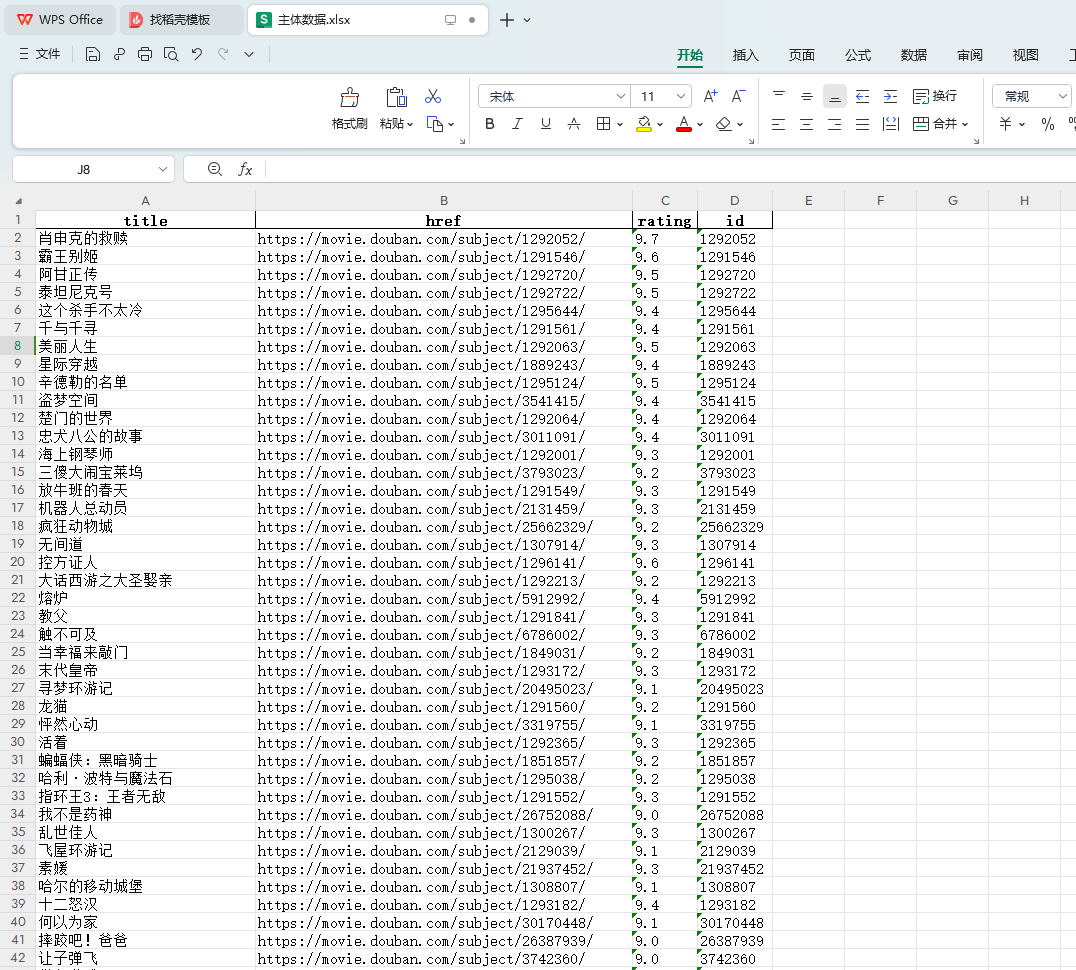
得到结果如下:
第三步:获取详细页
3.1 requests 构造
def get_one_page_detail(id, i, percent_type):
cookies = {
'bid': 'asdasdHCbhjQP-hEA',
'douban-fav-remind': '1',
'll': '"108288"',
'__utma': '30149280.1821312323600836.1695311253.1695311253.1697908544.2',
'__utmz': '30149280.1123123697908544.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic',
'__utmc': '30149280',
'_pk_ref.100001.4cf6': '%5B%22%22%2C%2B%22%22%2C%22%22%2C1697909564%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D',
'_pk_id.100001.4cf6': '5297d41fasdasde661c808.1697909564.',
'_pk_ses.100001.4cf6': '1',
'__utma': '223692131235111.913176241.1697909564.1697909564.1697909564.1',
'__utmb': '2234612395111.0.10.1697909564',
'__utmc': '22312213695111',
'__utmz': '22344121695111.1697909564.1.1.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/',
'ap_v': '0,6.0',
'__yadk_uid': '7PaqoT912312t04umospiOnlEejjbFuTNekhD',
'_vwo_uuid_v2': 'D583asdas944E3411069A4B9BF52AD0B361FCE|b5c3386c83dfa1760f26f9801cf87ce0',
'Hm_lvt_16a14f3002af3zxc2bf3a75dfe352478639': '1697909616',
'Hm_lpvt_16a14f3002afzxc32bf3a75dfe352478639': '1697909620',
'ct': 'y',
'__utmb': '3014921a80.12.10.1697908544',
}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="101"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
params = {
'percent_type': f'{percent_type}',
'start': f'{25*i}',
'limit': '20',
'status': 'P',
'sort': 'new_score',
'comments_only': '1',
}
response = requests.get(f'https://movie.douban.com/subject/{id}/comments', params=params, cookies=cookies, headers=headers)
html = etree.HTML(response.json()['html'])
contents = html.xpath('//p/span/text()')
return contents
if __name__ == '__main__':
df = pd.read_excel('主体数据.xlsx')
data_list = []
for i in tqdm(range(df.shape[0])):
items = df.iloc[i]
id = items['id']
data = pd.DataFrame()
contents = []
labels = []
for j in range(8+1):
for percent_type in ['h', 'm', 'l']:
lst = get_one_page_detail(id, j, percent_type)
contents.extend(lst)
labels.extend([percent_type] * len(lst))
data['content'] = contents
data['label'] = labels
data_list.append(data)
得到结果如下:

太慢了,大概17s一个电影
3.2 异步
哪天无聊再写!
结束! 花费半小时

















 1529
1529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









