







requests是请求用的,在发起请求中requests会默认帮我们解决一些问题,比如跨域
下面做几个例子,服务选用flask,服务的结构就是这样的,根据不同的请求会换不同的视图与路由

目录
1 发请求
1.1 GET请求
1.1.1 无参数
视图与路由

请求
import requests
url = 'http://127.0.0.1:5000/get_no_params'
response = requests.get(url)
print(response)
print(type(response))
print(response.text)
print(type(response.text))
直接打印response我们会看到状态码,response得到的是一个对象,调用response对象的text方法可以得到响应的内容
1.1.2 查询字符串
服务
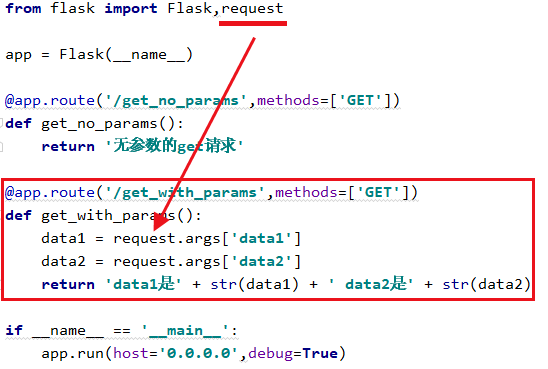
请求
import requests
url = 'http://127.0.0.1:5000/get_with_params?data1=20&data2=30'
response = requests.get(url)
print(response)
print(type(response))
print(response.text)
print(type(response.text))
1.1.3 parmas
除了查询字符串你也可以使用对象作为参数
import requests
url = 'http://127.0.0.1:5000/get_with_params'
response = requests.get(url,params={'data1':20,'data2':50})
print(response)
print(type(response))
print(response.text)
print(type(response.text))
1.2 POST
1.2.1 无参数
服务

请求
import requests
url = 'http://127.0.0.1:5000/post_no_params'
response = requests.post(url)
print(response)
print(type(response))
print(response.text)
print(type(response.text))
1.2.2 json数据
服务
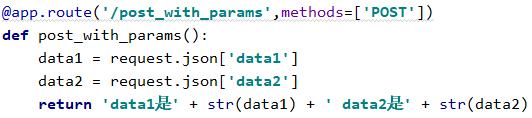
请求
import requests
url = 'http://127.0.0.1:5000/post_with_params'
json_data = {'data1': 'Suyu','data2':18}
response = requests.post(url,json=json_data)
print(response)
print(type(response))
print(response.text)
print(type(response.text))
1.2.2 json数据
服务

请求
import requests
url = 'http://127.0.0.1:5000/post_with_params'
json_data = {'data1': 'Suyu','data2':18}
response = requests.post(url,json=json_data)
print(response)
print(type(response))
print(response.text)
print(type(response.text))
1.2.3 文件
我现在像将python.png上传到file中

服务
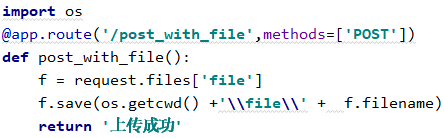
请求,files也是一个对象,里面有不同的键,在服务端去拿
import requests
url = 'http://127.0.0.1:5000/post_with_file'
files = {'file':open('./python.png','rb')}
response = requests.post(url,files=files)
print(response)
print(type(response))
print(response.text)
print(type(response.text))
请求之后就发现搞进来了

1.2.4 data数据
服务

请求
import requests
url = 'http://127.0.0.1:5000/post_with_data_params'
data = {'data1': 'Suyu','data2':18}
response = requests.post(url,data=json_data)
print(response)
print(response.text)![]()
1.3 加入请求头
服务

如果你不修改请求头的话,你的请求头是这些
import requests
url = 'http://127.0.0.1:5000/request_head'
response = requests.get(url)
print(response.text)
你可以新增一些
import requests
url = 'http://127.0.0.1:5000/request_head'
response = requests.get(url,headers={'123':'456','name':'789'})
print(response.text)
如果你用之前已经有的请求头就会覆盖掉之前的,比如我现在改user-agent
import requests
url = 'http://127.0.0.1:5000/request_head'
response = requests.get(url,headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'})
print(response.text)
2 处理响应
2.1 json数据
服务

我们请求后发现包含json数据的中文并不能直接显示出来,这让我们阅读起来很麻烦
import requests
url = 'http://127.0.0.1:5000/response_json'
response = requests.get(url)
print(response.text)![]()
这个时候我们可以对response使用json()

2.2 content数据
图片数据最好用content显示,比如我现在从网上随便找了一个图片的链接,如果用text会得到乱码的结果

如果用content就会得到二进制的结果

2.3 改变解码方式
默认的解码方式是utf-8,但是有的网站不是用utf-8编码的,比如 《三国演义》全集在线阅读_史书典籍_诗词名句网 我们尝试获取第一张的内容

发现会得到一堆乱码

一般来讲不是utf-8就是gbk,也许也有别的,判断起来很麻烦,我们可以这样写

3 例子
3.1 请求并保存一个图片
我在浏览器上随便找一张图片,然后点击复制图片地址

然后发起请求并保存
import requests
url = 'https://img0.baidu.com/it/u=2550192322,2924516969&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=500'
response = requests.get(url)
with open('./test.jpg','wb') as fp:
fp.write(response.content)运行后这个图片就被保存在代码的同级目录下

3.2 base64
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,可以用base64传输图像
服务
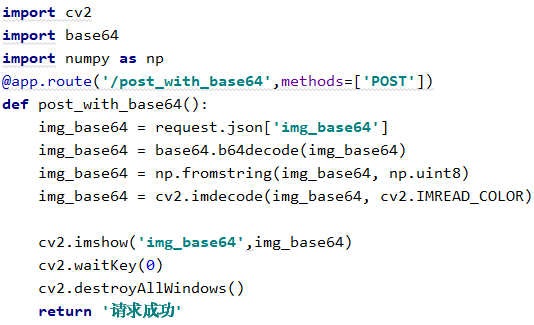
请求
import requests
import cv2
import base64
url = 'http://127.0.0.1:5000/post_with_base64'
frame = cv2.imread('python.png')
retval, buffer = cv2.imencode('.png', frame)
image = str(base64.b64encode(buffer), 'utf-8')
json_data = {'img_base64': image}
response = requests.post(url,json=json_data)
print(response)
print(type(response))
print(response.text)
print(type(response.text))
在请求结束(关闭显示图像的窗口)之前,服务端会显示出图像

3.3 请求并保存一个网页
我们以搜狗首页为例
import requests
url = 'https://www.sogou.com/'
response = requests.get(url=url)
with open('./test.html','w',encoding='utf-8') as f:
f.write(response.text)- 代码中的response是字符串形式的html
运行代码后会在代码的同级目录中得到test.html

双击之后会这样,这是因为我们的协议是file协议
- 作为爬虫来讲我们只需要数据就可以了,不需要样式

我们可以通过flask将其改为http协议,这样一些资源就可以加载出来了


3.4 请求并保存一个压缩包
import requests
url = 'https://downsc.chinaz.net/Files/DownLoad/jianli/202301/zjianli997.rar'
file_name = url.split('/')[-1]
response = requests.get(url)
with open('./{}'.format(file_name),'wb') as fp:
fp.write(response.content)运行后可以得到压缩包

压缩包中的内容正确

可以解压出来,也可以打开
















 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











