







本文介绍一篇图文结合的经典论文,论文发布于2019年

论文题目:
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
论文地址:
https://arxiv.org/abs/1908.02265
代码地址:
https://github.com/facebookresearch/vilbert-multi-task
1、模型结构
ViLBERT作为一个经典的双流图文结合模型,其结构如下:
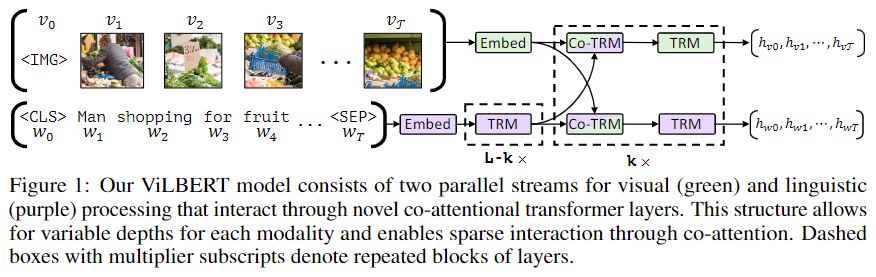
从上面的结构图可以看出,对于图像,作者提取了很多的region,并且在图片序列的最前面加入了特殊token <IMG>,其对应的文本则是正常的处理,并存在<CLS>、<SEP>两个特殊的token。接着,在双流结构中,文本侧比图片侧多一个transformer模块;然后,在交互层,先经过一个co-trm模块,才是标准的trm模块;最后,输出各自的文本和图片编码。
(1)co-attention trm layer
其中co-trm模块就是对两个trm模块进行了交互,如下图所示:
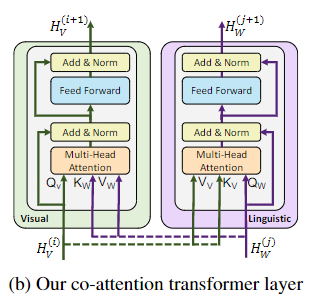
可以看到,其实现方式就是将文本和图片各自的transformer中的(k,v)进行交换,从而实现模态之间的交互。
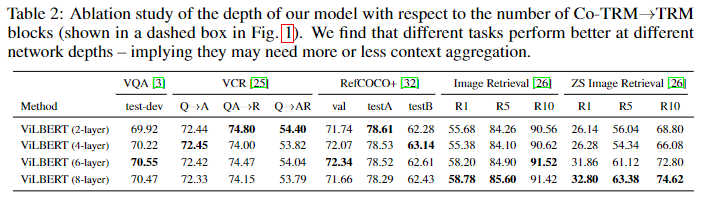
作者实验了不同的co-trm层对模型的影响,实验结果如下:
co-attn的代码实现片段为:
attention_scores1 = torch.matmul(query_layer2, key_layer1.transpose(-1, -2))
attention_scores1 = attention_scores1 / math.sqrt(self.attention_head_size)
attention_scores1 = attention_scores1 + attention_mask1
# if use_co_attention_mask:
# attention_scores1 = attention_scores1 + co_attention_mask.permute(0,1,3,2)
# Normalize the attention scores to probabilities.
attention_probs1 = nn.Softmax(dim=-1)(attention_scores1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs1 = self.dropout1(attention_probs1)
context_layer1 = torch.matmul(attention_probs1, value_layer1)
计算context_layer2同理。
(2)image representations
作者通过从预训练的目标检测网络中提取边界框及其视觉特征,来生成图像特征区域。与文本不同,region没有自然顺序,因此在对region进行位置编码时,作者构建了一个5维向量(左上角、右下角坐标,和region覆盖的区域比例),然后将其投影后,使其与特征有相同的尺寸,最后与特征相加。
图片embedding的代码实现如下:
class BertImageEmbeddings(nn.Module):
"""Construct the embeddings from image, spatial location (omit now) and token_type embeddings.
"""
def __init__(self, config):
super(BertImageEmbeddings, self).__init__()
self.image_embeddings = nn.Linear(2048, config.hidden_size)
# self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size, padding_idx=0)
self.token_type_embeddings = nn.Embedding(
config.type_vocab_size, config.hidden_size, padding_idx=0
)
self.image_location_embeddings = nn.Linear(5, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, input_loc, token_type_ids=None):
seq_length = input_ids.size(1)
# position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
# position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
image_embeddings = self.image_embeddings(input_ids)
# position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
loc_embeddings = self.image_location_embeddings(input_loc)
# embeddings = words_embeddings + position_embeddings + token_type_embeddings
embeddings = image_embeddings + token_type_embeddings + loc_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
可以看到,与文本的求解基本一致。
不过在求解图片的self-attn的时候,作者加入了下面这段代码:
if self.dynamic_attention:
self.dyLinear_q = nn.Linear(config.hidden_size, self.all_head_size)
self.dyLinear_k = nn.Linear(config.hidden_size, self.all_head_size)
if self.dynamic_attention:
pool_embedding = (txt_embedding * txt_attention_mask).sum(1)
pool_embedding = pool_embedding / txt_attention_mask.sum(1)
# given pool embedding, Linear and Sigmoid layer.
gate_q = 1 + torch.sigmoid(self.dyLinear_q(pool_embedding))
gate_k = 1 + torch.sigmoid(self.dyLinear_k(pool_embedding))
mixed_query_layer = mixed_query_layer * gate_q.unsqueeze(1)
mixed_key_layer = mixed_key_layer * gate_k.unsqueeze(1)
不是很理解为什么叫“动态注意力”,不过看其求解方法,应该是引入了文本的语义表征,然后用文本的语义表征对图片的qk进行了一个加权,或者说语义的筛选。这是图片self-attn与文本self-attn的唯一不同。
2、预训练
作者通过两个任务来训练模型,其一:通过未被mask的文本和图片来预测被mask的文本和图片;其二:预测文本与图片是否对应。
如下图所示:
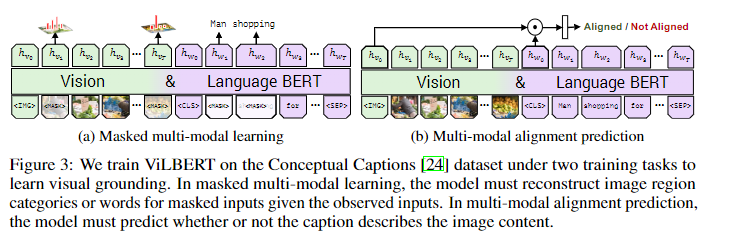
对于任务一,被masked图片的特征,90%的时间都被置零,10%的时间保持不变,被masked文本则与bert中的一致。该任务不是直接回归被masked的特征值,而是预测相应图像区域在语义上的分布。并使用相同的预训练检测模型对该region的输出分布作为标签,对任务进行监督,最小化两个分布之间的KL散度。这做法反应了,语言通常只能识别视觉内容的高级语义,而不太可能重建准确的图像特征。并且,作者认为,使用回归损失,可能难以平衡图像和文本被mask而产生的损失的权重。
对于任务二,其输入形式为:
{
I
M
G
,
v
1
,
.
.
.
,
v
T
,
C
L
S
,
w
1
,
.
.
.
,
w
T
,
S
E
P
}
\{IMG,v_1,...,v_T,CLS,w1,...,w_T,SEP\}
{IMG,v1,...,vT,CLS,w1,...,wT,SEP}
使用
h
I
M
G
h_{IMG}
hIMG和
h
C
L
S
h_{CLS}
hCLS来分别表示图片和文本,然后计算二者的乘积,并通过线性层,实现二分类,判断图像与文本是否对齐。
对于文本侧,作者使用bert对其进行初始化,为节省训练时间,使用的base版。使用Faster R-CNN提取图片的区域特征,作者选择10-36个高分框(检测概率超过置信度阈值的区域),对于每一个选择的i, v i v_i vi被定义为该区域的平均池化卷积特征。视觉侧的transformer和co-attn有1024的隐藏层大小和8个注意力头。
作者对模型的结构以及预训练任务的有效性进行了实验,并将模型的结果与历届sota模型进行了对比,实验结果如下:
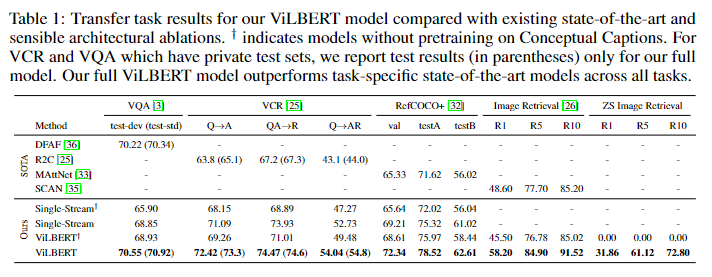
作者也对预训练时,数据集的大小进行了实验,结果如下:
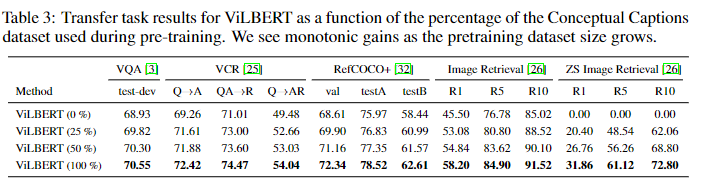
可以看到,训练集的大小基本只起正向作用。
下图是模型经过预训练,但没经过微调时,图像检索的效果:

3、下游
作者进行实验的下游任务有:
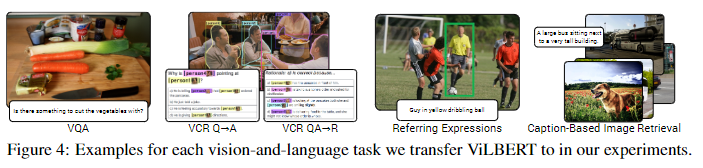
visual question answering(VQA)
将 h I M G h_{IMG} hIMG和 h C L S h_{CLS} hCLS进行逐元素乘积,并接上两层mlp,映射到可能的3129个答案上。作者将VQA作为一项多标签分类任务,根据每个答案与10个人类答案的相关性,为每个答案分配一个软目标分数,然后以软目标分数,通过二元交叉熵损失训练。
visual commonsense reasoning(VCR)
作者将问题和每个可能的响应concat,形成了四个不同的文本输入,并将每个文本与图像一起传入ViLBERT。然后,连接一个线性层来预测每队输入的分数
grounding referring expressions
通过计算与真实框的IOU并以0.5为阈值,来给每个区域进行标记。最后,预测每个区域的匹配得分。
caption-based image retrieval
基于标题的图像检索,在给定描述其内容的标题的情况下,识别图像的任务。负样本通过随机替换标题、随机替换图片或者从目标图片的100个最近邻样本中挑选难负样本。计算每个标题-图片对的对齐分数。作者为了提高该任务的效率,将进入交叉层之前的文本表征保存复用。
这篇文章发的比LXMERT
还要早,应该可以算双流模型的开篇之作。本文在文本侧与bert如出一辙,在图片侧大致结构基本一致,但是在trm层数上会有不同。看源码和论文可以了解到,作者在图片层数和交叉层层数的选取上做了很多实验。同时论文中提到的co-trm,说的很高大上,设计一个独立的模块,看到最后其实就是将代码中对应的kv位置互换就可以,也许所有的多模态交互层都是在trm结构上的小改吧。
看到这篇论文的代码时,感觉非常熟悉,之前的LXMERT提供的源码与其相似度很高,不过都是在共同模块上的相同,感觉做双流模型可以直接在这版代码上进行魔改就可以了。
【往期内容】


















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









