






数据初始化
#引用库import torchfrom matplotlib import pyplot as pltdef linear_data_gen(w=3.0, b=2.0, num=1000):"""随机⽣成线性回归数据集 y = w * x + b"""x = torch.randn(size=[num])#随机生成原始数据noise = torch.randn(size=[num])#人为增加噪音y = x * w + b + noisereturn x, y
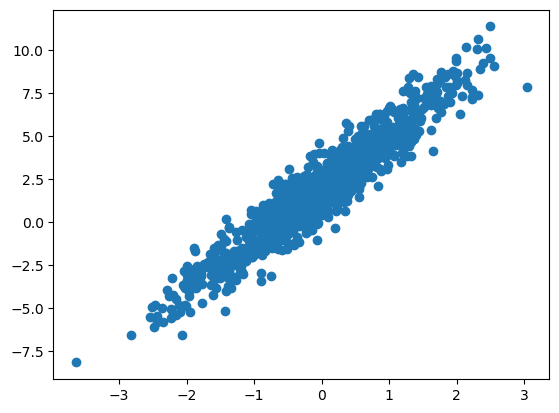
绘制原始数据集
x, y = linear_data_gen(3.0, 2.0)plt.scatter(x, y)#散点图绘制原始数据集
梯度下降
#拟合曲线初始化class Model:def __init__(self):self.w = torch.tensor(5.0, requires_grad=True) # 初始化拟合线,实际使⽤随机初始化self.b = torch.tensor(0.0, requires_grad=True)def __call__(self, x):return self.w * x + self.b
#损失函数def loss(y_pred, y_true):return torch.mean(torch.pow(y_pred - y_true, 2))
梯度计算
def train_step(model, x, y, learning_rate):# 前向计算current_loss = loss(model(x), y)# 反向计算current_loss.backward()with torch.no_grad():# 梯度下降model.w.data -= learning_rate * model.w.gradmodel.b.data -= learning_rate * model.b.grad# 梯度置0#对于进行梯度下降之后还需要对梯度进行清零,因为pytorch会保存本次的梯度值,将会导致下一次求梯度的时候求出来的是高阶梯度,但是实际山我们所需要的是当前的一阶梯度model.w.grad.zero_()model.b.grad.zero_()return current_loss
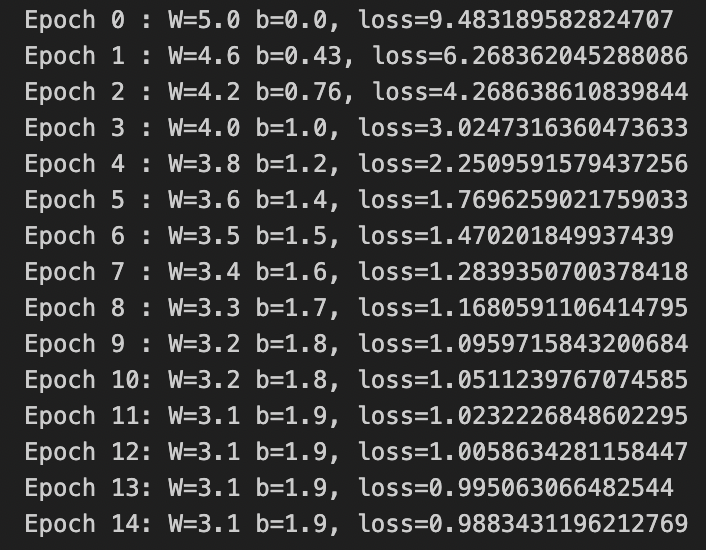
# 数据target_w = 3.0target_b = 2.0x, y = linear_data_gen(target_w, target_b)# 创建模型model = Model()y_old = model(x) # 原始模型的预测# 训练ws, bs = [], [] # 用于存储训练过程中所有 w 和 sepochs = range(15)for epoch in epochs:ws.append(model.w.item())bs.append(model.b.item())l = train_step(model, x, y, 0.1)print(f'Epoch {epoch:<2}: W={ws[-1]:<3.2} b={bs[-1]:<3.2}, loss={l}')
Tips:
-
Epoch标志着梯度下降计算的次数。
-
关于target_w和target_b,由于是根据y=3*x+2生成原始数据集的,所以我们预先知道了最优的拟合曲线应该是y=3*x+2,此处用于最后验证拟合效果
画图
plt.figure(figsize=(12, 4))font = {'family': 'simsun'} # 中⽂字体# 左图,训练前图,含原始数据和初始拟合线fig1 = plt.subplot(131)fig1.scatter(x, y, c='b', marker='o', s=4)fig1.scatter(x, y_old.data, c='r', marker='o', s=4)fig1.set_title("训练前", fontdict=font)# 中图,训练中的图,显示了w和b的变化fig2 = plt.subplot(132)fig2.plot(epochs, ws, 'y')fig2.plot(epochs, bs, 'm')fig2.plot([target_w] * len(epochs), 'y--', [target_b] * len(epochs), 'm--')fig2.legend(['w', 'b', 'target w', 'target b'])fig2.set_title("训练中", fontdict=font)# 右图,训练后的图,含拟合线和原始数据fig3 = plt.subplot(133)fig3.scatter(x, y, c='b', marker='o', s=4)fig3.scatter(x, model(x).data, c='g', marker='o', s=4)fig3.set_title("训练后", fontdict=font)plt.show()

Tips:
-
左图:原始数据及初始的拟合线:y=5*x
-
中图:拟合线的两个参数w,b随着学习次数的增加,变化的数值。同时,由于原始数据集是根据y=3*x+2生成的,所以我们预先知道了最优的拟合曲线应该是y=3*x+2,此处虚线为w=3,b=2。可以看到学习次数增加后,w和b向着目标逼近。
-
右图:原始数据及学习完毕后的拟合线
有建议欢迎指出,也欢迎友好交流!另也欢迎关注其他平台上本人的账号 如下:
知乎:youzuos
小红书:知识薪火站
微信公众号:知识薪火站
感谢支持!














 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









