







Libra R-CNN: Towards Balanced Learning for Object Detection
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
这篇文章的点子很好,作者认为设计比较sota的目标检测模型的架构固然重要。
但是在目标检测的实践中,发现检测性能通常受到训练过程中的不平衡的限制,这通常包括三个级别——样本级别、特征级别和目标级别。
所以作者通过为了减轻这种不平衡所带来的负面影响,提出了Libra RCNN。
最后的实验结果就是将LIbra RCNN的思路用到Faster RCNN+FPN 和RetinaNet上,对COCO目标检测数据集进行实验,分别提高了2.0和2.5的mAP。

分成三类不平衡,如图所示:
(a) region中难易样本的不平衡
(b)FPN中特征融合的不平衡,低级特征缺乏语义信息,高级特征语义信息丰富
©多任务损失函数的不平衡,cls损失和loc损失之间存在着一个imbalance
Based on this paradigm, the success of the object detector training depends on three key aspects:
(1) whether theselected region samples are representative,
(2) whether theextracted visual features are fully utilized,
(3) whether the designed objective function is optimal.
However, our study reveals that the typical training process is significantly imbalanced in all these aspects. This imbalance issue prevents the power of well-designed model architectures from being fully exploited, thus limiting the overall performance.
作者认为,正是这三类不平衡,影响着目标检测模型的性能,无论是单阶段还是双阶段。
接下来就看作者是如何分别解决这三类不平衡的
- 对于(a),作者提出IoU-balanced sampling
- 对于(b),作者提出balanced feature pyramid
- 对于©, 作者提出balanced L1 loss

作者发现60%的硬负样本的IoU>0.05,而通过随机采样得到的样本超过 70% 都是在 IoU 在 0 到 0.05 之间的,这就是不科学的地方,统计得到的事实是 60% 的 hard negative 都落在 IoU 大于 0.05 的地方,但是随机采样只提供了 30%。所以作者提出了 IoU-balanced Sampling。
作者的想法就是希望采样得到的样本能够在IoU的各个区间中均匀分布


balanced FPN

balanced L1 loss


之所以会提出 Balanced L1 loss,是因为这个损失函数是两个 loss 的相加,如果分类做得很好地话一样会得到很高的分数,而导致忽略了回归的重要性,一个自然的想法就是调整 λ 的值。
根据梯度反求出函数的表达式:

成功使得loss降了下来

Dual Path Networks
Y. Chen, J. Li, H. Xiao, X. Jin, S. Yan, and J. Feng. “Dual path networks.” In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 4470–4478.

左边绿色是ResNeXt的通路,右边是DenseNet的通路,ResNeXt是DPN的主体,DenseNet是辅助体。作者认为,ResNet 系列的网络结构善于重用特征,但对于发现新的特征并不擅长,而 Densenet 善于发现新的特征但易冗余,而作者则让其强强联合,互为补充。
总结一下这篇论文,这篇论文提出了一种网络结构,这种网络结构由ResNeXt和DenseNet结合。使用了ResNeXt中的分组卷积和shortcut的思想,同时采用了DenseNet在channel上密集连接的思想。性能都超过了ResNeXt和DenseNet。
DPN的Pytorch代码实现
看了一下 Pytorch 的DPN实现,主要看点是 conv2~5 的4个DPN stage:ResNeXt 为主(bottleneck 形式),DenseNet为辅,DenseNet通路所占比例较低。每个stage的第一个DPN块会创造 2inc 的初始DenseNet feature maps,然后提取 inc 的新特征。inc 即DPN 的宏观设计表格中括号标注的(+k),含义与 DenseNet 的growth rate 相同。stage 1 即 conv2 的第一个 DPN 块不进行 stride=2 的下采样,其它 stage 的第一个 DPN 的stride 都为2,即使用 stride=2 的卷积层,而非使用maxpooling进行下采样。4个 stage 中,除了第一个 DPN 块会创造 2inc 层的初始 DenseNet 通路 feature maps 外,每个 DPN 都会探索得出 inc 的新 feature maps,包括第一个DPN,即各 stage 第一个DPN块输出会产生 (2+1)*inc 的DenseNet 通路 feature maps。
这个网络Pytorch官方实现了吗?
在这里插入代码片
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)

ECA的核心思想就是通过对SENet及其变体的分析,发现了全连接层降维带来的负面影响,并且捕获跨所有信道的依赖关系是低效和不必要的。
为了避免降维带来的负面影响,作者在SE模块的基础上开发了ECA模块,主要的思想就是捕获局部信道之间的依赖关系,引入一个超参数k认为输出的通道注意力值yi只与其输入空间相邻的对应k个元素有关系。这种思路很简单用1维卷积来实现。
如下图,将ECA模块的变换当成一种矩阵变换,就是只有k个参数
W1,1…W1,k 是对第一个元素进行操作的卷积核
W2,2…W2,k 是对第二个元素进行操作的卷积核,对应位置的卷积核的值与上面相同
一直到Wc 全部都相同

总结一句话,ECA模块就是一个GAP加上一个1D卷积,只有k个参数。
用矩阵表示就是::

import torch
from torch import nn
from torch.nn.parameter import Parameter
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size 超参数
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: input features with shape [b, c, h, w]
b, c, h, w = x.size()
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
为了避免通过交叉验证手动调优k,我们开发了一种自适应地确定k的方法,其中交互的覆盖范围(即内核大小k)与信道维数成正比

M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network

首先论文分析了以前的FPN存在的两个限制:
- 第一,特征金字塔对于目标检测任务并不完全适用,因为backbone的设计是为了图片分类;
- 第二,金字塔中的每个特征映射(用于检测特定大小范围内的对象)主要或甚至完全由骨干的单层构造,即主要或仅包含单层信息,金字塔中的每个特征映射(用于检测特定大小范围内的对象)主要或仅由单层特征组成,将导致次优检测性能

总结:M2Det首先融合来自不同尺度的backbone的特征图,然后经过若干个U-shape模块编码解码,最后收集所有U-shape模块解码器的所有特征图按照size相同的原则组装在一起形成FPN用于目标检测。
作者主要描述M2Det的设计引入了3个模块
- FFM:用于backbone的不同size的特征图的融合
- TUM:
- SFAM:
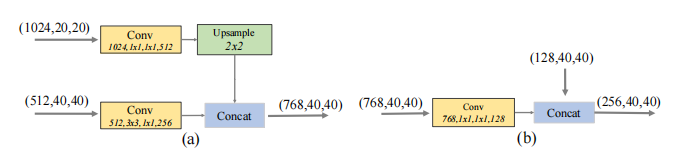
FFM模块:
从图中可以看出不同尺度的特征图是如何融合的:
小特征图进行上采样 然后与大特征图 进行channel concat
(a)是FFMa
(b)是FFMb
TUM模块

不同于FPN,TUM采用较薄的U型结构,如图所示。4©。该编码器是一系列具有stride = 2的3x3卷积层。解码器将这些层的输出作为其特征映射的参考集,而原始的FPN选择网主干网中每个阶段的最后一层的输出。此外,在解码器分支进行上采样和元素和操作后,添加1x1卷积层,提高学习能力,保持平滑性。每个TUM的解码器中的所有输出都形成了当前级别的多尺度特征。总体上,堆叠TUM的输出形成多层次多尺度特征,前TUM主要提供浅层特征,中间TUM提供中层特征,后TUM提供深层特征。
使用stride = 2的conv进行下采样
那么是使用什么进行上采样的呢?
得看了代码再来学习总结。。
SFAM模块
这个模块就是将若干个Unet输出的不同size的特征图收集组合在一起形成FPN

SFAM模块首先是将相同size的特征图收集起来在channel上进行cat,然后使用一个SE模块提高channel注意力使得特征更加有效。
M2Det的Pytorch代码学习
在这里插入代码片















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









