







之前我们使用的层都是在tf.keras.layers中封装好的,在我们实际应用上,封装好的层应用的也比较多,但有的时候我们需要让层实现在封装层中没有的功能,这个时候我们就要自定义层
所有的自定义层都要继承tf.keras.layers.Layer,才能被使用,我们在自定义类前先导入库
![]()
目录
1 自定义全连接层 dense
首先我们创建一个类,这个类需要继承tf.keras.layers.Layer
![]()
1.1 定义初始化方法
之后我们定义初始化函数,初始化函数有两个参数,一个是神经元个数(units)我们默认为32个,另一个是输入数据的深度,我们默认为32维度
![]()
之后我们继承父类的__init__()方法

之后我们定义随机初始化,我们使用的方法为tf.random_normal_initializer,这样会生成一个标准正态分布的随机初始化器
![]()
- 初始化器变量可以自定
之后我们创建一个变量作为类的属性,作为权重,使用到我们刚刚的随机初始化器,我们令w的形状为(input_dim,units),变量类型为float32,训练状态置为可训练
![]()
上面是我们普通的dense就是这样用的,shape是(输入维度,神经元个数)
- 属性变量可以自定,shape,dtype,trainable都可以自定
全连接层是运算是 y = wx + b ,除了w,还有b,现在我们定义b的初始化器,我们使用全0初始化
- 由于是自定义层,我们使用什么初始化都可以,这里只是做一个例子
![]()
然后我们生成属性b,shape是神经元个数
![]()
1.2 定义前向传播方法
![]()
我们将前向传播的方法命名为call,参数为输入的数据,这里制作一步操作,让输入与w矩阵相乘,之后加上b,再之后返回
- call这个名称是固定的,上面的__init__这个名称也是固定的
1.3 使用自定义层
我们现在就可以使用我们自定义的层了,首先我们创建一个输入
![]()

之后我们将自定义的层实例化,实例化第一个参数是神经元个数4,第二个是维度,由于我的输入现在是二维的,所以此处写2
![]()
首先我们先回顾一下矩阵乘法,A矩阵的shape为(m,n)(m行n列),B矩阵的shape为(n,p)(n行p列),此时这两个n一定要相等,那么C矩阵(A矩阵矩阵相乘B矩阵的结果)的shape应为(m,p)
之后我们举个例子,A与B进行矩阵相乘,得到了C矩阵

说简单一点就是行乘列
之后我们用代码验证一下,看是不是这个结果
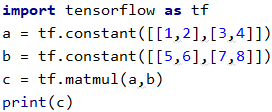

发现没有什么问题
再之后我们使用这个层
![]()

我们就单看shape,我们输入的矩阵shape是(2,2),权重的shape是(2,4),那么结果应该是(2,4),这个没有问题,其余就是矩阵相乘了,我们把x,w,b,y都显示出来
- x

- w

- b
![]()
这个是全0矩阵,跟他做加法不影响后面的结果
- y

一共有8个,我们就计算一个演示一下,计算左上角的 0.01169998 这个值
0.01169998 = 1 * 0.00412212 + 1 * 0.00757786
其余的值我们可以自己算一下,应该都没有问题
1.4 获取所有可训练参数 .weights
我们可以使用.weights获取所有可训练参数,.weights是继承父类的方法
![]()

1.5 使用 add_weight() 添加权重

这样写和我们之前那样写的效果是一样的
1.6 承接上层的输出作为输入
这两种写法都有一个问题,就是不能承接上一层的输出作为本层的输入,如果想要达到这个效果,我们应该这样写

- build的名称是固定的
我们实例化,然后看一下它的权重
![]()
![]()
发现是空的,这是因为我们没有调用my_linear这个对象,我们现在使用my_linear
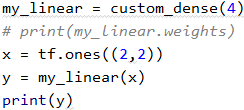

发现没有什么问题,这个时候我们再看一下我们的weights

发现它不再是空的了

2 层的组合
2.1 使用自定义层
我们可以将多个层的运算放在一个层中进行

我们第一个层32个神经元,第二个层64个,最后一层作为输出层,只有一个神经元,然后定义call方法,先使用layer_1对inputs求解,然后使用relu激活,然后使用layer_2对x求解,之后使用relu进行激活,之后使用layer_3对x进行求解,然后返回x
下面我们来使用它

发现可以使用

2.2 使用内置层
我们除了使用自定义层,也可以使用内置层

然后我们使用一下

发现可以使用

3 自定义模型
方法和组合层差不多,只是更换了父对象,更换了父对象后,我们就可以使用新父对象的方法,比如model.save

如果我们需要把使用fit()或save()这些方法,我们就定义成自定义模型,如果不需要就定义为自定义层
我们下面使用自定义层做一个线性回归的训练

代码中涉及到了编译,训练,预测,保存
编译后的训练过程

训练后的预测过程

保存


自定义模型保存的文件是不能保存为h5文件的,如果保存为h5文件会报错

















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











