









本周看了一篇图文结合的论文,由于论文的代码并没有开源,所以看的比较粗,但是在对多模态的处理方式上,还是有多借鉴的地方

论文地址:
https://arxiv.org/abs/2001.07966
本文的对象是预训练模型,所以其重点有:
- 预训练的任务
- 模型的输入方式
- 预训练的策略
- 微调
(1)预训练的任务
既然是预训练模型,那么开头肯定是确定预训练的任务。对于图文结合,什么样的预训练任务可以将两种模态的信息尽可能交互呢
按照我们常规的思路就是,先将文本与图像分开编码,饭后使用attention实现两者的交互,这就是双流模型的主要思想,模型的结构会在后文介绍
但本文的思想略有不同,按照作者的想法是希望可以在输入阶段就把图像-文本的输入合并,然后直接使用attention对合并后的输入进行编码交互,实现模态交互
本文设计的预训练任务为:
-
文本
-
masked language modeling:也就是mlm其loss计算公式如下:
KaTeX parse error: Undefined control sequence: \m at position 58: …ta}(w_{m_T}|w_{\̲m̲_T},v)
其中 w = w 0 , w 1 , . . . , w n − 1 w={w_0,w_1,...,w_{n-1}} w=w0,w1,...,wn−1表示输入的序列, v = v 0 , v 1 , v n − 1 v={v_0,v_1,v_{n-1}} v=v0,v1,vn−1表示经过
cross-attention后输出的序列, m T m_T mT表示被mask的token,KaTeX parse error: Undefined control sequence: \m at position 1: \̲m̲_T表示没有被mask,loss有每个 ( v , w ) (v,w) (v,w)对计算, D D D表示训练集
-
-
图像
-
masked object classification:MOC,具体来说就是一个分类任务,分类的对象是图片,并且和文本一样,对图片进行了15%的mask(90%使用mask token代替,10%保持不变)其标签使用的是faster-cnn提取的图片的roi特征,目标是预测被mask的图片的token,损失函数使用的是交叉熵
loss的计算公式如下:
L M O C ( θ ) = − E ( v , w ) ∈ D ∑ i = 0 M − 1 C E ( l θ ( v m I i ) , f θ ( v m I i ) ) L_{MOC}(\theta)=-E_{(v,w)\in{D}}\sum\limits_{i=0}^{M-1}CE(l_{\theta}(v_{m_I}^{i}),f_{\theta}(v_{m_I}^{i})) LMOC(θ)=−E(v,w)∈Di=0∑M−1CE(lθ(vmIi),fθ(vmIi))
-
Masked Region Feature Regression:MRFR,对图片mask区域的embedding进行回归,使用L2做为损失函数,相比于MOC可以做的更加精确,其计算公式为:L M R F R ( θ ) = − E ( v , w ) ∈ D ∑ i = 0 M − 1 ∣ ∣ h θ ( v m I ( i ) ) − r θ ( v m I ( i ) ) ∣ ∣ 2 2 L_{MRFR}(\theta)=-E_{(v,w)\in{D}}\sum\limits_{i=0}^{M-1}||h_{\theta}(v_{mI}^{(i)})-r_{\theta}(v_{mI}^{(i)})||_2^2 LMRFR(θ)=−E(v,w)∈Di=0∑M−1∣∣hθ(vmI(i))−rθ(vmI(i))∣∣22
其中, h θ ( v m I ( i ) ) h_{\theta}(v_{mI}^{(i)}) hθ(vmI(i))表示需要回归的目标, r θ ( v m I ( i ) ) r_{\theta}(v_{mI}^{(i)}) rθ(vmI(i))表示用fc层将ROI特征转化为向量表示
-
-
文本-图像
-
Image-Text Matching:ITM,学习文本-图片的对齐性。对每个训练样本,随机采样图片的文本负例和文本的图片负例,生成负的训练数据。用[CLS]做为模型输入序列的第一个token,同时使用fc层去获得文本-图片的相似度得分。该任务使用的是二分类的loss,计算公式如下:L I M T ( θ ) = − E ( v , w ) ∈ D [ y l o g s θ ( v , w ) + ( 1 − y ) l o g ( 1 − s θ ( v , w ) ) ] L_{IMT}(\theta)=-E_{(v,w)\in{D}}[ylogs_{\theta}(v,w)+(1-y)log(1-s_{\theta}(v,w))] LIMT(θ)=−E(v,w)∈D[ylogsθ(v,w)+(1−y)log(1−sθ(v,w))]
其中 s θ ( v , w ) s_{\theta}(v,w) sθ(v,w)表示经过fc层后的文本-图片相似度得分
-
以上就是预训练的全部任务,一个文本,两个图片,一个多模态,其中图片分别使用分类和回归做为任务,其中分类任务是token级别的,回归任务是embedding级别的,作者为了证明这样做的合理性,也给MRFR做了消融实验,结果如下:
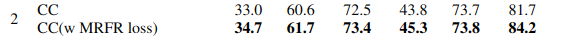
下面的实验是使用了MRFR的,这个实验是一个zero-shot,可以看到加入MRFR后,提升还是比较大的,作者由此得出的结论是:对图片任务,添加harder任务,有利于文本-图片多模态的最后结果
(2)模型的输入方式
上面我们知道了整个预训练有哪些任务,现在我们回头看看,需要怎么对输入进行处理
对于多模态模型,输入是一个非常重要的特点。单以图文结合来说,根据输入方式的不同,模型可以分为两类,单流模型和双流模型。
其中单流模型表示输入方只有一条线,也就是图像和文本合并在一起输入;双流模型则表示图像和文本分开输入。如下图所示:

本片论文使用的就是单流的方式,先对文本特征与图片特征拼接,然后输入一个encoder,后面就使用bert对编码进行一系列得变换,最后根据预训练任务对参数进行更新
其中,对于文本正常处理;对于图片则需要进行一些变换,具体步骤如下:
- 使用faster-rcnn提取图片的roi特征
- 将ROI特征编码为序列并与文本序列合并
如下图所示,为imagebert的结构图

可以看到,输入一共分成三个部分,Linguistic Embedding、Segment Embedding和mermaid sequenceDiagram Position Embedding。
sequenceDiagram Position Embedding:整个序列的位置编码,可以看到作者给了图片一个模糊的位置编码,全部用1表示,而文本则正常。作者解释为,图片的ROI特征之间是没有顺序的,并且图片的坐标信息在Linguistic Embedding就已经加入了,而且,Segment Embedding```已经起到了区分图片和文本的作用,所以这里只是起到一个同一向量维度的作用
-
Segment Embedding:用于区分图片和文本 -
Linguistic Embedding:这个输入就想对复杂点,不过也仅仅局限于图片的输入,文本的输入照常。其中需要先提取图片的ROI特征,然后加上位置信息,position Embedding的计算方式如下:c ( i ) = ( x t l W , y t l H , x b r W , y b r H , ( x b r − x t l ) ( y b r − y t l ) W H ) c^{(i)}=({{x_{tl}}\over{W}},{{y_{tl}}\over{H}},{{x_{br}}\over{W}},{{y_{br}}\over{H}},{{(x_{br}-x_{tl})(y_{br}-y_{tl})}\over{WH}}) c(i)=(Wxtl,Hytl,Wxbr,Hybr,WH(xbr−xtl)(ybr−ytl))
可以注意到,这个公式里 ( x b r − x t l ) ( y b r − y t l ) W H {{(x_{br}-x_{tl})(y_{br}-y_{tl})}\over{WH}} WH(xbr−xtl)(ybr−ytl),这部分表示该ROI区域在相对于整个图像的比例,我是觉得这里应该是作者笔误了, ( y b r − y t l ) (y_{br}-y_{tl}) (ybr−ytl)很明显就是一个负数,比例一般都是整数才对,所以我觉得应该是 ( y t l − y b r ) (y_{tl}-y_{br}) (ytl−ybr)
其中, ( x t l , y t l ) (x_{tl},y_{tl}) (xtl,ytl)和 ( x b r , y b r ) (x_{br},y_{br}) (xbr,ybr)ROI区域的左上和右下两个顶点的坐标
同时,可以看到图片中还有一个
Image Embedding,应该是faster-rcnn提取得到的
(3)预训练策略
本文使用了与以往不同的预训练策略,作者称其为两阶段预训练。作者说这样做的原因是他们收集了很多的数据集,而不同的数据集有着不同的来源、不同的质量以及不同的噪声。为了更好的利用这些数据集,所以提出了多阶段的预训练策略
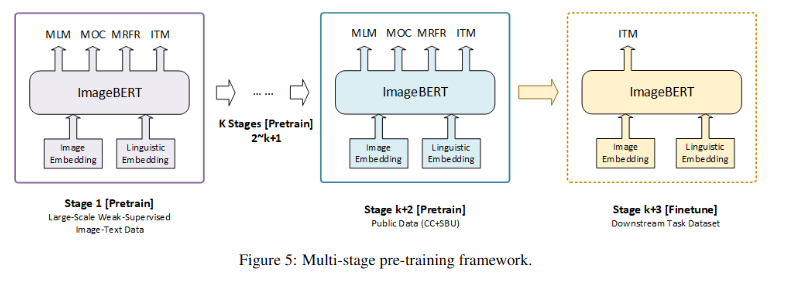
作者说明,为了使得预训练模型更加适合下游任务,应该先使用一个大范围的、out-of-domain数据来训练,然后使用小范围的、domain的数据来训练。有没有发现和我们平时的做法很像,就是用领域内的数据对bert进行一波预训练
更具体的,作者在预训练的第一阶段使用的数据集是LAIT(它们自己做的数据集,据说数据集的名声比模型本身还大),然后第二阶段使用的是其他公共数据集(CC+SBU,这两个数据集应该是领域内的公共数据集)。
作者对此也做了实验验证

可以看到,使用两阶段的效果好很多
(4)微调
作者的下游任务选择的是图文检索,在数据集MSCOCO和Flickr 30k上进行。微调任务在输入上是没有mask的,模型的训练目标是图片-文本匹配和文本-图像匹配
作者实验了三个不同的loss函数,分别是Binary classification Loss、Multi-class Classification Loss和Triplet Loss
-
Binary classification Loss:这里比较简单,每个样本对 ( v , w ) (v,w) (v,w)对应的标签就是01 -
Multi-class Classification Loss:这是扩大正负样本之间的边距的最广泛使用的损失。对每个正样本对,采样 P − 1 P-1 P−1个负样本对,然后以 P P P对样本对的第一个token的正确性,使用CE来计算损失函数 -
Triplet Loss:之前看到这个loss还是在sbert,最大化正样本和最难负样本之前的区别。最难负样本的下式给出n h − = a r g m a x ( v , w ) j ≠ ( v , w ) + s ( t ( v , w ) j ) n_h^-=argmax_{(v,w)^j\neq{(v,w)}}+s(t_{(v,w)^j}) nh−=argmax(v,w)j=(v,w)+s(t(v,w)j)
其中 s ( t ( v , w ) j ) s(t_{(v,w)^j}) s(t(v,w)j)表示
Multi-class Classification Loss中计算的样本对的相似度得分loss的计算公式为:
L T r i p l e t ( θ ) = − E ( v , w ) ( j ) ∑ n − ∈ N m a x [ 0 , s ( t ( v , w ) + ) , s ( n h − ) ] L_{Triplet}(\theta)=-E_{(v,w)}^{(j)}\sum\limits_{n^-\in{N}}max[0,s(t_{(v,w)^+}),s(n_h^-)] LTriplet(θ)=−E(v,w)(j)n−∈N∑max[0,s(t(v,w)+),s(nh−)]
实验结果为:

可以看到二分类就是最好的了,可能是图片-文本检索任务想对简单,目标清晰,果于复杂的loss反而让分类的边界不够清晰
(5)其他实验
作者也做了很多其他的实验
零样本实验:

下游任务中的参数调节实验

测试集的大小不同造成的结果差很多,多半是以下原因:
- 测试集过大,训练集就小了,导致模型的训练越发不充分
- 采样的方式,可能使用了不同的采样方式,导致测试集的分布有所改变,同样的训练集的分布也有所改变
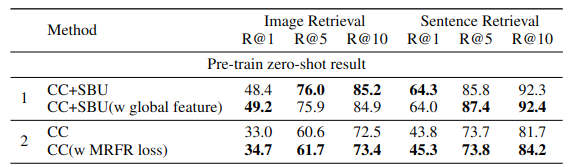
第一部分是一个是否使用图片的全局特征的实验,作者任务ROI的提取只使用了图片的局部特征,所以希望看看结合图片的全局特征后,对效果是否有提升。作者使用了三个不同的网络来提取全局信息,CNN、Res和GoolgeNet。但是,事实证明,加入全局信息后起负向作用。
总的来说,这篇文章对多模态还是很有想法的,之前很多模型处理多模态是分开编码、编码交互的方式,这篇文章则是分开预处理、合并输入、编码的方式。
在我看来,单流模式应该是比双流模式更加符合多模态的形式。双流模式仅仅是在编码层进行交互,给人的感觉就是:多模态就是把不同模态的数据编码,然后用一个cross-attention交互就可以了。这显然是一种没怎么经过思考的方法,各个模态之间的处理非常粗糙,给人一种多模态就是大杂烩的感觉
单流模式,则是在输入部分对每个模态的输入进行合并,构成一个多模态输入,然后经过一个编码器对该输入进行处理。单从直觉上感觉这种方式更加合理点
总结下这篇论文:
- 图片与文本输入的融合
- 两阶段预训练
- 多模态预训练任务的定义














 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









