







Python实战案例:flask结合elasticsearch实现全文搜索
ElasticSearch简称ES,其中Elastic一词通过词典查询获得。
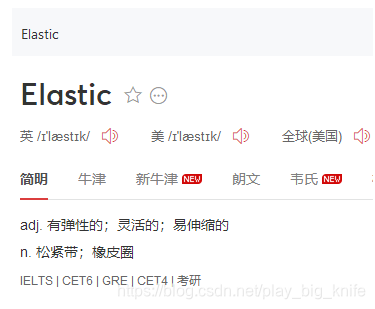
从名字里我们可以知道,ES的特点就在于灵活的搜索,其实ES本身就是一个全文搜索引擎。
一、全文搜索原理
如何实现全文搜索?最简单的方法就是用正则去匹配文档中的字符串。这种方式看似粗暴,但却不乏使用场景,比如Linux中的grep命令,Windows中用Ctrl+F在文件中进行查找等。
这种方式的缺点就是效率低,需要扫描全部文件,有时候搜索一个磁盘可能检索大半个小时。
在数据库中直接全表查询的时间复杂度是o(n),如果对索引列进行查询,其时间复杂度为o(logn),如果数据以key-value形式存储,查询时间复杂度将降为o(1)。那么在全文搜索中我们直接建立从查询词到文档的映射是不是也就获得了o(1)的查询性能?这种词汇到文档的映射被称之为倒排索引。那么倒排索引是如何构建的呢?一般流程如下:
加入3篇文章题目:
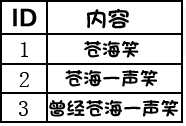
经过切词后得到每篇文档的词袋表示,即每篇文档所包含的词:

然后再构建从词汇到文档ID的映射:
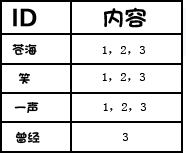
当然实际在切词后还会做一些去停用词、词目还原等操作,以提升索引质量。
全文检索就是利用Elasticsearch完成上面倒排索引的构建过程,然后在倒排索引上进行各种查询。
二、全文检索中的概念
假设现在有大量的数据,有网页,有图片,有视频,有学术论文等,现在你打算基于这些数据用ES打造一个搜索引擎。由于这些数据高度异构,你可能对网页、图片、视频、论文等分别构建不同的”索引“。以Bing搜索为例,其上方的不同选项卡,对应着不同的索引。
在学术论文索引中,为了支持作者查询,机构查询,发表时间查询等多种查询模式,你需要定义多种”类型“,在定义”类型“时,你需要通过mapping文件定义各个字段的类型,处理方式(如切词、过滤等),然后所有文档将基于这个mapping文件来构建倒排索引。可以说一个”类型”对应一个倒排索引表。
这里提到的一些概念:
〖索引〗:含相同属性的文档集合。相当于关系型数据库中的一个database。
〖类型〗:索引可以定义一个或者多个类型,文档必须属于一个类型,其相当于关系型数据库中的表,是通过mapping定义的。mapping中主要包括字段名、字段数据类型和字段索引类型这3个方面的定义,相当于关系型数据库中的schema。
〖文档〗:可以被索引的基本数据单位,也是全文搜索中被搜索的对象,可以对应一个网页,一篇txt文档或者一个商品。 相当于关系型数据库中的表中的一行记录。
具体的一篇论文即为一篇“文档”,在进行索引的过程中,如果索引量巨大,或者节点故障造索引片的丢失情况,针对性地使用分片和备份。
〖分片〗:有时候一个索引的数据量非常大,甚至超出了单机的存储能力,这个时候需要对索引分片存储,分别存到不同机器上。
〖备份〗:为了防止节点故障到时索引分片丢失,一般会对分片进行备份。备份除了可以保障数据安全性,还可以分担搜索的压力。
Elasticsearch创建索引默认5个分片,1个备份,分片只能在创建索引的时候指定而备份可以后期动态修改。
二、Elasticsearch全文检索系统架构设计原理
关于Elasticsearch全文检索系统架构设计原理图如下图所示。
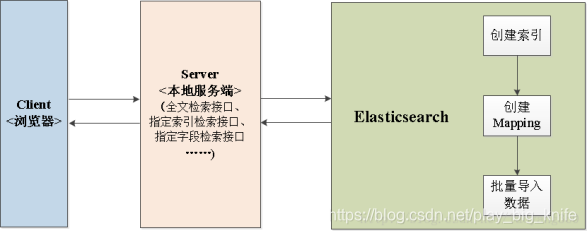
作为检索引擎,数据是第一位的。
只有将基础数据存入到ES中,才能提供检索服务。而类似Mysql关系型数据库,初期需要我们:
1)设计库表、库表关联等;
2)基础数据入库(程序入库、手动入库等)。
同样的,ES的创建索引 == Mysql的库表创建 。(ES6.X最新版本中将去掉type类型)。
ES的Mapping&创建==Mysql的字段设计&创建。
根据不同基础数据类型,
1)如果数据存储在关系型数据mysql或oracle中,可以通过logstash插入数据。
2)如果本地存储,或数据没有格式化。
需要先将数据格式化,格式化为Json文件,继而通过后端语言实现批量插入数据。
服务端的主要作用:
1)监听某设定端口;
2)接收客户端的请求(全文检索、指定字段检索等);
3)将请求解析后传递给Elasticsearch服务端。
4)接受到服务端的反馈后,将返回的大Json解析成前后端对接设定好的Json格式。
5)将转换后的Json返给客户端。
客户端的主要功能点:
1)界面呈现;
2)数据渲染。
3)检索请求;
4)检索结果呈现。
三、将mysql的数据写入到elasticsearch中
为了更好地实现在elasticsearch中全文检索数据,需要将mysql中的全部数据选择出来写入到elasticsearch中。
第一步需要将mysql中的数据全部取出来,这里以商品表为例,数据库中的表结构如下图所示。
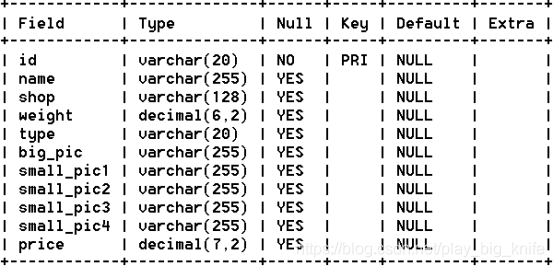
这里的字段意义如下:
id就是商品的id;
name是商品的名称
shop是商品店铺的名称
weight是商品的重量
type是商品所属的频道类别
big_pic是商品的大图路径名
small_pic1是商品详情页中小图的轮播图1
small_pic2是商品详情页中小图的轮播图2
small_pic3是商品详情页中小图的轮播图3
small_pic4是商品详情页中小图的轮播图4
price是商品的售卖价格
从数据库中取出所有记录可以使用sql语句来实现,python实现该功能可以使用pymysql模块,通过模块的connect方法连接mysql服务器,初始化host(主机地址)、port(端口)、user(用户名)、password(密码)、database(数据库)。接下来获取连接服务器后的游标cursor,通过cursor的execute方法去执行sql语句“selet * from shop”,将商品表中的所有数据选择出来后,用cursor的fetchall方法获取结果中的所有记录。
将上述的方法封装在一个方法中,最终将fetchall获取的结果返回,代码如下。
import pymysql
def get_data():
conn=pymysql.connect(host="localhost",port=3306,user="root",password="admin",database="freshshop")
cursor=conn.cursor()
sql="select * from shop"
cursor.execute(sql)
results=cursor.fetchall()
conn.close()
return results
if __name__=="__main__":
for row in get_data():
print(row)
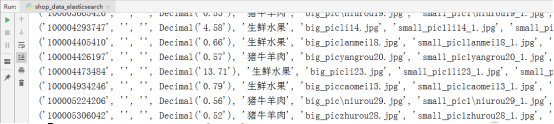
运行该代码结果后,就将数据库中所有的商品记录选取出来了。结果图如下。
接下来,把从数据库中获取的数据存储到elasticsearch中,需要在elasticsearch中实现数据的存储,需要python安装elasticsearch框架,安装方法如下:
pip3 install elasticsearch
框架模块成功安装后,实例化elasticsearch模块中的Elasticsearch类,实例化之后调用index方法添加elasticsearch数据,调用index方法时需要传入参数index表示elasticsearch的索引名字,doc_type是elasticsearch的文档类型,body是具体的elasticsearch索引文档中的具体内容。代码如下。
import pymysql
from elasticsearch import Elasticsearch
def get_data():
conn=pymysql.connect(host="localhost",port=3306,user="root",password="admin",database="freshshop")
cursor=conn.cursor()
sql="select * from shop"
cursor.execute(sql)
results=cursor.fetchall()
conn.close()
return results
def create_es_data():
es=Elasticsearch()
try:
results=get_data()
for row in results:
print(row)
message={
"id":row[0],
"name":row[1],
"shop":row[2],
"category":row[4],
"price":row[-1]
}
es.index(index="freshshop",doc_type="test-type",body=message)
except Exception as e:
print("Error:"+str(e))
if __name__=="__main__":
create_es_data()
运行代码之前需要保证elasticsearch服务器保持启动状态。
可以从elasticsearch的官方网站(https://www.elastic.co/cn/downloads/####elasticsearch)中下载elasticsearch的程序。如下图所示。
在任意目录下新建一个目录例如elasticsearch将下载的elasticsearch解压复制到该目录下。如下图所示。
在dos命令窗口里进入刚刚新建的elasticsearch下的bin运行elasticsearch.bat命令。
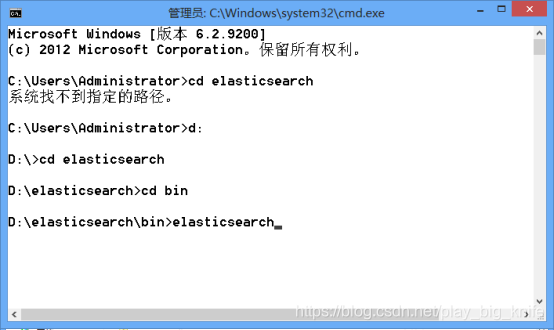
运行elasticsearch后,再运行pycharm中的将商城shop中的数据取出来写入elasticsearch中的代码,运行后在chrome浏览器中调用扩展程序的elasticsearch-head插件。

点击elasticsearch-header后,找到elasticsearch对应的freshshop索引后,点击左边的freshshop索引,右边显示数据写入全文索引后的具体内容,如下图所示。
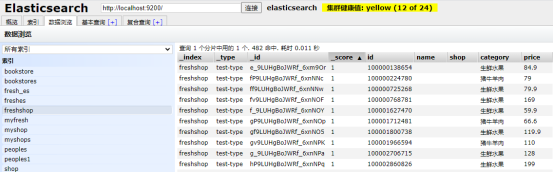
四、elasticsearch查找类的封装
数据存储到了elasticsearch中之后,Python需要实现对elasticsearch中的数据进行操作,需要首先去安装elasticsearch模块。安装方法如下:
pip3 install elasticsearch
现在需要对elasticsearch中的数据进行全文检索,这里封装一个新的elasticsearch类。封装init方法时把elasticsearch查询时需要提供的索引名称index和文档类型doc_type。继续在封装的类中实现方法query,query方法接收需要查询的文档信息,程序首先定义字典类型的查询配置ds1,其中的键名固定为“query”以实现elasticsearch的查询,键名对应的仍然是一个字典的类型,这个字典的键名为“multimatch”表示elasticsearch全文检索的优势,进行多个字段数据的匹配。键名对应的值仍然是一个字典的类型,其中包括表示查询的键名“query”和表示被查询字段的“fields”,“query”键名对应的键值就是需要查询的内容,“fields”键名对应的键值为需要查询的字段的列表。设置好elasticsearch查询的相关参数后,就可以调用elasticsearch中的search方法,传入初始化时的index索引名字和doctype文档类型及其值为设置参数ds1的body参数。具体代码如下。
from elasticsearch import Elasticsearch
class elasticsearch():
def __init__(self,index_name,index_type):
self.es=Elasticsearch();
self.index_name=index_name
self.index_type=index_type
def search(self,query,count:int=30):
ds1={
"query":{
"multi_match":{
"query":query,
"fields":["name","shop"]
}
}
}
match_data=self.es.search(index=self.index_name,doc_type=self.index_type,body=ds1,size=count)
return match_data
五、flask实现elasticseach的全文检索模糊查询
封装好elasticsearch类后,可以通过flask框架实现请求,再获取查询后的结果。
可以事先实现flask的Hello World程序,用装饰器去访问一个hello的地址,实例化Flask程序,把系统变量name传入参数中,在主程序中调用run方法启动flask程序。代码如下。
from flask import Flask,request
from elasticsearch_query_class import elasticsearch
import json
app=Flask(__name__)
@app.route("/")
def index():
return "Hello World"
if __name__=="__main__":
app.run(threaded=True)
接下来需要再设置调用elasticsearch中全文检索query方法的路由地址,在装饰器中传入需要进行模糊查询的文本接收参数,这个参数也是这个装饰器作用的方法参数。程序逻辑就是在程序开始实例化自己封装的elasticsearch类,并传入需要进行全文检索的索引名称index和文档类型。接下来调用search方法,最终查询出来的结果数据集在结果变量的“hits”键名对应值中的“hits”键名对应的值中,初始化定义一个接收数据结果的集合addresslist,然后遍历“hits”键名对应值中的“hits”键名对应的值,取其中每一个值的键名“source”对应的值,最后将addresslist结果列表使用json数据模块的dumps方法转换成json数据后, 使用flask框架初始化的app变量中的responseclass方法返回前端json数据,并在responseclass方法中指contenttype文件的具体json格式。
最后在主程序调用,调用的时候如果使用threaded=True的参数,表示对flask程序的请求使用了多线程。
具体代码如下。
from flask import Flask,request
from elasticsearch_query_class import elasticsearch
import json
app=Flask(__name__)
@app.route("/")
def index():
return "Hello World"
@app.route("/get_es/<query>")
def get_es(query):
es=elasticsearch(index_name="freshshop",index_type="test-type")
data=es.search(query)
print(data)
address_data=data["hits"]["hits"]
address_list=[]
for item in address_data:
address_list.append(item["_source"])
new_json=json.dumps(address_list,ensure_ascii=False)
return app.response_class(new_json,content_type="application/json")
if __name__=="__main__":
app.run(threaded=True)
最终执行结果后,在浏览器地址栏输入最终查询访问的地址,比如需要模糊查询水果,在地址栏中输入:http://127.0.0.1:5000/get_es/水果。
在浏览器中最终显示的结果如下。
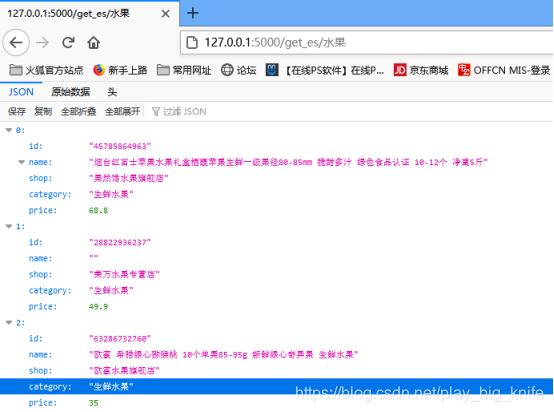
这样就实现了elasticsearch的最终全文检索的模糊查询。
代码的github地址:https://github.com/wawacode/flask_elasticsearch_query

















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









